谷歌提出新型自动语音识别数据增强大法,直接对频谱图“动刀”,提升模型表现
2019-04-28 16:24:27爱云资讯
每次用语音输入完成“打字”过程,你的手机就经历了一次自动语音识别(ASR)。

这种已经无处不在的音频转录成文本的技术,在缺乏足够大的数据集,模型过拟合严重。因此当前如何去扩增音频数据是个大问题。
谷歌大脑在最新的一篇博客中,提出了一种用于ASR中扩增数据的新方法:SpecAugment。
和之前的研究画风有些不同,这一次,谷歌将这个问题当成了视觉问题而非音频问题。SpecAugment没有像传统扩增方法一样增加音频波形,而是将扩增策略直接应用于音频频谱图。
谷歌表示,SpecAugment方法简单,计算成本低,并且不再需要其他额外数据,在ASR任务LibriSpeech 960h和Switchboard 300h上,这种扩增方法效果惊艳。
不信接着看。
音频波形图
在传统的ASR任务中,在将训练数据输入到神经网络前,通常先通过剪裁、旋转、调音、加噪等方式先对输入的音频数据进行增强,然后再转换成频谱图等视觉表示。因此,每次迭代后,都有新的频谱图生成。
在谷歌的新方法中,研究人员将研究重点放在了扩增频谱图本身的方法上,并不针对声音数据进行改造,而是直接对频谱图等视觉表示进行增强。
因为扩增可以直接被应用于神经网络的输入功能上,因此可以在训练过程中在线运行,不会影响到训练速度。
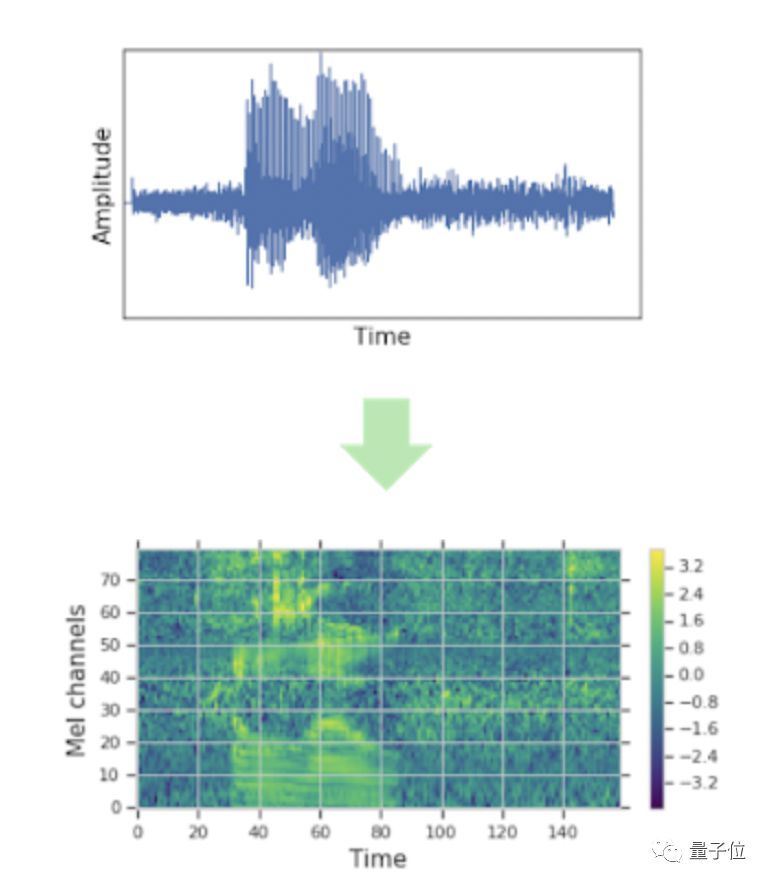
将声音数据转换成梅尔频率倒谱图,也就是基于声音频率的非线性梅尔刻度的对数能量频谱的线性变换
SpecAugment通过时间方向上的扭曲改造频谱图,及时修改、屏蔽连续频率频道块和语言频道块。这种扩增方式能让神经网络更强健,帮助抵抗时间方向上的变形,也会防止频率信息和语音片段信息丢失。
下图就是这种扩增策略的示例图:
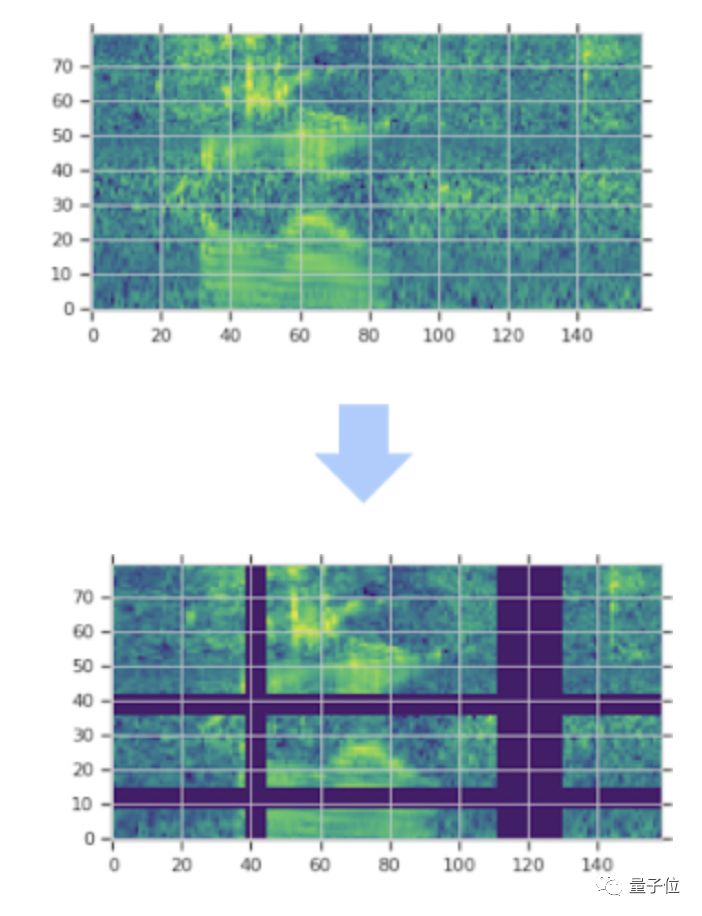
图中紫色区域为被屏蔽的部分可以看出,通过在时间方向上进行扭曲,外加屏蔽多个连续时间步长(垂直方向屏蔽)和梅尔频率频道(水平方向屏蔽),能有效扩增数据频谱图。
词错率降5%
这种方法的效果如何?研究人员在实验基础上进行了一系列实验。
