晟联科:以高速互连接口IP方案赋能Scale-up 生态
2025-09-12 15:21:53AI云资讯2750
9月11 日,D&R IP-SoC Days China 2025在上海淳大万丽酒店举办。作为D&R重要合作伙伴,晟联科携112G SerDes、PCIe 6.0及16G UCIe 三大高速接口 IP及解决方案亮相,并发表主题演讲,全面展示其在高性能计算、IOD 等领域的创新应用。

演讲直击:超节点崛起,IOD成破局关键
晟联科专家以《“战国时代” Scale-up 生态下的高速互联接口 IP 方案》为题,从生态趋势、IOD 价值到产品落地展开分享,引发全场关注。
当前 AI 算力需求爆发,传统架构面临 “单节点扩展受限、多芯片通信损耗大” 等瓶颈,超节点架构成为行业共识 —— 通过三大核心能力构建 Scale-up 生态 “性能底座”:
·高带宽域构建:64 卡组网实现多 GPU / 计算节点高密度互联,破解数据传输瓶颈;
·无损网络保障:集成 CBFC/PFC/LLR 技术,丢包率每降低 1%,模型训练推理效率提升 10%;
·超低延迟突破:端到端延迟控制在 500ns 左右,大幅提升训练与推理效率。
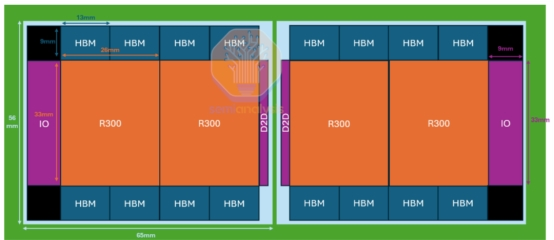
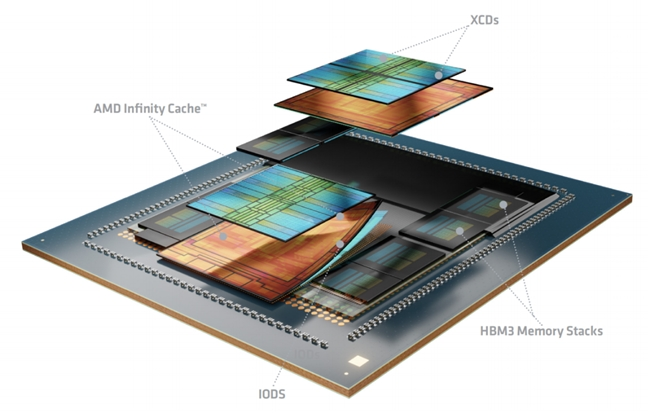
然而,国内外厂商自研协议(UALink、腾讯 ETH-X、移动OISA、英伟达 NVLink 等)并存导致接口不统一,IOD 架构成为关键解决。目前 NVIDIA Rubin 系列、AMD MI350 系列等头部 GPU 均已采用 IOD,通过 “计算 Die 与 IO Die 解耦迭代”,既缩短上市周期,又为算力Die预留更大面积空间。
▲NVIDIA Rubin和Rubin Ultra采用IOD架构
▲ AMD MI350 Series采用IOD架构
IOD 架构以 Scale-up 协议为核心,集成 SerDes(串行通信)、UCIe-AP (芯粒互联)、PCIe(对外互联)三大模块,关键指标亮眼:
•SerDes总带宽:112Gbps * 32lane = 3.2Tb/s
•PCIe总带宽:64Gbps * 16 = 1Tb/s
•UCIe-AP总带宽:32GT/s * 64pin * 3module= 6.0Tb/s
• 封装方式:Advanced Package
• 工艺:7/6nm
而GPU + IOD 框架进一步聚焦“算力核心(GPU)+互连枢纽(IOD)”协调,对接口 IP 的“高带宽、低延迟、兼容性” 提出更高要求 —— 这正是晟联科的核心优势所在。
晟联科:接口IP技术适配,Scale-up生态需求
展会上,晟联科 112G SerDes、PCIe 6.0、16G UCIe 三款 IP 方案,精准匹配超节点与 IOD 架构需求,成为现场焦点。
IP-SoC Days现场

112G SerDes:IOD 与超节点的 “高速数据通道”
同步满足 IOD 架构与超节点的互连需求,关键性能包括:
• 超长传输距离:高插入损耗信道下优异的BER性能
• 灵活可配:不同距离下实现最优的功耗和延迟
• 可靠性:优秀的pre-FEC和post-FEC误码率,经过多代硅验证
•从铜缆到光纤:支持IEEE802.3bj/cd/ck、InfiniBand EDR、OIF CEI-112G-LR/MR/XSR
16G UCIe:IOD 架构下的 “芯粒互联通用语言”
适配 IOD 架构Chiplet异构集成,关键性能包括:
•高速率:16GT/s-32GT/s
•低延时:快至2.x ns,FDI-to-FDI
•测试手段:提供Debug/CP/FT测试、错误注入、实时眼图扫描、多种Loopback
•兼容性:严格遵守UCIe 1.1/2.0规范
PCIe 6.0:IOD 与 Scale-up 生态的 “衔接枢纽”
可直接整合进 IOD 架构,关键性能包括:
•长距离:高插入损耗信道下可靠的传输
•优异性能:低功耗,低延时,面积小
•可靠性:PAM4 DSP PHY技术历经十多年技术架构演进,保障PCIe 6.0 IP的高可靠性
•PIPE v6.1:支持PIPE v6.1,与PCIe controller、CXL控制器兼容
赋能算力:链接“芯”未来
此次 D&R IP-SoC Days China 2025 之行,晟联科充分展现了中国高速接口 IP 企业的技术实力。未来,公司将持续迭代先进工艺与高速率方案,以 “易链天下,稳定快速” 的 IP 体验,助力全球客户加速算力创新。
相关文章
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


