算力帝国的双重博弈:解码OpenAI在英伟达与AMD之间的16GW战略布局
2025-12-08 14:55:52AI云资讯2741
2025年秋季,OpenAI同时锁定英伟达与AMD,总规模高达16GW的算力部署,这是推动其下一代模型体系与智能体生态的核心战略动作。英伟达负责确保训练端的最高性能与系统稳定性,而AMD则以更高性价比和更灵活的合作方式参与其中,从而显著降低整体算力成本,并增强供应链安全性。通过资本绑定、软件层与多源硬件协同,OpenAI力图摆脱对单一供应商的高度依赖,也希望在未来十年的算力竞争中获得了更强的议价能力和自主性。这一布局将深刻影响全球AI芯片、数据中心和大模型产业的利润分布格局。
合作复盘
1.算力新纪元:OpenAI的野心与焦虑
从能源角度看,16GW相当于三个纽约市年平均发电量,足以支撑数十亿级用户的推理任务。将如此庞大的能源转化为智能计算,意味着AI基础设施已经脱离了传统的“数据中心”范畴,转变为国家级基础设施。
OpenAI之所以必须提前锁定如此规模的算力,是因为GPT-5及之后的多智能体体系对训练与推理资源提出了前所未有的需求。未来,OpenAI面临着两个核心矛盾:
算力饥渴与产能瓶颈的矛盾:摩尔定律的放缓使得单一芯片性能提升无法满足模型参数指数级增长的需求,必须依靠更大规模的集群。
成本控制与垄断定价的矛盾:英伟达在AI训练芯片市场拥有超过90%的市占率和绝对定价权,这对OpenAI的商业化利润形成了巨大的挤压。
因此,OpenAI的布局并非简单的多供应商策略,而是一场精心设计的资本与技术博弈:用英伟达保上限,用AMD保底线。
2.OpenAI×英伟达:资本驱动的算力霸权
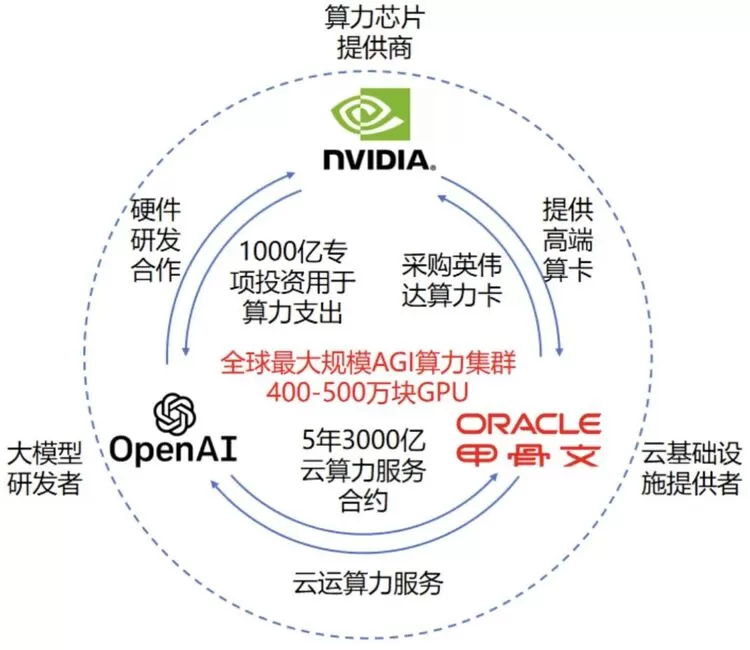
英伟达与OpenAI的关系并非简单的买卖,而是深度的技术共生。2016年,黄仁勋亲自将全球第一台DGX-1AI超级计算机捐赠给OpenAI,这一标志性事件奠定了两者合作的基调。此后,GPT系列的诞生离不开背后英伟达算力卡的绑定。2025年9月,英伟达宣布向OpenAI投资1000亿美元,支持其部署10GW的AI数据中心集群。双方合作不仅限于芯片,还包括网络架构。OpenAI的大规模集群也依赖英伟达的InfiniBand网络,以解决万卡互联时的通信瓶颈。
图1:英伟达、OpenAI、甲骨文的深度合作关系
3.OpenAI×AMD:股权换算力的共生模式
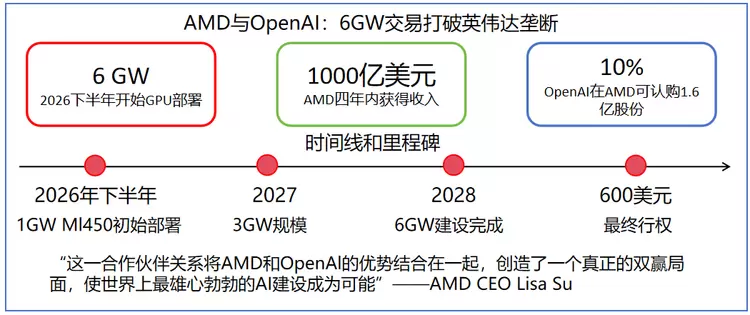
与英伟达的合作几乎同时,OpenAI于2025年10月宣布与AMD签署为期四年的协议,将分阶段部署总计6GW的AMD GPU算力,首批1GW将于2026年下半年到位,使用AMD下一代Instinct MI450系列GPU集成机架级AI系统。
在财务结构上,这项合作采用"股权换算力"模式,AMD向OpenAI发行了至多达1.6亿股AMD普通股的认股权证,约占AMD流通股的10%;如果项目达成某些目标(如AMD股价达到600美元),OpenAI将有权以美股1美分的超低价,收购AMD高达10%的股份。
图2: OpenAI和AMD的合作详解
OpenAI与二者合作模式差异分析
1.OpenAI与英伟达的“资本-生态”闭环
英伟达向OpenAI注资1000亿美元,这在科技史上极为罕见。这笔资金流向呈现出典型的闭环特征:
