MIT韩松专访:Once for All 神经网络高效适配不同硬件平台
2020-05-26 08:58:21爱云资讯
ICLR,全称为“International Conference on Learning Representations”,即国际学习表征会议。虽然其官网非常简洁,但是 ICLR 本身包括了无监督、半监督和监督表示学习、计划学习、强化学习及机器学习技术在多个领域的应用,可以说是人工智能学术界的一场盛宴。
来自麻省理工学院的韩松曾在 ICLR 多次发表论文,他的论文Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding获得了 2016 年 ICLR 的最佳论文奖。
而在 2020 年,他的团队又带来了一项名为Once-for-All: Train One Network and Specialize it for Efficient Deployment的突破性研究。
Once-for-All: Train One Network and Specialize it for Efficient Deployment论文详情(来源:AMiner 会议智图开放平台 ICLR 2020 专题全析图)
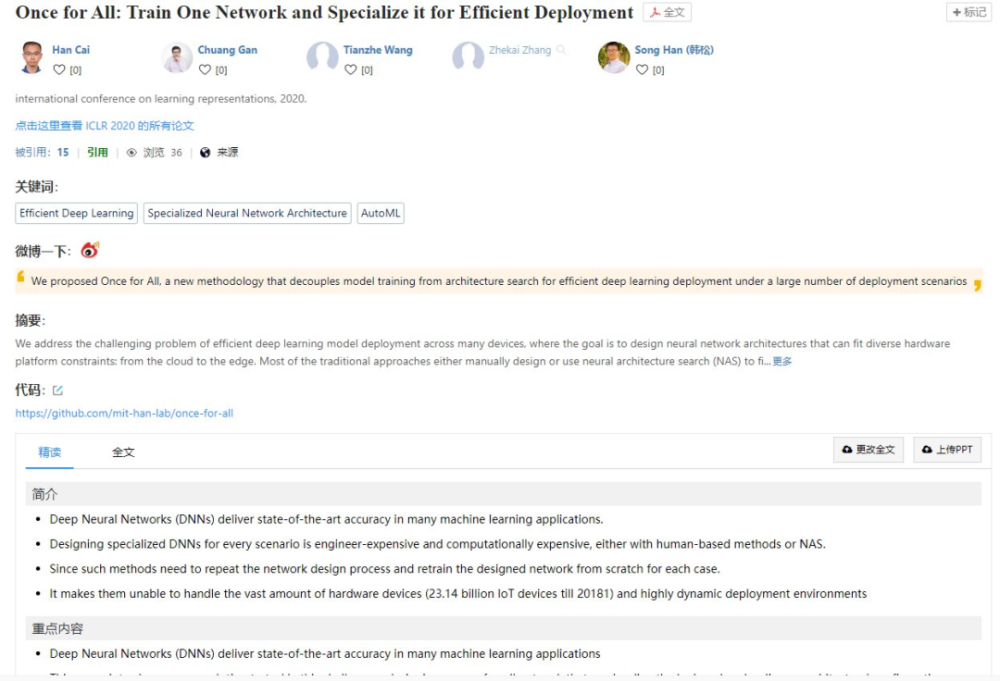
这篇论文的主要内容,是通过一种 Once for All 网络,可高效生成 10^19 独立工作的子网络以便适配到不同的硬件平台,比如包含了服务器端各种不同的 GPU(例如英伟达 1080Ti, 2080Ti, V100), CPU (例如英特尔 Xeon 系列)以及移动端各种不同的边缘设备。
为了提高硬件平台上的推理效率,需要改变神经网路的结构(例如深度,宽度,卷积核大小,输入分辨率等)来适配具体的硬件。在同一个平台上,研究人员也设置了不同的效率限制,目的是在算力不同的平台运行时达到平衡。
一个通用的 OFA 网络支持在大量不同的结构设置下通过截取 OFA 网络的不同部分来进行高效推理。对于计算资源丰富的云端设备,可以截取一个大的子网;而对于计算资源短缺的边缘设备,则可以截取一个较小的子网。
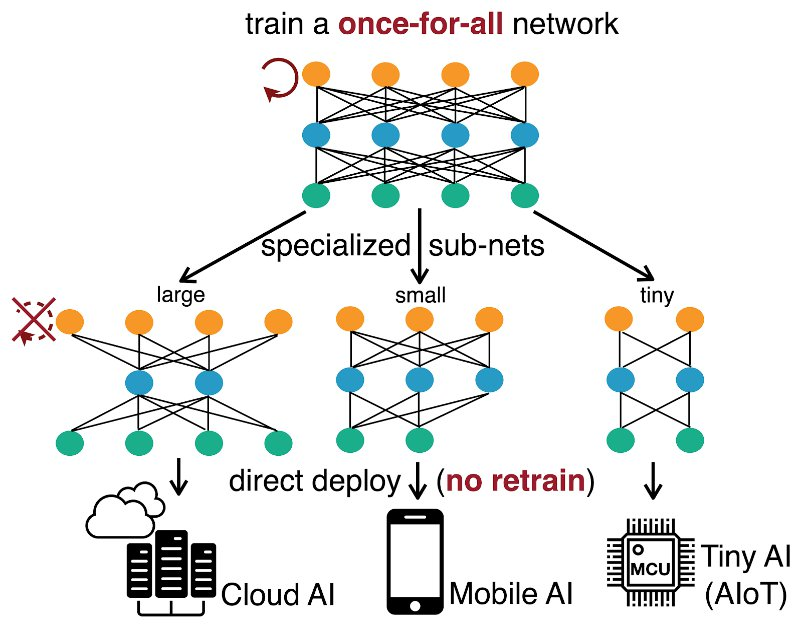
按照传统方法,开发者往往会考虑手动设计或使用神经体系结构搜索(Neural Architecture Search,NAS)的方法,但是这需要大量的 GPU hours 和能源消耗(见下图)。
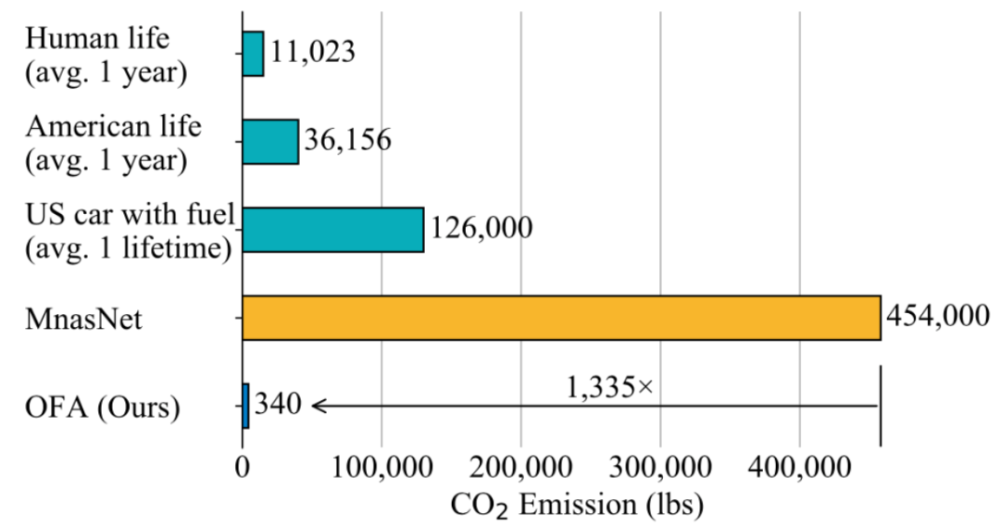
