准确率高达96.04%!阿里开源自研语音识别模型 DFSMN
2019-06-10 14:23:18爱云资讯
近日,阿里巴巴达摩院机器智能实验室开源了新一代语音识别模型DFSMN,将全球语音识别准确率纪录提高至96.04%(这一数据测试基于世界最大的免费语音识别数据库LibriSpeech)。
对比目前业界使用最为广泛的LSTM模型,DFSMN模型训练速度更快、识别准确率更高。采用全新DFSMN模型的智能音响或智能家居设备,相比前代技术深度学习训练速度提到了3倍,语音识别速度提高了2倍。
语音识别模型 DFSMN
授权协议:MIT
开发语言:C/C++
操作系统:跨平台
GitHub地址:
https://github.com/tramphero/kaldi
语音识别技术一直都是人机交互技术的重要组成部分。有了语音识别技术,机器就可以像人类一样听懂说话,进而能够思考、理解和反馈。近几年随着深度学习技术的使用,基于深度神经网络的语音识别系统性能获得了极大的提升,开始走向实用化。基于语音识别的语音输入、语音转写、语音检索和语音翻译等技术得到了广泛的应用。
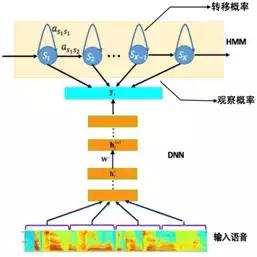
目前主流的语音识别系统普遍采用基于深度神经网络和隐马尔可夫(Deep Neural Networks-Hidden Markov Model,DNN-HMM)的声学模型,其模型结构如图所示。声学模型的输入是传统的语音波形经过加窗、分帧,然后提取出来的频谱特征,如 PLP, MFCC 和 FBK等。
而模型的输出一般采用不同粒度的声学建模单元,例如单音素 (mono-phone)、单音素状态、绑定的音素状态 (tri-phonestate) 等。从输入到输出之间可以采用不同的神经网络结构,将输入的声学特征映射得到不同输出建模单元的后验概率,然后再结合HMM进行解码得到最终的识别结果。
据了解,DFSMN模型就是在国际声学会议 ICASSP 2018 上做oral报告的 DFSMN(深度前馈序列记忆网络)。DFSMN使用基于BLSTM的统计参数语音合成系统作为基线系统,采用广泛使用的跳跃连接技术,在执行反向传播算法时,梯度可以绕过非线性变换。
著名语音识别专家,西北工业大学教授谢磊表示:“阿里此次开源的DFSMN模型,在语音识别准确率上的稳定提升是突破性的,是近年来深度学习在语音识别领域最具代表性的成果之一,对全球学术界和AI技术应用都有巨大影响。”
- 拼多多:去年赚了600亿,市值赶超阿里
- 阿里达摩院院长、知乎创始人等多位大咖力荐,国内首本AIGC金融应用著作首发
- 阿里全面拥抱鸿蒙,旗下热门应用将推出鸿蒙版
- 阿里旗下新增11款应用启动鸿蒙原生应用开发
- 阿里云和蚂蚁数科合作开发的实人认证产品适配华为HarmonyOS NEXT
- 阿里巴巴CEO吴泳铭:通义千问正加快追赶 GPT-4
- 2024国际元宇宙博览会:阿里元境以元宇宙数字内容助力文旅数字化发展
- 联合阿里云,首批诚邀 30 家!Alibaba Cloud Linux 伙伴招募计划发布
- 阿里云“云创月汇,数智营销Go!”开启,带你玩转数字化营销
- 安徽文交所、田园东方与阿里资产共同成立长三角乡村文旅资产交易服务中心
- 阿里钉钉与华为达成合作,正式启动鸿蒙原生应用开发
- MongoDB和阿里云携手驱动WeLab,引领超千万用户迈向智能金融未来
- 阿里云能耗宝:助力企业算碳节能
- 阿里巴巴“AI驱动”战略提速 夸克发布自研大模型
- 云栖大会:阿里元境抢抓新一轮科技创新机遇,夯实元宇宙发展基础
- 运用科技手段讲好历史故事,阿里元境与西安博物院联手打造元宇宙展馆