中科院自动化所王金桥:深耕AI中台引擎,助力AI场景化、多元化落地
2019-03-30 15:12:48爱云资讯
3月23日,「第二届中国人工智能安防峰会」在杭州召开。
峰会现场,王金桥教授以《AI中台引擎:连接、计算与赋能》为主题,阐述了目前视频系统存在的问题,以及AI中台引擎如何助力AI场景化多元化落地。
王金桥是国内知名计算机视觉与视频分析专家、中国科学院自动化研究所模式识别国家重点实验室研究员、同时作为中科视语董事长,对产学研的融合颇有心得。
王金桥指出,尽管智慧城市和智能安防的发展速度惊人,但其中仍然存在几大问题:第一、当前的视频系统组网复杂,难以维护,平台不兼容的问题仍然明显;第二、协议标准、数据标准不统一,设备的数据和编码分散,兼容性非常差;第三、存在大量的信息孤岛,无法统一管理;第四、AI芯片整体产能不足,分析效率有待提升。
“我们现有的数据,以及我们未来对焦的数据平台如何关联、如何引用,是现在能力发展所遇到的困难。所以未来就更需要这种开放式的AI平台。”基于此,王金桥教授提出了AI中台的概念。
“AI中台引擎,有一个重要组成部分“AI智能盒”,也就是一个“AI中间件”,可以一键安装实现多样化的设备连接,无缝兼容多样化的终端,简单来说就是能够连接一切视觉设备,同时通过AI中台引擎的连接,中间件将各种数据传到AI中台,便可实现AI与各种云端相结合,形成连接智能的作用”,王教授说。他希望无论是什么类型的视觉数据,中间件都能发挥“连接智能”的作用,在各种云端和AI相结合。其次,是希望中间件能够兼容硬件设备,并且对视频进行有效传输,打破信息孤岛,成为一个统一的协议出口。
王教授认为,2018年是AI落地元年,2019年将是场景化AI场景化规模化落地的开始。只有形成定制化的应用,满足用户的需求,才能把算法和数据有效结合,去解决细分领域、细分场景的问题,这才能够真正实现AI落地,实现百花齐放。
以下为王金桥的现场演讲内容,雷锋网作了不改变原意的编辑及整理:
前面很多嘉宾讲了一人一档、开放式平台,我想给大家分享的主题是《AI中台引擎》。我认为,在智慧城市等各个领域,AI起到的其实是中台引擎的作用,包含几个方面:连接、计算与赋能。
视频大数据现状
