百度15篇论文被AAAI 2019 收录 受邀参加人工智能界年度顶级会议
2019-01-28 16:30:22爱云资讯
1月27日,第33届AAAI(AAAI 2019)在美国夏威夷召开。本届大会百度共有15篇论文被收录,多位百度重量级科学家、研究者受邀赴会作演讲。在现场,百度作为金牌赞助商,还将通过展台宣传、Job Fair宣讲等方式,进一步向全球展示百度AI技术全面的发展。不论是领先的技术成果还是在学术界扎实的基础,百度都在靠实力赢得全球业界越来越多的认可。

“产学”软硬结合 展示百度AI雄厚实力
AAAI于1979年成立,是国际人工智能领域的顶级国际会议。这一协会如今在全球已有超过6000名的会员,汇集了全球最顶尖的人工智能领域专家学者,一直是人工智能界的研究风向标,在学术界久负盛名。
本届大会共收到7700余篇有效投稿,其中7095篇论文进入评审环节,最终有1150篇论文被录用,录取率为近年最低仅为16.2%。百度在含金量如此高的会议上,共获得15篇论文被收录的成绩。其中有5位作者受邀在主会做Oral形式报告,另有10位作者将携论文在主会以Spotlight Poster形式做报告。这不仅在百度参会历史上创新高,在国内巨头中也是非常领先。
收录论文覆盖领域丰富 涉及智能出行、无人驾驶、NLP
在百度此次收录的15篇论文中,内容更是涉及包括智能出行、机器学习、视频建模、无人驾驶、自然语言处理、智能医疗等多个领域。
自然语言处理领域。百度这次被AAAI收录的论文《Modeling Coherence for Discourse Neural Machine Translation》,提出了一种篇章级别的翻译模型,能够使得篇章内的句子之间保持良好的连贯性和一致性。这是由于翻译一些文档、演讲之类的文本时,通常需要虑句子之间的衔接性和连性。而传统的翻译模型通常都是将一个句子当做单独的翻译单元,忽视了句子之间的关联性。具体来说,该论文提出了一种多轮解码方案,在第一轮解码中单独生成每个句子的初步翻译结果,在第二轮解码中利用第一轮翻译的结果进行翻译内容润色,并且提出使用增强式学习模型来奖励模型产生篇章更一致的译文。最终在演讲文本的测试集合上,论文提出的模型不仅能够提升句子级别1.23 BLEU值,同时能够提升篇章级别 2.2 BLEU。通过实验分析,本文提出的翻译模型确实能产生篇章更加连贯和一致的句子。
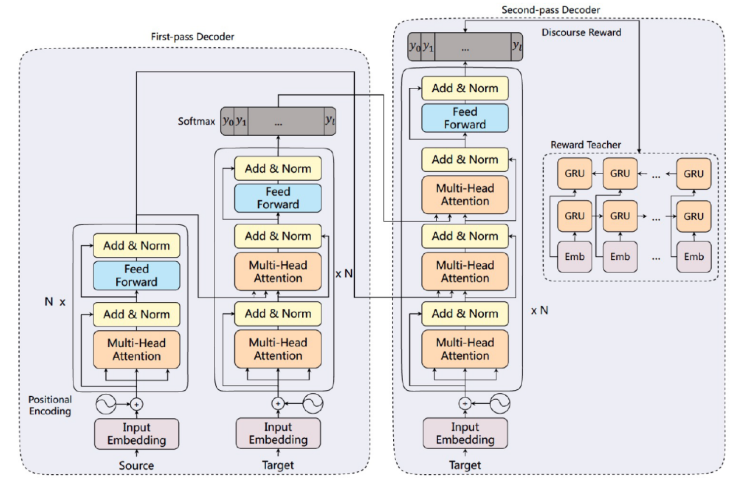
据悉,此模型是基于Transformer模型设计的。首先,训练流程中的一个batch为一篇文章中的所有句子,在第一轮解码中,采用标准的Transformer模型生成单个句子的初步翻译结果。在第二轮解码中,将第一轮产生的译文合并成一个句子,构成此篇章翻译的参考译文。同时将初步翻译结果作为一个额外的Multi-Head Attention机制,加入到Decoder的解码流程中。通过这个步骤,在第二轮解码的过程中,在翻译单个句子时,能够考察其他句子可能产生的翻译结果,进而调整当前句子的文本输出概率,尽量使得翻译结果更一致。最终利用Self-critical的学习机制,鼓励模型生成篇章一致性的译文。值得一提的是,不仅仅是第二轮解码中可以使用增强式学习机制,在第一轮解码中也可以鼓励模型产生更一致的译文。