为了在跨平台的模型部署中降低成本,顺便还能提升运算效率,韩松团队尝试建立更小,更绿色的神经网络。为此,他们训练了一种支持所有体系结构设置(深度,宽度,内核大小和分辨率)的“全包式”网络,称其为“一劳永逸网络”( Once-For-All Network,简称 OFA)。
借鉴这篇论文的方法,韩松和朱俊彦团队将在 CVPR’20 发表了题为GAN Compression: Efficient Architectures for Interactive Conditional GANs的新成果。这是一篇关于如何压缩条件生成对抗网络(cGAN)算力消耗量过大的论文,提出了一种通用的压缩框架,以减少 cGAN 在运算过程中的推理时间和模型大小。
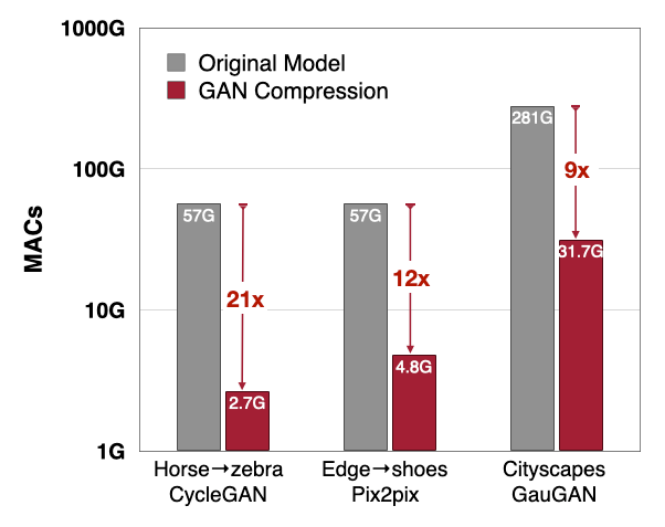
当然,凡是出现压缩这个关键词,准确率的补偿就势必会成为大家关注的重点。论文提到,对于 CycleGAN 之类的 unpaired(训练数据给定输入没有对应的真实输出)模型,由于输入图片没有与之对应的真实图片,因此直接将输入图片喂给一个已经训练好的 teacher 模型,将其输出当成与输入对应的真实图片。由此一来,unpaired 情况也统一成 paired 的情况。同时也降低了模型建模的难度,这使得小模型能够更好得学习输入图片到目标图片的转换。
其次,无论是 paired 模型还是 unpaired 模型,都让小模型的中间层 activations 和 teacher 模型的中间层 activations 尽可能的相匹配,以此来学习隐藏在潜藏在 Teacher 模型中的一些知识,提升小模型的性能。与此同时,和 teacher 模型协同训练的 discriminator 也保有大量的知识,因此在训练小网络的过程中,继续沿用 teacher 的 discriminator,与小网络进行协同训练。
最后,考虑到模型可能还存在许多冗余的计算量,进而使用 NAS 方法,自动检测生成器网络每层的通道数的冗余度,以此让网络更加高效。

交互式图像生成目前已经产生了很多的应用,比如用户可以实时地把自己的绘画转换成真实的图片,此类应用可用在教育领域,培养孩子创造力;或者 VR 场景和设备,可以把眼前的景象转换卡通或者油画风格的,满足场景体验的需求。但这些应用都要求 Conditional GANs 在在一些硬件资源有限移动设备上进行部署,这样才能将这些应用真正地为人所用。这是这项工作的动机之一。

以下为记者与韩松团队的博士生蔡涵的部分交流内容:
记者:Once-for-All: Train One Network and Specialize it for Efficient Deployment提到了一种可以在多种不同硬件平台上通用的神经网络,我是否可以把他理解成客户端和服务器端通用?那么PC端和手机端是否也能通用?如何实现?