我们知道,视频数据正在呈爆发式增长。同时,5G和AI芯片的到来给视频数据的传输和计算增添了新的增长点,给未来城市级的安防和监控创造了许多新的产业机会。其中,AI起到的最重要的作用就是语义计算。

前面很多嘉宾讲到智慧城市的发展。其实,早在古代我们就开始了对城市的观察、监控和管理,并利用烽火台进行通讯。只不过,今天我们使用的技术已经发展到了第四代视觉计算。第四代视觉计算的目标是将过去的“被动式防御”变成“主动式预警”。
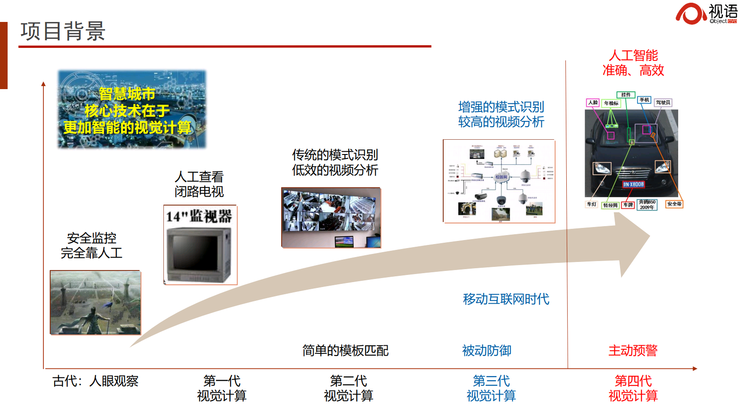
从“被动式防御”变成“主动式预警”就涉及到决策,而决策又涉及多种多样的任务和需求。
今天,我们视频系统的能力还存在许多不足:
第一、当前的视频系统组网复杂,难以维护,平台不兼容的问题仍然明显;第二、协议标准、数据标准不统一,设备的数据和编码分散,兼容性非常差;第三、存在大量的信息孤岛,无法统一管理;第四、AI芯片整体产能不足,分析效率有待提升。
这给我们做一个开放式的、AI赋能的平台带来了许多障碍。未来,如何将现有的数据和新增的数据进行关联和引用是我们需要解决的问题。
我们知道,2014年AI就在人脸识别上超过了人类,但直到2018年这项技术才大规模落地,而且当时主要用到的是1:1人脸比对。人脸识别技术的场景化经历了四五年,过程非常之艰难。但我认为,2019年将是AI场景化、规模化,或者说百花齐放的一年。AI将在社区、考勤、门店、终端等各个场景实现定制化。只有定制化的应用,才能把算法和数据有效结合,从而解决实际问题。

我们的“AI智能中台”中有个硬件,叫做中间件。我们希望来自不同设备的、不同类型的视觉数据,通过网口连接到这个中间件后,就能够在业务层和云端的AI相结合。它起到的是连接智能的作用。
中间件主要可以解决几个问题:一是开发的问题,不需要再针对现有的设备重新开发一套平台;二是能够兼容各种各样的设备,插入之后在云端打开一个网址就能看到所有我想要的东西;三是通过4G和5G将视频进行有效传输,打破信息孤岛;最后,我们希望这个中间件能够变成数据的统一协议出口,对接后面的AI中台。

我们的产品视接盒,它可以兼容目前大多数模拟和数字摄像机。无论何种编码格式的数据都可以在这里重新编码、定位和传输,无缝对接AI、4G、北斗等等。这是一个全新的硬件。