英伟达现金→OpenAI账户→OpenAI使用资金→采购英伟达芯片(B300/Rubin系列)及网络设备→回流英伟达营收
这本质上是英伟达利用其庞大的现金储备,为自己最大的客户提供融资,以锁定未来五年的算力需求。这种模式构建了极高的竞争壁垒:竞争对手不仅要在技术上击败英伟达,还要在资本实力上提供同等量级的支持,这几乎是不可能的任务。
OpenAI之所以接受这种捆绑,核心在于英伟达提供的不仅仅是芯片,而是全栈解决方案。在万卡、十万卡互联的10GW集群中,通信延迟是最大杀手。英伟达的Quantum-X800InfiniBand网络提供了目前无可替代的高带宽、低延迟互联能力。除此之外,软件生态上,CUDA依然是最稳健的平台。尽管PyTorch等框架在降低门槛,但在万亿参数模型的训练稳定性上,英伟达依然是唯一经过大规模验证的金标准。
根据英伟达最新财报显示,英伟达的毛利率高达73.6%,净利率达到55.9%。这意味着OpenAI每支付1美元,就有0.5美元成为了英伟达的净利润。对于OpenAI而言,这是一笔昂贵的技术税,也是其急于寻找替代方案的根本动力。
表1:芯片厂商利润对比
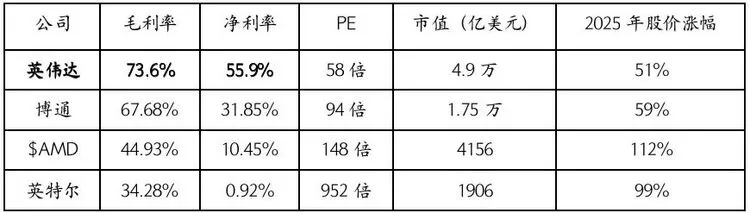
(注:英伟达是2026财年三季度数据,AMD是2025财年上半年数据,博通与英特尔是2025财年前三季度数据,来源:富途)
2.OpenAI与AMD的“股权换算力”变革
与英伟达的现金注资不同,与AMD的合作OpenAI显然更为强势与主动,双方采用了更具创新性的“期权对赌”模式。这种模式将OpenAI从单纯的客户变成了AMD的影子股东。如果AMD的芯片表现优异,股价上涨,OpenAI通过行权获得的收益,甚至可能覆盖其采购硬件的成本。AMD也绑上了OpenAI这艘巨擘,获得了该公司最大的GPU订单,这是一场真正的“共进退”赌局。
AMD不仅提供硬件,还允许OpenAI直接参与芯片设计阶段提供技术反馈,推动AMD从MI300X到MI450等多代产品的迭代优化。AMD愿意为了大客户牺牲部分通用性,进行定制化开发。这一定程度上损失了AMD的利润空间以满足OpenAI的需求,双方共同优化ROCm软件栈,试图打破CUDA的垄断。这是英伟达无法提供给OpenAI的。
OpenAI也在从其他角度想办法绕开英伟达。Triton,这一由OpenAI提出的创新编程语言和编译器,专为简化高性能GPU内核开发而设计,力图屏蔽底层硬件差异。只要代码是用Triton写的,它可以自动编译,无需深入理解复杂的GPU底层架构。这使得OpenAI可以无缝切换到性价比更高的AMD芯片上,而无需被CUDA锁定。
量化分析:为什么选AMD?性价比的考量
结合产业数据披露的信息,对OpenAI引入AMD的决策进行量化拆解。这不仅是战略选择,更是精算的数学题。
1.硬件采购成本(CapEx)对比
根据2025年英伟达与AMD公布的财报,构建简易模型对比英伟达(以B200对应世代产品为例)与AMD(以MI450为例)的单卡成本结构。
表2:英伟达与AMD单卡成本对比
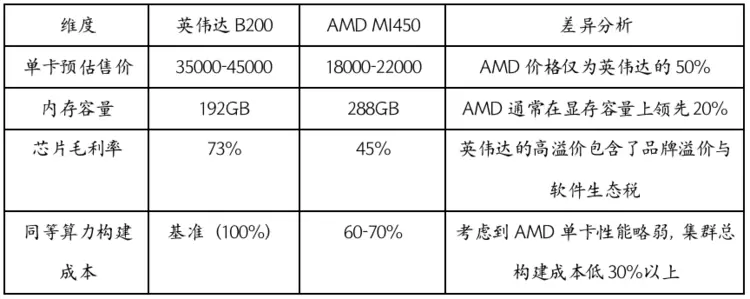
(注:英伟达B200、AMD MI450数据来自官网;芯片毛利率来自英伟达2026财年三季度数据、AMD2025财年上半年数据)
2.性能与性价比测算
OpenAI最为看重的是每美元产生的Token数量。在训练场景下,英伟达仍有不可替代优势。在这里,我们更多讨论推理场景中英伟达与AMD的对比。
