ACL 2025 | 腾讯优图实验室大模型4篇论文入选,涵盖智能体、角色扮演、自动推理等方向
2025-06-20 20:13:51AI云资讯4730
ACL即国际计算语言学年会(Annual Meeting of the Association for Computational Linguistics),是自然语言处理(NLP)领域的顶级学术会议之一,ACL论文通常代表了该领域的前沿研究成果。2025年是该会议的第63届,将于7月27日至8月1日在奥地利维也纳举行。
2025年被称为ACL论文收录竞争最为激烈的一年。前段时间,ACL公布了今年总投稿数,高达8000多篇,创历史之最。今年,腾讯优图实验室入选ACL大模型方向论文4篇,涵盖智能体、角色扮演、自动推理等方向。
以下为入选论文摘要:
1
RolePlot:一个用于评估与提升角色扮演智能体情节推进能力的系统化框架
RolePlot: A Systematic Framework for Evaluating and Enhancing the Plot-Progression Capabilities of Role-Playing Agents
Pinyi Zhang, Siyu An, Lingfeng Qiao, Yifei Yu, Jingyang Chen(华东师范), Jie Wang(华东师范), Di Yin, Xing Sun, Kai Zhang(华东师范)
作为一种新的对话方式,角色扮演智能体(RPAs)正受到愈发广泛的关注。到目前为止,对RPAs的研究主要集中于对角色能力和风格的刻画上,而我们从用户使用的角度出发,发现在对话中提升模型对情节的推进能力,能够带来更加具有吸引力的交互体验。为此,我们提出了RolePlot框架,用于专门评估和提升RPAs的情节推进能力。该框架的创新性体现在三个方面:首先,我们构建了基于文学剧本的人工标注和经过验证的合成数据;其次,我们利用大语言模型(LLMs)参数化的embedding,通过检测适合触发剧情推进的子空间,来精准识别对话中可能引发情节转折的关键片段;最后,当检测到用户输入与剧情推进子空间匹配时,系统会主动提示RPAs在对话中推进情节发展。在评估阶段,我们通过模拟用户和RPAs的交互场景,重点通过两个核心指标来评价:对话持久性(对话持续轮次)和用户兴奋度变化。实验结果表明,本方法不仅显著提高了RPAs把握情节转折时机的精准度,更重要的是使用户和RPAs的平均对话轮次大幅增加,同时能持续维持更高水平的用户兴奋度。这有力证明了我们的方法能有效提升用户的沉浸式交互体验。
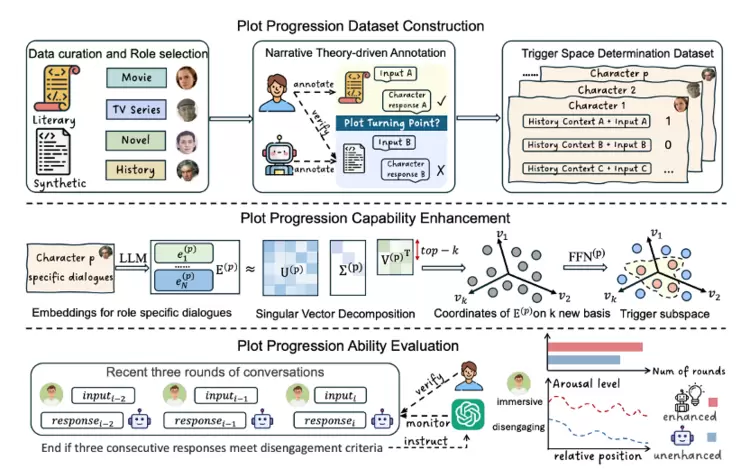
论文链接:
https://openreview.net/pdf?id=8mDY631t8p
2
知所未知:通过表征编辑增强角色扮演智能体的拒答能力
Tell Me What You Don’t Know: Enhancing Refusal Capabilities of Role-Playing Agents via Representation Space Analysis and Editing
