腾讯混元文生图开源模型推出小显存版本,仅需6G显存即可运行
2024-07-06 15:07:18AI云资讯69297
7月4日,腾讯混元文生图大模型(混元DiT)宣布开源小显存版本,仅需6G显存即可运行,对使用个人电脑本地部署的开发者十分友好,该版本与LoRA、ControlNet等插件,都已适配至Diffusers库;并新增对Kohya图形化界面的支持,让开发者可以低门槛地训练个性化LoRA模型;同时,混元DiT模型升级至1.2版本,在图片质感与构图方面均有所提升。
模型易用性再提升,个人电脑可轻松运行
基于DiT架构的文生图模型生成图片质感更佳,但对显存的要求却非常高,让许多开发者望而却步。这也是新版本Stable Diffusion模型无法快速普及的原因之一。
应广大开发者的需求,混元DiT推出小显存版本,最低仅需6G显存即可运行优化推理框架,对使用个人电脑本地部署的开发者非常友好。经过与HuggingFace合作,小显存版本、LoRA与ControlNet插件,都已经适配到Diffusers库中。开发者无需下载原始代码,仅用简单的三行代码仅可调用,大大简化了使用成本。
同时,混元DiT宣布接入Kohya,让开发者可以低门槛地训练专属LoRA模型。
Kohya是一个开源的、轻量化模型微调训练服务,提供了图形化的用户界面,被广泛用于扩散模型类文生图模型的训练。用户可以通过图形化界面,完成模型的全参精调及LoRA训练,无需涉及到代码层面的细节。训练好的模型符合Kohya生态架构,可以低成本与 WebUI 等推理界面结合,实现一整套“训练-生图”工作流。
此外,腾讯宣布混元文生图打标模型”混元Captioner“正式对外开源。该模型支持中英文双语,针对文生图场景进行专门优化,可帮助开发者快速制作高质量的文生图数据集。
相比起业界的开源打标模型,混元Captioner模型能更好的理解与表达中文语义,输出的图片描述更为结构化、完整和准确,并能精准识别出常见知名人物与地标。模型还支持开发者自行补充和导入个性化的背景知识。
混元Captioner模型开源之后,全球的文生图研究者、数据标注人员,均可使用混元Captioner高效地提升自身图像描述质量,生成更全面、更准确的图片描述,提升模型效果。混元Captioner生成的数据集不仅能用于训练基于混元DiT的模型,亦可用于其他视觉模型训练。
众多开发者关注,成最受欢迎国产DiT开源模型
在提升模型易用性的同时,腾讯宣布混元文生图打标模型”混元Captioner“正式对外开源。该模型支持中英文双语,针对文生图场景进行专门优化,可帮助开发者快速制作高质量的文生图数据集。
相比起业界的开源打标模型,混元Captioner模型能更好的理解与表达中文语义,输出的图片描述更为结构化、完整和准确,并能精准识别出常见知名人物与地标。模型还支持开发者自行补充和导入个性化的背景知识。
作为首个中文原生DiT开源模型,混元DiT自全面开源以来,一直持续建设生态。6月,混元DiT发布的专属加速库,可将推理效率进一步提升,生图时间缩短75%;并进一步开源了推理代码;发布LoRA和ControlNet等插件。于此同时,模型易用性大幅提升,用户可以通过Hugging Face Diffusers快讯调用混元DiT模型及其插件,或基于Kohya和ComfyUI等图形化界面训练与使用混元DiT。
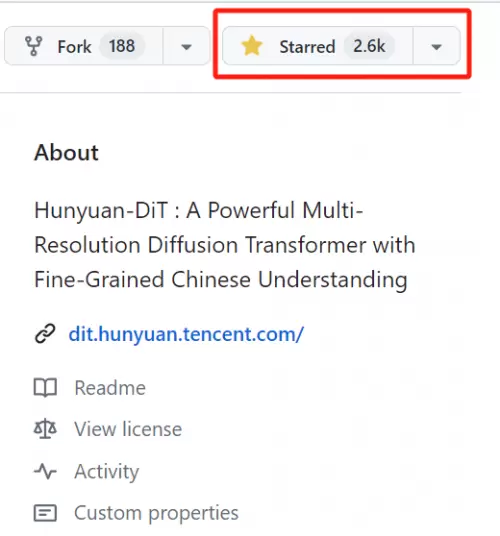
目前,在众多开发者的支持下,混元DiT发布不到2个月,Github Star数已经超过2.6k,成为最受欢迎的国产DiT开源模型。
相关文章
- AI智能体从概念走向落地 赞同科技CTO蒲云出任腾讯云AI智能体嘉年华(华东赛区)专家评委
- 领驭科技×腾讯云联合亮相2026深圳国际眼镜业博览会
- 腾讯云发布边缘Web与AI Agent托管平台 EdgeOne Makers:一键开发部署,分钟级全球上线
- 中国企业创新盘点——同时入选《财富》中国科技50强的联想集团与华为、腾讯、阿里
- 腾讯云TVP走进香港数码港,解码AI出海新范式
- 腾讯云以 99.8% 防护率通过AV-C年度评测
- 值得买科技与腾讯云深化“AI+消费”合作,首个消费决策Skills上线腾讯WorkBuddy
- 一码三端!HDC 2026腾讯视频鸿蒙版跨端方案重磅公布
- 李未可AI眼镜成为腾讯云WorkBuddy首批生态伙伴,加速终端入口商业化落地
- 打破传统网络边界,飞猫引入腾讯云聚通加速能力破解游戏延迟难题
- 腾讯首发效率智能体工具集,打造“AI提效新标配”
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- 腾讯云ADP4.0发布:推出Claw模式,助力企业Agent规模化落地
- 腾讯董志强:AI Agent已成为众多企业“数字员工”,安全防护需要同步跟上
- Agent进入“生产级”时代!腾讯云ADP4.0发布,打造企业级 AgentOps平台
- 腾讯文档「人机双写」行业首发,原生接入WorkBuddy打造新一代AI办公工作台
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