假设英伟达单卡算力为Pnv,价格Cnv。
假设AMD单卡算力为0.8×Pnv,(根据MosaicMI测试,AMD MI250X在大模型训练任务中的MFU约为英伟达A100的80%左右,以此为标准测算),价格0.5×Cnv。
性价比(单卡算力价格单价):
英伟达:Pnv/Cnv=1(基准)
AMD:(0.8×Pnv)/(0.5×Cnv)=1.6
AMD的单卡理论性价比是英伟达的1.6倍。考虑到CUDA生态成熟,相同硬件下,NVIDIA集群的实际训练速度更快、故障率更低。在未深度优化ROCm的情况下,AMD集群需多10–25%的卡才能达到同等训练吞吐,这也是下一步OpenAI与AMD需要深度合作解决的。未来业务中推理占比将大幅超过训练,部署6GW的AMD算力用于推理和中型模型微调,是极具经济理性的选择。
3.股权激励的财务数据
假设OpenAI完成6GW部署,且AMD股价在四年内达到600美元(签约时股价为200美元左右)。四年后OpenAI拥有1.6亿股认购权,行权价极低(0.01美元,几乎免费赠送)。
对OpenAI来说,潜在收益为1.6亿股×600美元 = 960亿美元。而建设1GW算力数据中心的成本大约为400亿美元(包括土建、电力、运维、网络、服务器、GPU等),可覆盖部分算力部署成本。对比英伟达模式下巨额支出,显然与AMD的合作极具吸引力。
结语
OpenAI的16GW双供应链布局代表了全球算力竞争的新阶段:既要在性能上保持绝对领先,又要在成本与供应链安全上掌握主动权。英伟达提供训练端的确定性,AMD则提供推理端的经济性与供应链弹性,而 OpenAI通过资本、软件与生态协同将两者纳入统一体系。这一布局将决定未来十年全球 AI 芯片、数据中心与模型生态的利润版图,并成为全球算力竞争格局的关键转折点。
相关文章
- 云工场科技成为海淀3x3超级争霸赛与无锡杯官方算力支持伙伴
- 博大数据荣膺“全球AI生态基石大奖”,夯实融合算力基础设施服务商领先地位
- 日联以纳米级洞见,守护AI算力万亿市场
- 光互联引领算力新基建,三安光电卡位全球产业新周期
- 全球首款RISC-V+AI智通融合服务器CPU,蓝芯算力重磅亮相移动云大会
- 智云洞察 | 从词元调用量1000倍增长的背后,看智能体时代算力价值的跃迁!
- 10万亿+Token:“算力育人”的全新范式/崭新样本
- 象帝先最新消息:携手软通华方,共筑国产算力全生态
- 中国移动研究院段晓东:从“AI Native”到“Token Native”,算力网络迈向发展新阶段
- 中国移动发布全国一体化算力网技术创新体系
- 聚力算力建设 深化政企协同 -- 中兴通讯助力福州数字经济高质量发展
- 国产算力×国产模型,联想开天工作站全面适配 DeepSeek V4!
- 对算力瓶颈发起总攻:新紫光亮出“全家桶”
- 海光信息亮相数字中国峰会 以硬件内生安全构筑AI算力防护体系
- 中科曙光超智融合集群接入全国一体化算力网,AI4S驶入普惠快车道
- 中科曙光超智融合算力集群,正式接入全国一体化算力网!
人工智能企业
更多>>



人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力
- 昇腾原生支持,科学多模态大模型Intern-S1-Pro正式发布并开源
- 百度千帆深度研究Agent登顶权威评测榜单DeepResearch Bench


