“善解人意”的手机相机:从人像模式和Google Lens谈起
2019-02-22 16:05:59爱云资讯
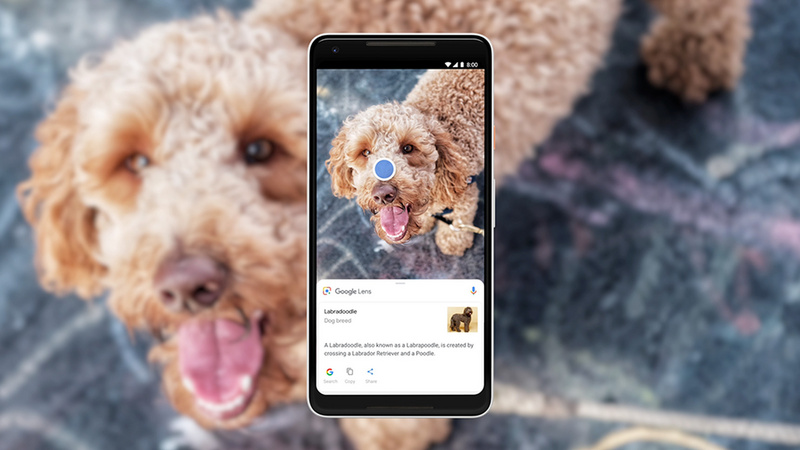
关于机器学习和计算机视觉技术带来的影响,我已经谈了很多,比如电子商务推荐到社交应用,再到各种很酷的工业应用等等。现在来看看机器学习对智能手机相机的影响,也挺有趣。
对于苹果和谷歌来说,智能手机上摄像头的大部分技术进步,都发生在软件上。
这方面的营销术语是“计算摄影”,这实际上意味着,除了努力制造更好的镜头和传感器(受物理规则和手机大小的限制)之外。
我们还在使用软件(现在大多是机器学习技术或“人工智能”),试图从来自硬件的原始数据中获得更好的图片。
因此,苹果在双镜头手机上推出了“人像模式”(portrait mode) ,使用软件将这些数据组合成一张重新聚焦的图像,现在,它在单镜头手机上也推出了这一功能(谷歌复制这一功能时也是如此)。
同样,谷歌的新款Pixel手机具有“夜景”功能,这完全是一个软件功能,而不是使用了完全不同的硬件。你看到的图片的质量,因为新的软件和新的硬件推出而变得更好。
大多数这样的变化,用户都看不到。HDR从一个花哨的新事物变成了智能手机相机中的一个设置。现在,这个设置变成了自动化的,它出现的时候,你可能不知道,也不需要知道。
我预计,单独的“人像模式”或者“夜景”功能的选项也将会消失,就像HDR一样。
随着相机能够更好地计算出你实际拍摄的照片,这种自动化情况可能还会更进一步。
当你在滑雪坡道上拍照时,相机会完全曝光,色彩平衡,因为相机知道这是雪,并且能够准确调整相应设置。
如今,人像模式正在进行人脸检测和深度映射,以确定应该关注什么;将来,它会知道照片哪张脸是你的孩子的,并将焦点聚焦在他们身上。
因此,我们显然正朝着普通消费者拍摄的照片在技术上都很完美的方向前进。
然而,这里还有第二个步骤——不仅仅是“这张照片是什么,我们应该如何聚焦?”但是“你为什么拍这张照片?”
智能手机相机的一个理想进化路径是,因为我们一直随身携带着手机,我们可以免费拍摄无限的照片,并且可以立即得到它们,我们不仅会拍摄更多关于孩子和狗的照片,还会拍摄以前从未拍摄过的照片。
我们会拍摄海报、书籍和我们可能想买的东西——我们拍摄食谱、目录、会议日程、火车时刻表和传单。智能手机上的图像传感器已经变成了一个记录的笔记本。
机器学习技术的应用,意味着计算机将能够解开很多这种照片中的东西。
如果这张照片上有一个日期,那会意味着什么?这看起来像食谱吗?这张照片里有一本书吗?我们可以把它和亚马逊上的书目对比一下吗?