本文首次在学术和工业界提出解决神经网络翻译中的篇章一致性和连贯性问题,并且提出了一种通用的解码框架,通过多轮解码和增强式学习策略,使得模型能产生良好的篇章连贯和一致性的译文。同时,本文还提出了若干评估篇章连贯和一致性的评价方法,有利于促进相关的研究工作发展。
目前的在线翻译引擎基本都是针对单个句子进行解码翻译,并不能保证一篇文章翻译出来后句子之间有很好的连贯性,采用本文提出的方法,能够使得篇章级别的翻译文本阅读起来更流畅,句子之间的连贯性更好。
无人车驾驶领域。为了能在复杂的城市交通中安全有效地行驶,无人车必须对周围交通体(机动车,自行车,行人等等)的行为轨迹做出可靠的预测。一个十分重要又具有挑战性的任务就是探索各种各样的交通体的不同的行为特征并能对它们做出及时准确的预测,进而帮助无人车做出合理的行驶决策。为了解决这个问题,《TrafficPredict: Trajectory Prediction for Heterogeneous Traffic-Agents》的作者提出了基于LSTM的路径预测算法TrafficPredict。他们的方法是用实例层来学习个体的运动规律和它们之间的交互,用类别层来学习同一类别的个体的运动的相似性,从而进一步优化对个体的预测结果。
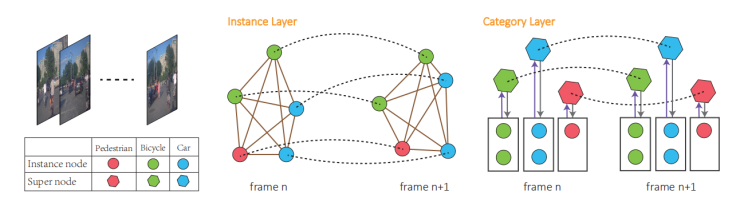
他们采集了一个复杂路况下的交通数据集,正常行驶的汽车通过Lidar采集的连续帧数据经过标注得到。问题设定为观察交通体[0 : Tobs]时间段内的运动轨迹,预测 [Tobs + 1 : Tpred]的运动轨迹。对于一个时间段的数据,首先把数据组织成一个4D Graph. 这个Graph包含两个层,一个是实例层,一个是类别层。在实例层中,每一个个体看成一个节点,每一帧中个体之间通过边连接,相邻帧的同一个体也通过边连接。在类别层中,同一帧中相同类别的个体把信息汇总到一个超节点中,超节点会总结经验,进而反向改善每一个个体的预测结果,相邻帧的同一个超节点也通过边连接。4D graph通过边捕捉个体在空间上的交互信息,在时间上的连续信息,和在类别上的相似信息,通过节点和超节点汇总和分析这些信息。
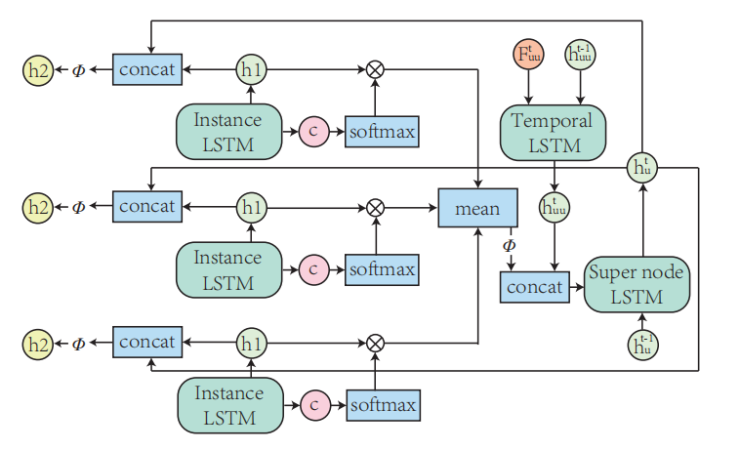
本文提出的方法把多类别交通体的路线预测统一到一个框架之下,通过构建空间和时间维度上的4D graph,充分利用交通体自身的运动模式和与周围交通体交互的信息,并通过超节点总结概括同类别运动相似性来改善个体的结果,从而对每个交通体的轨迹预测精度有了较大提高。另外,本文还发布了多类别体的复杂城市交通的路线数据集。
目前自动驾驶的测试场景都是比较规则和简单的交通场景:有清晰的车道线,红绿灯,交通参与体比较单一。但是,很多城市交通,比如中国或印度的城市交通,具有很高的复杂度。尤其在一些十字路口,自行车,三轮车,汽车,公交车交互前进。本文针对多类别体城市交通提出的的路径预测算法,为无人车在复杂交通场景下的导航提供了更为精确的指导,进而可以提升自动驾驶系统的安全性。