蔡涵: 是的。一个通用的 OFA 网络可以衍生出 10^19 个专用的子网络来适配多种不同硬件平台,包含了服务器端各种不同的 GPU(例如英伟达 1080Ti, 2080Ti, V100), CPU (例如英特尔 Xeon 系列)以及客户端各种不同的边缘设备(高端手机例如三星 Note10;低端手机例如三星 S7,谷歌 Pixel1;专用硬件例如赛灵思 FPGA)。不同的硬件平台有不同的特性和硬件资源。在同一个平台上,我们也会有不同的效率限制。为了提高硬件平台上的推理效率,我们需要改变神经网路的结构(例如深度,宽度,卷积核大小,输入分辨率等)来适配具体的硬件。一个通用的 OFA 网络支持在大量不同的结构设置下通过截取 OFA 网络的不同部分来进行高效推理。对于计算资源丰富的云端设备,我们可以截取一个大的子网。而对于计算资源短缺的边缘设备,我们则可以截取一个较小的子网。
记者:为什么我们需要这样的不同硬件平台通用的OFA网络?
蔡涵: 如果我们直接在所有硬件平台上使用同一个神经网络,这会导致大量性能和效率上的损失,因为同样的神经网络并不能适配所有场景。如果我们针对每个硬件平台和效率约束都重头设计并训练一个新的神经网络,这会导致大量的计算资源的消耗,因为这种方式计算资源的需求是随着部署场景数线性增长的。这同样也会导致严重的环境问题,因为大量的计算资源消耗直接可以转化为大量的二氧化碳排放。因此我们需要这样的通用的 OFA 网络,既可以针对不同硬件平台进行适配而不损失性能和效率,同时不需要额外的计算资源来从头训练一个新的神经网络。
记者:在训练这样一个通用的OFA网络的时候,你们遇到了什么挑战?是如何处理的?
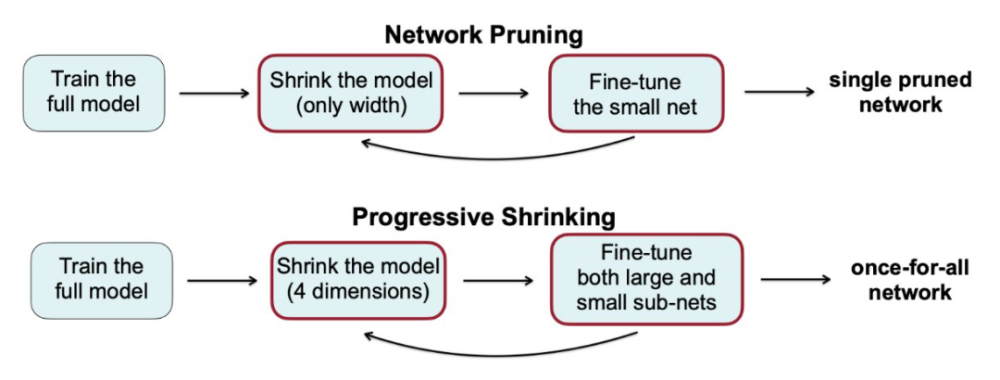
蔡涵: 主要的难点在于,一个 OFA 网络需要同时支持大量不同的子网(>10^19)。它们之间会相互干扰,这使得 OFA 网络比一般结构确定的神经网络要更难优化。为了解决这个问题,我们提出 progressive shrinking 算法来训练 OFA 网络。我们注意到各种不同的子网是一层层嵌套在最大的神经网络中的。因此我们将 OFA 网络的训练过程建模为一个逐渐缩小与微调的过程。我们首先会训练最大的网络。然后逐渐缩小网络的各个维度(输入分辨率,卷积核大小,深度,宽度)来支持较小的子网。同时我们会微调网络的权重使其在支持较小的子网的同时不会丢失在较大子网下推理的能力。某种程度上,progressive shrinking 也可以看作是一种广义上的剪枝方法。
记者: OFA和NAS的方法相比有什么优势?