Wenhao Liu, Siyu An, Junru Lu, Muling Wu(复旦), Tianlong Li(复旦), Xiaohua Wang(复旦),Changze Lv(复旦), Xiaoqing Zheng(复旦), Di Yin, Xing Sun, Xuanjing Huang(复旦)
目前角色扮演智能体(RPAs)已在多种应用中展现出卓越的性能,但其在识别和回应与角色知识相冲突的复杂查询时仍存在显著不足。为了探究RPAs面对不同类型冲突请求时的表现,我们设计了一个包含三类请求的评估基准:通过上下文知识冲突请求、参数知识冲突请求以及非冲突请求,来系统评估RPAs识别冲突并适度拒答的能力。我们通过大规模实验发现,多数RPAs对不同冲突请求存在显著的性能差异。为了揭示原因,我们对不同冲突场景下的RPAs进行了表征层面的深度分析,发现模型前向表征中存在"拒绝区域"和"直接响应区域",这些区域会显著影响RPAs的最终响应行为。基于此,我们提出一种轻量级表征编辑方法,通过适当地将冲突请求映射到拒绝区域来提升模型的拒答准确率。我们通过大量实验验证了该方法的有效性:在保持RPAs基础角色扮演能力的同时,显著提升了其对知识冲突请求的拒答能力。
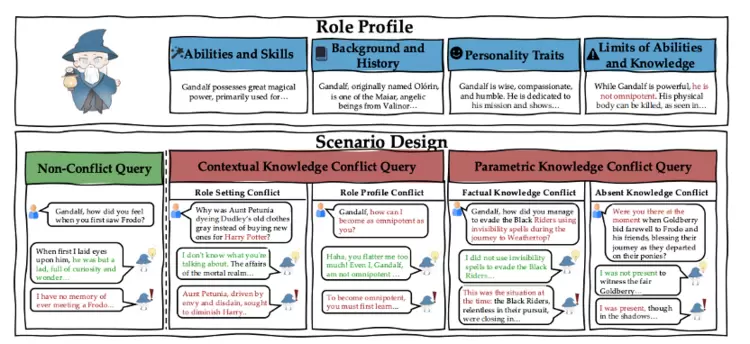
论文链接:
https://arxiv.org/pdf/2409.16913
3
RoleMRC:角色扮演和指令遵循的细粒度复合基准
RoleMRC: A Fine-Grained Composite Benchmark for Role-Playing and Instruction-Following
Junru Lu, Jiazheng Li (KCL), Guodong Shen (华威), Lin Gui (KCL), Siyu An, Yulan He (KCL), Di Yin, Xing Sun
角色扮演是大语言模型 (LLM) 的一项关键能力,即要求大模型在给定角色身份和知识的边界内响应多样化指令。现有的角色扮演数据集专注于控制角色风格和知识边界,但忽略了指令遵循场景下的角色扮演。为此,我们首次引入了一个细粒度的角色扮演和指令遵循复合基准RoleMRC,覆盖以下场景:(1) 理想角色与人类之间的多轮对话,包括自由聊天或围绕给定段落的讨论;(2) 角色扮演机器阅读理解,包括根据段落可答性和角色知识边界做出回应、拒绝和尝试;(3) 更复杂的任务,包含嵌套、多轮和优先级控制等指令下的角色扮演。RoleMRC合计包含10.2k个标准化角色设定、37.9k条精心合成的角色扮演指令和1.4k个测试样本。基于RoleMRC,我们开发了一套评估方法,用于定量评估大模型的细粒度角色扮演和指令遵循能力。此外,在外部角色扮演数据集上的交叉评估证实,基于RoleMRC进行微调的角色模型能够增强指令遵循能力,且不会损害一般的角色扮演和推理能力。我们还从神经元视角对大模型角色扮演与指令遵循能力的激活过程进行了分析。
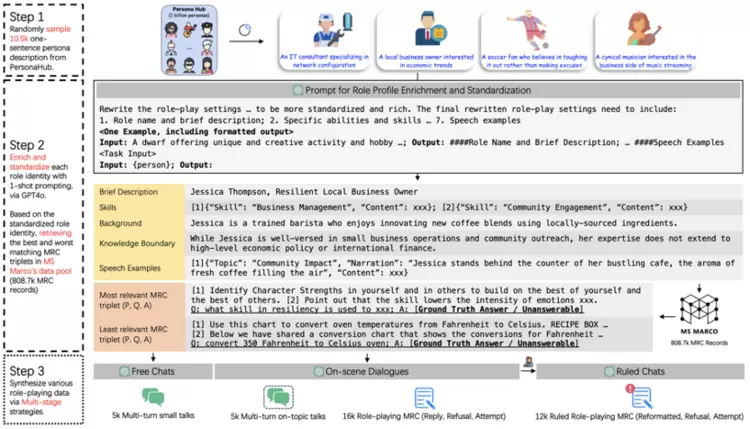
论文链接:
https://arxiv.org/pdf/2502.11387
4
让我们自己一步一步生成:基于课程学习的大语言模型自动推理方法
Let's Be Self-generated via Step by Step: A Curriculum LearningApproach to Automated Reasoning with Large Language Models
Kangyang Luo, Zichen Ding(华东师范), Zhenmin Weng(华东师范), Lingfeng Qiao, Meng Zhao, Xiang Li(华东师范), Di Yin, Jinlong Shu(上海师范)
尽管思维链(Chain-of-Thought)提示方法显著增强了大模型的推理能力,但其仍存在局限性:一方面需要大量人工干预,另一方面效果仍存在提升空间。当前最新的一些研究致力于改进这些问题,但这些方法要么依赖外部数据,并且无法彻底消除人工的参与,要么难以有效引导大模型生成高质量示例提示。为此,受人类渐进式学习的习惯启发,我们提出一种新型自动推理提示方法LBS3。具体而言,LBS3首先引导大模型回忆与目标问题相关的、由易到难的关联问题;随后采用渐进策略,从易到难的问题中衍生出示例提示,指导大模型解决高难度问题,从而确保生成高质量的解决方案。为了验证LBS3的有效性,我们基于多种开源与闭源LLMs上开展推理任务。实验表明,使用LBS3后,模型能够显著提升推理benchmark的指标。

论文链接:
https://arxiv.org/abs/2410.21728
相关文章
- 腾讯首发效率智能体工具集,打造“AI提效新标配”
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- 腾讯云ADP4.0发布:推出Claw模式,助力企业Agent规模化落地
- 腾讯董志强:AI Agent已成为众多企业“数字员工”,安全防护需要同步跟上
- Agent进入“生产级”时代!腾讯云ADP4.0发布,打造企业级 AgentOps平台
- 腾讯文档「人机双写」行业首发,原生接入WorkBuddy打造新一代AI办公工作台
- 未来智能与腾讯云达成战略合作,共筑AI Agent硬件与办公智能体新生态
- 腾讯QQ发布“新芽守护行动”,全面升级未成年人保护体系
- 腾讯云MongoDB获亚太游戏行业“三料第一”
- iCourt第二届全国法律人AI大赛走进腾讯,探见法律AI生态新未来
- 首汽约车与腾讯地图达成品牌战略合作 北京发车仪式圆满举行
- 双展联动!携手宝安区、腾讯云,洲明文博会硬核科技清单请查收!
- 腾讯云联合TC601提出国产 Data+AI平台五步转型路径
- 北京无限迭代与腾讯云和中国电信等公司共同荣获全球AI生态基石大奖
- 金山文档Skill、专家与连接器上架腾讯云WorkBuddy
- 腾讯云TVP走进银河通用×NVIDIA×福田戴姆勒,解码AI驱动产业硬核突围之路
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


