机器学习的金融应用第三讲:算法的性能评估及过拟合
2021-09-23 15:32:07爱云资讯
机器学习算法能够发现特征变量与目标变量之间复杂的关系,并且可以快速处理大量数据。此外,许多机器学习算法可以轻松捕获非线性关系,并且能够识别和预测特征与目标之间的结构变化。这些优势主要来自非参数和非线性模型,这些模型在推演关系时具有更大的灵活性。
但是,机器学习算法的灵活性也存在缺陷。机器学习算法有时会生成过于复杂的模型,其结果难以解释;模型可能会对数据中的特定变化非常敏感,或者只能很好地拟合训练数据。
很好拟合训练数据的机器学习算法通常不能对新的测试数据作出精确预测。这个现象称为过拟合,过拟合算法不能很好地推广应用到新的数据中。泛化效果好的模型是指在预测样本外(即新数据)仍旧有很好解释力的模型。
过拟合模型将训练数据中的噪声或随机波动纳入了其学习中。这些噪声不适用于任何新的数据,会对模型的概括能力产生负面影响。因此,任何机器学习算法的评估都将重点放在对新数据的预测误差上,而不是对训练数据的拟合优度。
泛化是模型构建的目标,因此过拟合的问题是实现该目标的挑战。这两个概念是下面讨论的重点。
泛化和过拟合
为了正确地描述机器学习模型的泛化和过拟合,重要的是要注意模型对数据集的划分。数据集通常分为三个不重叠的样本:1)用于训练模型的训练样本;2)用于验证和调整模型的验证样本;和3)用于测试模型对新数据预测的能力的测试样本。训练样本通常被称为“样本内”,而验证和测试样本通常被称为“样本外”。
为了确保有效性,任何有监督的机器学习模型都必须推广到训练集之外。当进行样本外测试时,模型应保留其解释力。如前所述,无法解释样本外数据的一个常见原因是过拟合。过拟合可以视为我们定制了一件仅适合一个人的西装;欠拟合类似于制作了不合身的宽松西服,而良好拟合类似于打造了一件适合所有人群的通用西服。
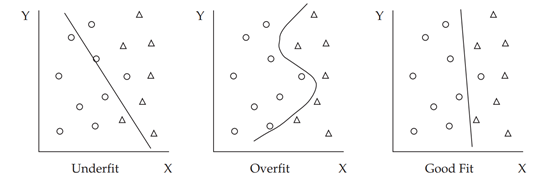
下图说明了欠拟合、过拟合和良好拟合的概念。欠拟合意味着模型无法捕获数据中的关系。左图显示了该欠拟合模型中的四个错误(三个错误分类的圆和一个错误分类的三角形)。过拟合是指将模型训练到对于训练数据十分精确,以致该模型揉合了虚假的相关性噪声。该算法虽然分析了数据,但并没有从中学习,因此它具有良好的后见之明,但没有先见之明。因此,数据中的高噪声水平也变成了过拟合的主要因子。中间的图显示此过拟合模型中没有错误出现。复杂度是指模型中的特征的数量,以及模型是线性的还是非线性的(非线性更为复杂)。随着模型变得越来越复杂,过拟合的风险会增加。良好拟合的模型可以很好地拟合训练数据,并且对样本外数据也有很好的泛化效果,两者均在可接受的误差范围内。右图显示,良好拟合的模型只有一个错误,即错误分类的圆圈。
错误和过拟合
为了对拟合度进行校准,数据专家将样本内和样本外的错误率作为数据和算法的函数进行比较。总样本误差(Ein)是对于训练样本上实际目标结果的拟合关系预测生成的。总样本外误差(Eout)来自验证样本或测试样本。样本内误差很小或没有,但样本外误差很大,表明泛化性差。数据专家将总的样本外误差分解为三个来源:
-
1、偏差误差,即模型对训练集的解释程度。如果算法的假设是错误的,会导致结果拟合度不足,样本内误差也较高。
-
2、方差误差,即模型对验证和测试集中新数据的解释程度相对于训练集的差异。不稳定的模型会吸收进噪声,产生高方差,从而导致过拟合和较高的样本外误差。
-
3、基本误差,由于数据中的随机性导致的错误。
学习曲线描述的是验证或测试样本(即样本外)中的准确率(=1–错误率)与训练样本中的准确率,是描述欠拟合和过拟合的偏差和方差误差的函数。如果模型是有用的,则随着训练样本大小的增加,样本外的准确度也会提高。这说明在验证或测试样本(Eout)中和训练(Ein)样本中彼此的错误率非常接近,并朝着期望的错误率(基本误差)收敛。如下图左图所示,在具有高偏差误差的欠拟合模型中,高误差率会导致收敛低于所需的准确率。添加更多的训练样本不会改善模型。如下图中间图所示,在具有高方差误差的过拟合模型中,验证样本和训练样本的错误率无法收敛。在构建模型中,数据专家试图在选择具有良好预测或分类能力的算法的同时尽量减少偏差和方差,如下图右图所示。

样本外错误率也是模型复杂度的函数。随着训练集复杂度的增加,错误率(Ein)下降,偏差误差减小。但是,随着测试集复杂度的增加,错误率(Eout)上升,方差误差也上升。
通常,线性函数更容易受到偏差误差和拟合不足的影响,而非线性函数则更易产生方差误差和过拟合的现象。因此,当偏差和方差误差曲线相交时,模型复杂度最佳,样本内和样本外误差率最小。拟合曲线如下,该曲线在y轴上显示了样本内和样本外错误率(Ein和Eout),相对应的x轴上显示了的模型复杂度。

找到总错误率开始上升之前的最佳点是机器学习过程的核心部分,也是成功实现模型应用的关键。数据专家将过拟合和泛化之间的权衡叫做成本(样本内和样本外错误率之差)与复杂度之间的权衡。他们利用成本和复杂度之间的权衡来校准欠拟合和过拟合,并优化模型。
- 适应快速变化的业务需求,人工智能/机器学习将为 DevOps 注入全新活力
- 为机器学习领域带来创新突破,微美全息将多级相关学习技术运用于多视图无监督特征选择
- ManageEngine卓豪|利用机器学习和AI优化自助服务的5种方式
- 微美全息利用机器学习的智能推荐技术,开发多模态融合推荐系统
- 快速玩转 Llama2!阿里云机器学习 PAI 推出最佳实践
- 引领高质量图像处理的创新发展,微美全息研发机器学习的多焦点图像融合技术
- 九章云极DataCanvas公司7次蝉联中国机器学习平台市场三甲
- 人工智能加速落地赋能千行百业,微美全息赋能AI+机器学习算法迎来空前发展机会
- NLP领域再创佳绩!阿里云机器学习平台 PAI 多篇论文入选 ACL 2023
- 什么是MLOps?为什么要使用MLOps进行机器学习实践
- 阿里云机器学习平台PAI论文入选 SIGMOD 2023
- 如何通过人工智能(AI)和机器学习应对零售劳动力和执行方面的挑战
- 时序数据库DolphinDB基于机器学习的异常预警方案
- 机器学习平台PAI支持抢占型实例,模型服务最高降本90%
- 微美全息开发基于人工智能和机器学习的图像处理技术
- 阿里云机器学习PAI发布基于HLO的全自动分布式系统 TePDist,并宣布开源!