我们还提供视频汇聚中台,支持数据的定发、转发,将数据推到阿里云等各种业务应用场景。我们提供的解决方案主要面向智慧城市——包括车辆、人脸识别,智能制造、新零售等场景。其中,智能制造是工业史上的一个新命题。
目前,视频结构化或者说目标检测,依旧是一个非常难的问题,比如人的跨镜头追踪,在公开数据集中的准确率只有88%,还有很长的路要走。
我们希望我们的中台能够支持多任务联合计算。所谓多任务联合计算,就是说一个神经网络能够同时完成目标检测、场景解析和目标识别。
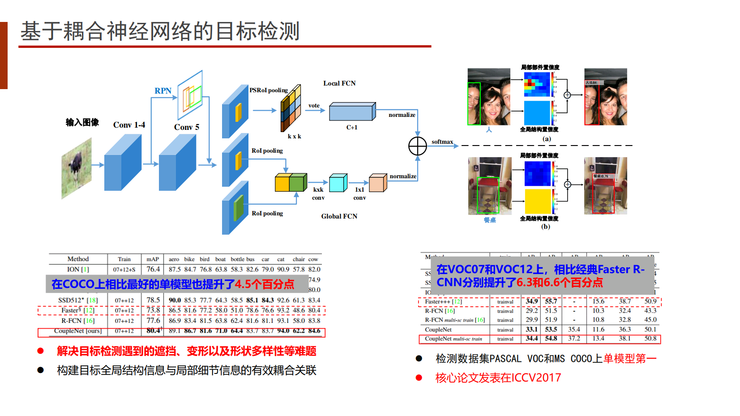
下图是我们去年参加无人驾驶竞赛的场景。在同一个模型上,我们能够同时解决可行驶区域的解析,人、车、物的结构化检测,还有车牌、车距和交通标志的识别。
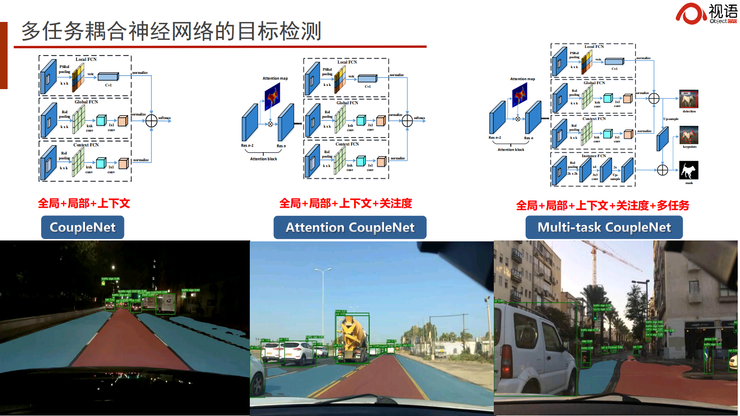
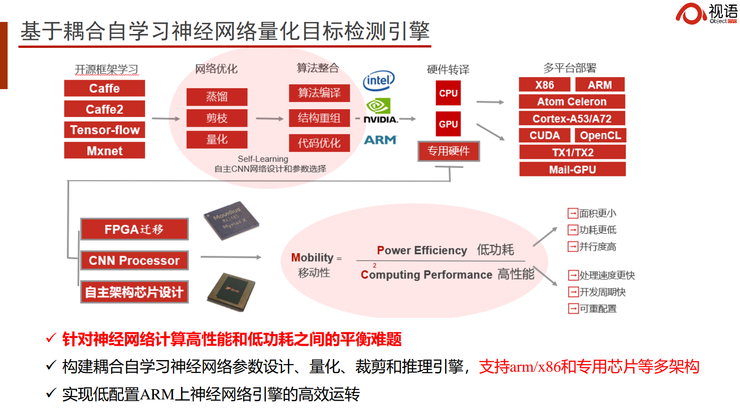
在这个任务中,我们使用了基于耦合自学习的神经网络量化目标检测引擎。我们通过AutoL的模型,和华为、海康、比特大陆等厂商的芯片,打造了基于AI中台的神经网络编译器,能够实现4比特甚至2比特的快速神经网络计算,使它进行无损压缩和自动量化,实现多重功能的聚合。
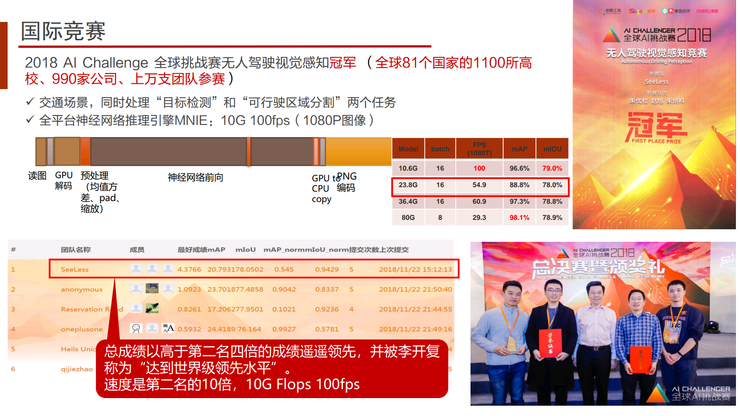
下图展示了我们去年比赛的结果。在三项任务中,我们只用了一个10G算力的GPU,就达到了第二名4倍的总成绩和10倍的计算速度。
我们的多任务同时优化算法可以使一个普通CPU实现1080P的全视频结构化和检测、追踪。
下面介绍几个具体的应用场景。以大家经常提的车辆识别为例,它跟人脸识别类似。我们经过十多年的研发,和交通部、公安部合作,取得了许多重大成果。
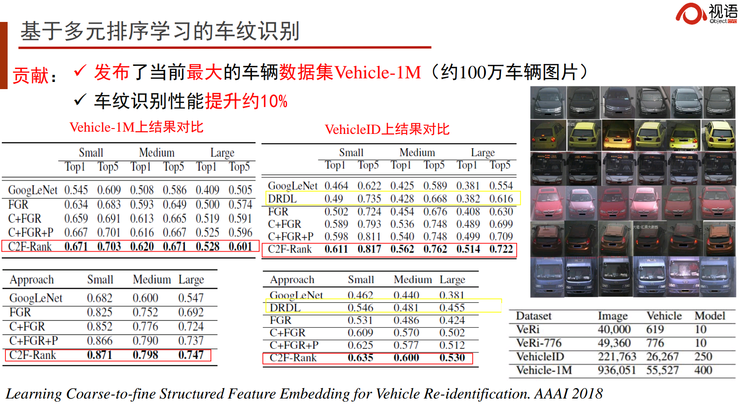
其实每辆车都有自己特定的身份。我们通常只知道自己车的款式,但依然能够在茫茫车海中找到自己那辆,靠的就是车的身份识别。通过局部算法,我们能够实现对车的精细化特征——也就是车纹识别。我们在国际上做了一个目前最大的、针对电子警察和卡口的车辆数据集,叫Vehicle-1M。我们也将发布面向开放场景的更大的数据集,以实现在没有车牌的情况下识别所有车的身份。
