训练部署一条龙,飞桨OCR模型开源,网友调侃:从业人员“失业大礼包“
2020-07-17 08:23:49爱云资讯
近日,百度飞桨正式开源了业界最小的超轻量8.6M中英文识别OCR模型套件PaddleOCR,在模型大小、精度和预测速度上,甚至超过了之前一度登上GitHub热榜的chineseocr_lite(5.1k stars),简单场景下OCR效果更是能媲美收费软件。
除了性能优越之外,百度PaddleOCR还是第一个完整支持从训练到部署完整流程的OCR模型套件,而且部署方式多样,覆盖手机端(含IOS、Android Demo)、嵌入式端,大规模数据离线预测,在线服务化预测等。通过多种预测工具组件的支持,百度PaddleOCR能够满足多样化的工业级应用场景。同时其支持自定义训练,用户可以使用自己的数据集Fine-tune以达到更好的效果,大大提高了程序员们训练部署OCR模型和项目落地的效率,最大程度上满足了企业的不同需求。
随着百度PaddleOCR的开源,其在促进OCR行业发展的同时,也正在赋能企业,推动产业智能化发展。
8.6M超轻量中英文OCR模型
近年来,随着技术的发展,文字识别(OCR)已经被广泛的运用至各个场景之中,包括自然场景中文字识别、车牌识别、票据识别等等,是机器服务人类的重要场景之一。
然而目前OCR发展面临着诸多难题,一方面,由于自然环境复杂多样,机器识别面临着尺度、光照不足、拍摄模糊等问题,加大了识别的难度。另外一方面,OCR应用常对接海量数据,要求数据能够得到实时处理。除此之外,由于OCR应用常常部署在移动端或嵌入式硬件,但端侧的存储空间和计算能力有限,因此对OCR模型的大小和预测速度有很高的要求。
而此次百度开源的8.6M超轻量中文OCR模型,包含1个检测模型(4.1M)与1个识别模型(4.5M),是目前业界开源的最小OCR模型。相比于市面上其它的OCR模型,PaddleOCR取得了显著的进展,这使得其能够更为便捷的部署在移动端、嵌入式端等多个场景,更加方便用户使用。
除此之外,百度PaddleOCR也能够快速准确地识别各个场景中的文字,无惧尺度、光照等难题。同时,其还支持中英文识别以及倾斜、竖排等多种方向文字识别,为用户呈现出最佳结果。




在GitHub上搜索PaddleOCR,可以了解更多详情。
一站式服务,满足企业多样需求
PaddleOCR作为飞桨的文字识别模型套件,除了开源前沿模型外,还提供了自定义训练和多硬件部署的开发套件,真正为开发者提供了从模型训练到部署的全流程服务。
为了方便开发者使用自己的数据自定义超轻量模型,除了8.6M超轻量模型外,PaddleOCR同时提供了2种文本检测算法(EAST、DB)、4种文本识别算法(CRNN、Rosseta、STAR-Net、RARE),基本可以覆盖常见的OCR任务需求,并且算法还在持续丰富中。
事实上,此次百度PaddleOCR开放的多种业界前沿文本检测与识别算法中,部分算法的效果达到甚至超越了原作。这意味着开发者依托百度开源的技术,可以大幅提高模型效果,打造出更为优质的OCR产品。
同时开发者如果想要使用自定义数据训练超轻量模型,也可以从PaddleOCR提供的基础算法库中选择适合自己的文本检测、识别算法,进行自定义的训练。自定义训练的存在让开发者可以使用自己的数据集打造更为契合自身需求的产品,极大程度满足了不同开发者的需求。
除了贴心的自定义训练,满足开发者产业级训练的需求之外,百度PaddleOCR为了更好的方便开发者和企业应用,还打造了一系列的模型部署组件,可以支持开发者和企业在服务端、移动端、嵌入式硬件,云端服务化等多个不同的硬件平台部署,最大化地满足OCR文字识别领域的企业应用。
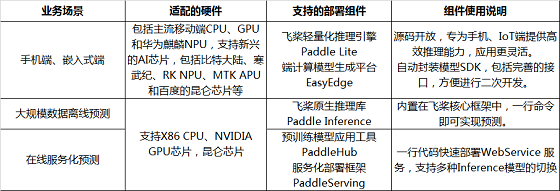
值得一提的是,在为企业和开发者提供全方位技术支持的基础之上,PaddleOCR还为开发者整理了常用的中文数据集、标注和合成工具,并在持续更新中。
目前百度开放的数据集包括:大规模通用数据集,大规模手写中文数据集,垂类多语言OCR数据集,还整理了常用数据标注工具、常用数据合成工具,并且开源以来,受到开发者的广泛关注,已经有大量开发者投入到项目的建设中并且贡献内容。
从技术开放到支持多场景部署,再到数据整理,百度PaddleOCR真正意义上为企业和开发者提供了从训练到部署一站式的全流程服务。
未来,百度PaddleOCR将会持续深耕OCR领域,进一步提升单模型效果、压缩模型大小,加速技术迭代,让机器更好的服务人类。同时通过开源开放技术,更好的赋能企业,以此加速产业智能化发展。
- 摩尔线程加入飞桨硬件生态共创计划,加速人工智能生态和创新应用发展
- 十个大模型、六大发布 WAVE SUMMIT 2022飞桨持续夯实AI底座
- WAVE SUMMIT 2022将于5月20日召开 飞桨将迎来大规模升级
- 中科曙光×百度飞桨,以算力助跑开发者同台竞技
- 河南师范大学等27所高校联合百度飞桨推出“人工智能微专业”
- 百余位高校教师齐聚“云端课堂”,百度飞桨师资培训班落地重庆大学
- “创客北京2021”百度飞桨人工智能产业创新应用专项赛决赛圆满结束
- 2021全国人工智能师资培训走进北理工,百度飞桨助力高校教师提升AI能力
- 百度飞桨人工智能产业赋能中心于上海浦东启动运营
- 岳麓山下齐聚全国高校教师 飞桨深度学习师资培训开班助AI教学
- 支持更大规模产业应用!百度飞桨获KDD CUP 2021两金一银
- “创客北京2021”百度飞桨AI产业创新应用专项赛正式启动
- 开源生态融合,DeepModeling开源社区使用飞桨攻坚分子动力学
- 产教融合新范式 飞桨助力高校创新AI人才培养
- 融合创新 伙伴同行 飞桨推动产业走通AI工业大生产之路
- 飞桨全新发布推理部署导航图,助力打通AI应用最后一公里