视频建模。深度学习在静态图像理解上取得了巨大成功,然而高效的视频时序及空域建模的网络模型尚无定论。不同于已有的基于CNN+RNN或者3D卷积网络的方法,《StNet: Local and Global Spatial-Temporal Modeling for Action Recognition》 一文提出了兼顾局部时空联系以及全局时空联系的视频时空联合建模网络框架StNet。
具体而言,StNet将视频中连续N帧图像级联成一个3N通道的“超图”,然后用2D卷积对超图进行局部时空联系的建模。为了建立全局时空关联,StNet中引入了对多个局部时空特征图进行时域卷积的模块。特别地,我们提出了时序Xception模块对视频特征序列进一步建模时序依赖。在Kinetics动作识别数据集的大量实验结果表明,StNet能够取得State-of-the-art的识别性能,同时StNet在计算量与准确率的折衷方面表现优异。此外实验结果验证了StNet学习到的视频表征能够在UCF101上有很好的迁移泛化能力。

StNet提出了局部和全局时空联系联合建模的概念,能得到更具判别力的视频表征,有效的提高视频动作识别的性能。同时,StNet的设计兼顾了计算量与识别准确率的折衷,具有很好的实用价值。StNet作为一个backbone网络结构,可以应用在用video2vector、视频识别等方面。
本届AAAI 2019大会,百度多篇论文的集中收录,不仅为业界培养了诸多有突出贡献的研究人员,也在全球范围内彰显着百度AI技术的雄厚实力。人工智能发展任重道远,需要举全行业之力、全球之力攻坚克难,以期在学术、产业上迎来突破时刻。
- 百度文库官宣「AI创作」体验官李雪琴,带来AI办公提效新范式
- 苹果携手百度共探AI合作新机遇,微美全息竞速开展AIGC应用构建竞争优势
- 软通动力荣获百度智能云“大模型创新突破奖“等荣誉
- 数势科技副总裁宋丽出席百度智能云GENERATE全球生态大会,共商大模型生态
- 为新质生产力“添柴加薪”,呼和浩特与百度共建人工智能基础数据产业基地
- 百度教育行业AIGC营销解决方案全新升级,为客户打造全场景“明星员工”
- 第七届智慧高校CIO上海论坛召开,百度文库荣获“智慧教育大模型应用创新奖”
- 百度AI技术赋能,极越汽车机器人引领智能汽车3.0时代
- 外媒称苹果与百度就AI合作谈判 为iOS 18系统加入本土AI做准备
- 百度国际MediaGo联合GeoEdge持续打击恶意广告
- 携手中经数据,百度文库深耕一站式AI内容创作
- 2023哪些AI应用最受用户喜爱? OpenAI百度万兴科技旗下产品上榜
- 百度营销发布「生成商业新未来」特刊
- 小度推出龙年首个大模型AI年宠,基于百度文心大模型生成
- 用科技关爱老人和小孩 百度为大凉山村民送上手机、智能屏、随身音箱等
- 百度网盘推出AI春节活动,几秒生成龙年写真、一键获得自家宠物表情包