我们在神经网络上做过验证,发现每辆车的车窗部分都是有差异的。一辆车售出后,它的年检标、纸巾盒、挂件等就构成了它在某个时间段的独特身份。层级式注意力耦合网络可以对它的这些特征进行学习,实现很好的识别效果。当然这个过程也依赖于大数据的积累。
我们在全国大约6个省份推出了面向高速公路和静态停车场的无感车辆收费系统。无需借助车牌,就可以完成检测、追踪和收费的整个过程。我们甚至还能精细刻画每个车的吨位、排放,从而在大城市依据不同道路情况对车辆的吨位和排放进行自动治理。
车辆识别在交通罚款领域也应用得非常多,不过还有很大的改善空间,需要跟场景进一步结合。
举两个例子。一个是今天交管发的一条新闻,说有个人在开车的时候摸了一下头发,被误认为在打电话,被罚了款。如何精准地区分摸头发和打电话呢?这是个定制化的场景,目前误报还非常多。
另一个是说,有辆车出了事故,拖车从应急车道把它拖走。结果摄像头拍到它占用应急车道,也罚了款。
上面两个例子说明,算法跟场景和业务必须深度结合。AI作为视觉中台,可以有效地提供AI算法,让做服务的公司专心做好服务,做应用的公司专心做好算法和场景的结合。
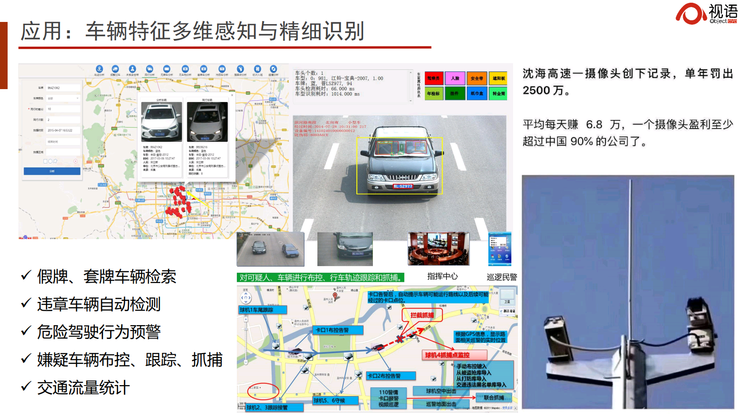
无人值守路测停车也是一种常见应用,我们在雄安、通州和东莞都有落地。我们在一个杆子上装上摄像头,一个摄像头可以看7-8个车位。车辆停进去后我们拍一张照片,等它走的时候再拍一张照片,通过计算两张照片中间的时间间隔,再连接上交管APP就可以实现自动收费。
人脸识别
人脸识别大家都很熟悉,但其实它是个非常难的技术,尤其是在海量数据规模的情况下。算法在网络数据集和实际场景中识别精度之间还存在着巨大的鸿沟。公开数据集中千万分之一误识率的算法,到了实际场景中识别精度可能只有66%。即使我们结合了身份等各种信息,算法在实际场景中的精度依旧很难提升。
人脸三维识别,也就是我们常说的侧脸识别。近几年通过GAN、渲染和几何学的方法,三维数据有了爆炸式的增长。据我们验证,在根据侧脸生成正脸方面,几何学+渲染的方法要胜过GAN。GAN对性能的提升其实非常有限,投入产出比很低,还不如派人力去采集大量数据。