研究人员限用大型开源语音识别数据集LibriSpeech上进行实验,比对模型生成的文字与目标文字的差异。他们选取了端对端谷歌语音识别神经网络框架Listen, Attend and Spell(LAS),比较了使用SpecAugment扩增数据与不使用情况下训练出网络的性能。
在此实验中采用控制变量法,所有超参数都保持不变,只改变输入到网络的数据,用转录过程的词错率( Word Error Rate,WER)来衡量结果。
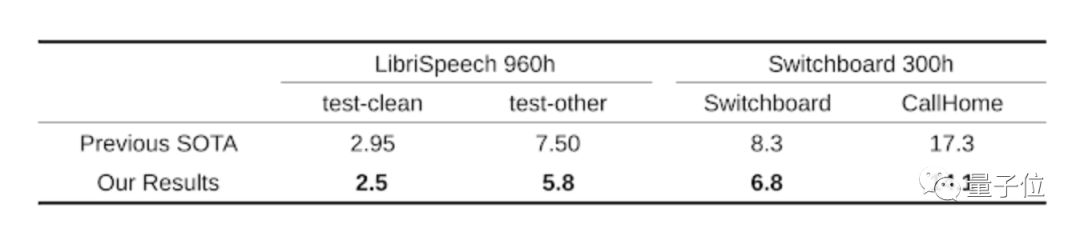
结果发现,在LibriSpeech数据集上,SpecAugment扩增方法能明显降低词错率。模型大小的不同对结果影响不大,平均词错率大致降低5%。
扩增数据后的词错率(蓝色)与无扩增数据的词错率(黄色)除了降低词错率,SpecAugment还能有效防止神经网络过拟合。
对训练数据、清洁数据和嘈杂数据的扩增结果研究人员增加了网络容量,在LibriSpeech 960h和Switchboard 300h任务上检测模型词错率,发现用SpecAugment扩增数据过后可获得当前最优结果。
- 多模态成新“时尚” 谷歌OpenAI万兴科技等出奇招探索多模态能力及应用
- 谷歌将探索AI写作,小美AI城惊艳亮相:AI世界中挑战与机遇并存
- 妙鸭相机海外同款火了 万兴科技旗下“Pixpic”登陆谷歌商店
- 谷歌开发者大会带来升级版Starline,微美全息推进3D显示+全息技术引领新高潮
- TalentOrg携手谷歌、爱点击,共探全球化发展策略
- 谷歌翻译现支持翻译图片内文字
- 谷歌折叠手机Pixel Fold首次在街头被发现
- 中国版“ChatGPT”真的来了,百度、微软、谷歌谁能突围?
- 谷歌Pixel Fold最新外观细节曝光:内外屏参数变化 相机模组造型熟悉
- 传音与谷歌建立全球战略合作伙伴关系,共推新兴市场数字化发展
- Poly博诣多款产品获谷歌及微软认证 加持混合办公生态
- 谷歌明年推8Gbps宽带服务 上行也不限速
- 谷歌Pixel 6a全球定价公布 新晋中端机7月21日开始发货
- Android 13亮相谷歌I/O大会,OPPO首批推出开发者预览版
- 谷歌收购数据科学公司Kaggle增强机器学习和AI业务
- 谷歌 Pixel 6 拆解,FD-SOI首次被用于5G毫米波