所以你可以想象,你的智能手机上会有这样的一个建议:“你想把这张照片中的日期添加到你的日程中吗?”就像今天电子邮件程序从电子邮件中提取航班、会议或联系方式一样。
这是一个有趣的产品设计挑战。其中一些功能可能是被动的,比如在电子邮件中自动检测航班。
机器学习意味着我们现在有了面部识别和物体分类技术:默认情况下,你手机上的每张图片都有索引,你可以要求找出“我儿子在海滩上的所有照片”或者“所有关于狗的照片”。
但你可以做更多的分析,而且我们拍了很多照片,你可以在所有这些照片中分析一些东西。
你也许可以索引或翻译你拍摄的所有照片中的所有文本(假设没有资源限制),但是你应该对手机上每张照片中的每一个对象进行相应的搜索吗?
在某个时候,你可能需要某种“告诉我这个是什么”的功能,在这种情况下,你会明确要求计算机施展“魔法”。
不过,要求计算机“告诉我这张照片是什么”也带来了其他的问题。
我们没有HAL 9000,也没有任何通向HAL 9000的路径,我们不能随意识别任何物体,但是我们可以在很多物体类别中做出不同程度的猜测。
那么,用户应该如何知道什么会起作用,以及系统如何知道要做什么样的猜测呢?这一切应该发生在一个通用的应用程序中,还是发生在许多有特定用途的应用程序中?
你是否应该有一个“海报模式”,一个“求解这个方程式”模式,一个“日期模式”,一个“书籍模式”和一个“产品搜索模式”吗?
或者,你是不是应该有一种模式,在这种模式下,用手机的摄像头拍一些东西,然后“魔法”就会发生?
最后一个,正是谷歌在“Lens”产品中使用方法,它被集成到安卓相机应用程序“人像模式”旁边——大多数情况下,把摄像头对准事物,魔法就会发生。
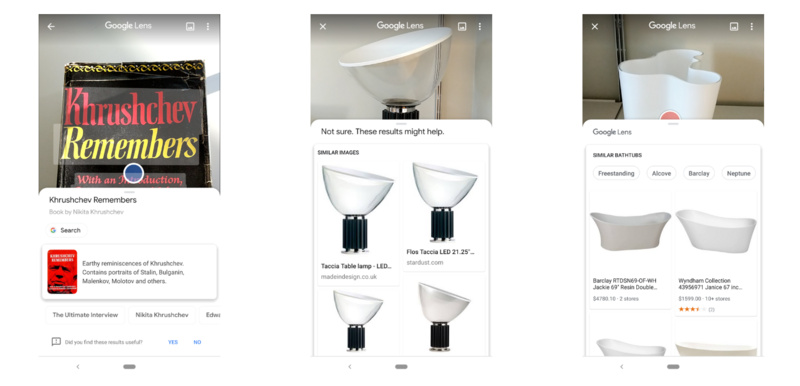
左:识别正确;中:识别正确;右:识别错误。
这三个截图,实际上显示了很多的活动的部件:
在第一种情况下,文本被识别出来(可以复制它) ,然后书籍本身被识别出来(通过文本还是图像不太确定?) ,而且,Lens还提供了一个产品匹配。 成功。
在第二种情况下,应用程序没有识别出来物体是什么,照片被传递到谷歌进行图像搜索,在一些网页上找到了匹配,但谷歌不知道这到底是什么。
从消费者的角度来看,这是可行的,但是没有相关的知识图表。
第三,应该是一个高度可识别的产品(一个花瓶,Alvar Aalto vase)。但是拍摄角度与网站上的图片不匹配,但谷歌的对象检测功能认为它是一个独立的浴缸。
如果我手动将图片输入到谷歌图片搜索中,它会显示为“俱乐部椅子”。 (从技术上讲,手机也许能够计算出这个物体有多大,用它能做些什么,但这可能要等到明年了。)
这些例子都说明了技术的发现能力和用户期望的问题。它能做什么,我不应该期望它做什么,当你没有得到一个好的反馈结果时,你应该如何处理?
事实上,这也是语音助手面临的挑战的另一个表现,它们可以做各种各样不同的事情,以至于你不想给用户一个所有功能的列表,不过,它也没法处理你遇到的所有事情。
但你会期望它能够处理你扔给它的任何事情。那么,你如何与它建立沟通,发现你的人工智能系统都能做什么呢?
在这里的第二个例子中,谷歌失败了,然后使用谷歌图像搜索,语音助理有时会重新检索谷歌网络搜索排名最高的结果。在这里,这种策略奏效了。
在第三个例子中,谷歌很有信心(直接进行产品搜索,而不是图像搜索),但是错了——我应该如何处理这种情况?没有比这更好的建议了吗?