蔡涵: 从计算资源的角度,NAS 方法的总计算资源是随着部署场景数量的增加而线性增长的。当有多个部署场景的时候,OFA 会比 NAS 方法高效得多。具体上,在 40 个部署场景的情况下,OFA 的总计算资源消耗是ProxylessNAS的1/16,MnasNet的1/1300。从准确率的角度,我们发现 OFA 中的子网在经过微调后可以达到比单独从头训练更好的准确率。在 ImageNet 上,OFA 在大量的硬件平台和效率约束下都达到了远好于 EfficientNet 和 MobileNetV3 的准确率。在 ImageNet 移动设置下(
记者:你们有开源代码的计划吗?
蔡涵: 我们已经在Github上开源了我们的训练代码,以及 50 个用于各种硬件平台的 ImageNet 预训练模型,其中包括了我们在 600M MACs 约束下达到 80.0%ImageNet 准确率的模型。我们还提供了预训练的 OFA 网络,支持以 0 训练成本得到大量不同的子网。
韩松,清华大学电子系本科,斯坦福大学电子系博士,师从 NVIDIA(英伟达)首席科学家 William J. Dally 教授。现任麻省理工学院(MIT)电气工程和计算机科学系助理教授。他是深鉴科技的联合创始人、首席科学家,该公司被 Xilinx(赛灵思)收购。
2019 年,韩松被《麻省理工科技评论》评选为全球 “35 岁以下科技创新 35 人” ,2020 年获得 AI 2000 机器学习全球最具影响力学者提名奖(2020 AI 2000 Most Influential Scholar Award Honorable Mention in Machine Learning)。
韩松的研究广泛涉足深度学习和计算机体系结构,他提出的 Deep Compression 模型压缩技术曾获得 ICLR2016 最佳论文,论文 ESE 稀疏神经网络推理引擎 2017 年曾获得芯片领域顶级会议——FPGA 最佳论文奖,引领了世界深度学习加速研究,对业界影响深远。
近两年,韩松博士的一系列论文获得了工业界与学术界的广泛关注,加州伯克利大学和纽约大学均把论文内容纳入专题课程。而工业界中,Google, Facebook, Baidu, Xilinx, NVIDIA 等诸多大型科技公司也开始采用“深度压缩”技术,应用于云端和移动端的人工智能产品中;Facebook 和 Amazon 也将韩松团队的 ProxylessNAS 高效小模型加入了 PytorchHub 和 AutoGluon。
- Unity着手推进神经网络渲染技术应用,颠覆呈现虚拟 3D 世界的方式
- 科研成果发布│基于超图神经网络的推荐系统论文
- 打破神经网络技术应用局限性,度小满博士后论文入选国际顶级会议
- 本科生新算法打败NeRF,不用神经网络照片也能动起来,提速100倍
- 特斯拉AI DAY:AI神经网络解读 Dojo超算信息/AI机器人发布
- 2021世界人工智能大会AI Debate:图神经网络是否是实现认知智能的关键?
- 新专利显示苹果VR头显可能利用神经网络监测用户的姿势
- 图神经网络的知识提取与超越:一个有效的知识蒸馏框架
- 人工神经网络秒变脉冲神经网络,新技术有望开启边缘AI计算新时代
- 深度神经网络是为人工智能的重要基石
- Imagination推出新神经网络加速器 可用于ADAS和自动驾驶
- 深度学习与神经网络推动AI芯片市场以约40%的年成长率持续扩张
- 百度飞桨PGL-UniMP刷新3项任务记录 登顶图神经网络权威榜单OGB
- Helm.ai宣布了一种新的深度教学方法来训练神经网络
- 科学家们致力于利用神经网络改变神经成像研究
- 开发AI神经网络用于打假 阿里安全获计算机视觉顶会ECCV2020竞赛冠军