此外,我们还结合了人体信息,相当于人体和人脸的联合学习。这种方法最大的缺陷在于人体的不可靠性。在比较理想的情况下,我们可以清晰判断两个图像是不是同一个人。但在远距离、图像比较小的情况下,数据标注是非常大的挑战。我们甚至还融入了步态,将多种维度的信息进行融合,我们称之为多维立体感知,通过这种方法解决开放式场景的无感人员管理。这是目前行业内的一大研究趋势。
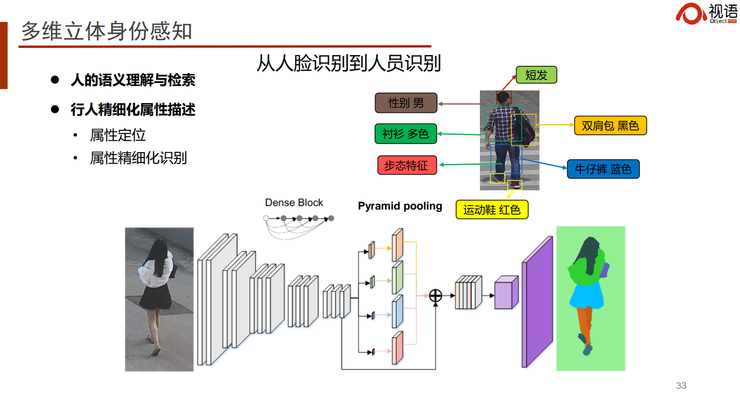
另外,我们还可以结合更多的信息,比如联通和电信的数据、高铁的数据、酒店的数据,在全省范围查询某个人的轨迹。下图展示了我们在河南和湖北用到的一些方案。
我们的中间件目前已经推出,全国好多个地方都在用,我们希望它能够在各个领域发挥巨大的价值。
在国家“双创计划”的鼓励下,我们做科研的同时,也自主创业成立了一家公司“视语科技”。我们公司的愿景就是,通过AI中台让这个世界更加温暖。
- 朗科新出发:入局车规级存储应用产品市场,携手中科院深圳先研院共建朗科研究院
- 游戏价值获人民网、中科院肯定,网易入选游戏企业社会责任报告
- 中科院《科学公开课》曹则贤抖音开讲 为青少年科普物质的形态
- 抖音上线“学习课代表”活动,李永乐、中科院物理所联合推荐科普达人
- 中科院上海有机所&氢通新能源签署战略合作 促进我国氢能产业迈上全球价值链顶端
- 全球首个量子信息技术白皮书发布:中科院、海尔智家、华为等参与制定
- 携手中科院计算所推进开放行业标准,英特尔在华首个oneAPI卓越中心成立
- 阿里淘系技术携手浙大联合举办顶会Workshop竞赛,清北中科院CMU争相角逐
- 中科院人工智能产学研创新联盟发布新一代智算平台
- 中科院人工智能联盟发布智算平台 为算力标一个“真价格”
- 中科院发布国产RISC-V处理器“香山”
- 中科院上海药物所联合华为云发布AI大规模药物筛选服务,提升10倍筛药效率
- 中国移动全千兆荣膺第六届中科院“思维实验室”传播解决方案年度大奖
- 中科院上海药物所联合华为云,发布基于ModelArts的药物联邦学习服务
- 任正非率队访问中科院:探讨基础研究、关键技术发展
- 中科院计算所大数据研究院联合实验室,助力河南人工智能试验建设