如果它没有找到第一个例子中的那本书,我可能会失去对这款产品的尊重,但是我知道,想要匹配这个花瓶要困难得多,所以我能理解为什么,在计算机看来花瓶会像一个浴缸。
相反,我怀疑Siri面临的问题之一,是苹果在营销中给人传递的印象——你可以问它任何事情。但事实是,消费者的期望与产品的能力不匹配。
从某种意义上来说,这些问题也是品牌问题。我们知道,Shazam可以用来识别音乐。亚马逊的应用程序可以提供关于Krushchev的书的更好的匹配结果,它给出的不是像谷歌给出的现代再版,而是同一封面的版本。
但是,它在灯和花瓶上完全失败了,尽管它们都在亚马逊上出售。我应该对亚马逊有不同的期望吗?我应该希望人工智能有多聪明?
另一种方法,就像Shazam一样,采用针对特定任务的应用程序。 假设有一个应用程序,只需要你拿着摄像头对着书中的食谱,它会生成一个购物清单,或者可能会给你提供营养信息。
你可以让它变得非常可靠,你也不会有“人工智能可发现性”的问题,但是这个应用本身就会有可发现性的问题(即使是来自谷歌)——人们怎样才能发现它呢?
不管怎样,这种方法对谷歌(或亚马逊)来说都不可行。
如果它们现在能识别50个类别,两年内能识别200个类别,那么它们在相机应用程序中不能内置200个应用程序或200个模式,就像它们在搜索页面上不能有200个模式一样。
你需要有一个通用的前端或使整个事情被动化或不可见,比如面部识别,HDR,或者把航班信息放到你的日历中。
语言翻译是这些可能的模式中的另一种,谷歌翻译目前也有自己的应用。谷歌翻译是一种可视化的Babelfish(一个自动化的免费机器翻译系统服务)。
这些问题想要解决,需要依赖的不是你口袋里放什么传感器,而是你佩戴有什么传感器。
比方说,五年之后,你可能会买一副“眼镜”,它结合了透明的彩色3D显示器和一组图像传感器。
这些图像传感器描绘了你周围的空间,所以你可以让墙壁成为一个显示器或者在桌子上播放《我的世界》,但是它们也能识别出你周围的东西。
在这种情况下,我们根本不需要拍下照片来记录。
你不需要拍下会议日程——你只需看一下,然后在那天晚些时候说‘嘿,谷歌,下一个会议是什么?’或者问它,‘我上周在一次活动中遇见了一个人,他们的名牌上写着他他们为一家好莱坞电影公司工作——他们是谁?’
那么,我们会得到什么建议,你会记住什么么?你怎么知道眼镜能做什么(以及别人的眼镜可能在做什么)?这些品牌,如何平衡这些问题呢?它们又如何平衡隐私和信任呢?
- 连续六年散热技术迭代,控温大师2.0—— 飞智手机散热器B7X系列全网霸榜
- AI手机加速普及 三星Galaxy Z Fold5加入Galaxy AI功能
- 用华为云空间释放手机存储,春日出游随心拍
- 手机行业首批!OPPO正式入驻便民服务“小修小补”引路行动
- 一加Ace 3V挑战中端手机护眼冠军,成1.5K护眼直屏新标杆
- 艾睿光电首款无线手机红外热像仪发布!最远支持8米无线图传操作
- 荣耀Magic6系列旗舰手机发布,AI使能的全场景战略引领行业变革
- 2024手机市场回暖 传音布局AI成果显著
- 天玑9300影像旗舰机压倒8G3游戏手机蝉联榜首,天玑8300霸榜次旗舰排名
- MWC 2024:华为手机展现科技创新实力,持续强化高端科技品牌形象
- 推动手机卫星通信技术普及,联发科MWC2024带来惊喜
- 联发科天玑又领先一步!强悍AI手机芯片就看天玑!
- 天玑9300、天玑8300支持全球主流大模型,助力端侧AI手机应用落地
- 最好的《原神》游戏手机!ROG 8 Pro凰家评测再度“嚣张”虐榜
- 引领手机AI新风尚 三星Galaxy S24系列诠释AI时代旗舰体验
- 端侧AI持续强势,AI手机大势所趋