端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
2026-03-19 20:08:08AI云资讯10386
今天,百度千帆正式发布全新端到端文档智能模型Qianfan-OCR。
该模型基于统一的视觉语言架构打造,以4B参数规模实现了对文档解析、版面分析、文字识别与语义理解的全面融合,在多项权威评测中取得领先表现,标志着文档智能能力正从“流程拼接”迈向“模型统一”的新阶段。
在核心Benchmark中,Qianfan-OCR表现尤为突出:在OmniDocBench v1.5上取得93.12分,端到端模型中位列第一;OCRBench远高于同尺寸通用VL模型和专用OCR模型;KIE(Key Information Extraction)在多个公开榜单的总和成绩超过Google Gemini 3-Pro等商用模型。
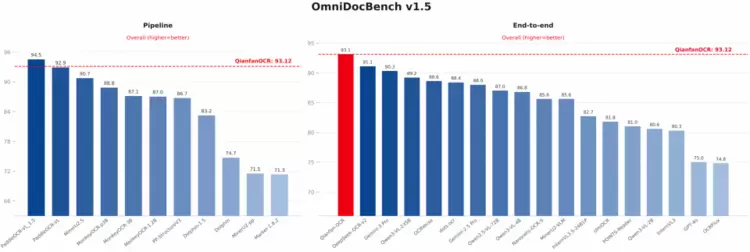
进一步来看,在图表理解等复杂任务中,端到端模型的优势更加明显。Qianfan-OCR在ChartQA、ChartBench等关键评测中表现领先,在6项任务中拿下5项最佳成绩,充分体现其在复杂结构理解与多模态推理上的能力优势。
这一结果的核心原因在于传统Pipeline在文本提取过程中往往会丢失空间结构与视觉上下文信息,从而限制了对图表与复杂文档的理解能力;而端到端模型能够完整保留视觉信息,使模型在结构理解与推理任务中具备更高的一致性与准确性。
整体来看,Qianfan-OCR在文档解析与理解一体化能力上的领先表现,进一步验证了端到端技术路线的可行性与先进性。目前,Qianfan-OCR已在千帆平台上线,并同步在HuggingFace开源模型权重,面向开发者与企业用户开放使用。
论文:
https://arxiv.org/abs/2603.13398
千帆平台:
https://console.bce.baidu.com/qianfan/modelcenter/model/buildIn/detail/am-52d29fea1063
HuggingFace:
https://huggingface.co/baidu/Qianfan-OCR
GitHub:
https://github.com/baidubce/Qianfan-VL
Qianfan-OCR文档智能skills:
https://github.com/baidubce/skills/tree/develop/skills/qianfanocr-document-intelligence
一个模型
重构文档智能能力边界
长期以来,工业级OCR系统大多沿用“检测—识别—理解”的三段式Pipeline架构:先通过检测模型定位版面元素,再由识别模型提取文本内容,最终借助大模型完成语义理解。这一模式在工程实践中已经非常成熟,但其本质仍是多阶段串联的处理流程。
随着文档形态日益复杂,这种架构的局限性也逐渐显现。一方面,多阶段处理带来的误差会在链路中不断放大,影响最终结果的稳定性;另一方面,文本在被逐块提取的过程中,原有的空间结构与视觉上下文被打散,使得图表、表格等复杂内容的理解能力受到限制。同时,多模型协同运行也显著增加了系统部署与运维的复杂度。
在这一背景下,Qianfan-OCR从底层架构出发进行了重构。通过统一的端到端视觉语言模型,系统可以直接从文档图像生成结构化结果,跳过传统的多阶段拆分流程,实现从“看见文档”到“理解文档”的一步完成。这一转变不仅大幅简化了技术链路,也为文档智能能力的提升提供了一条更高效、更一致的实现路径。
核心突破:
让模型具备
“版面理解能力”
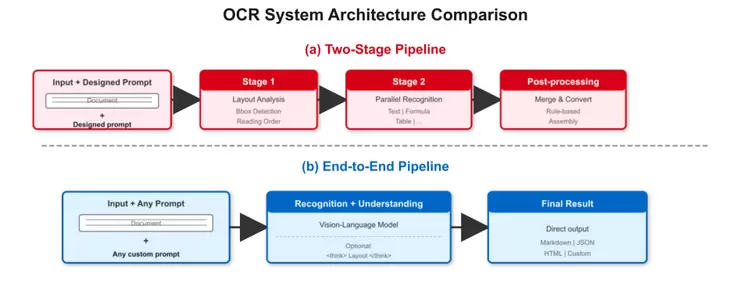
在端到端模型的演进过程中,一个核心挑战在于如何弥补传统Pipeline天然具备的版面分析能力。相比多阶段架构中显式的检测与结构解析过程,端到端模型往往缺乏对版面结构的直接建模能力。
针对这一问题,Qianfan-OCR提出了Layout-as-Thought机制,将版面理解能力内化为模型推理过程的一部分。在生成最终结果之前,模型通过<think>token进入“思考阶段”,先对文档结构进行显式建模,生成包括元素位置、类型以及阅读顺序在内的结构化信息,随后再完成整体解析输出。
这一设计使模型在统一框架下同时具备结构感知与语义理解能力。一方面在端到端架构中补齐了版面分析这一关键能力;另一方面通过引入结构先验信息,有效提升了复杂文档场景下的解析准确性与稳定性。
因此在多栏排版、复杂表格以及非标准阅读顺序等典型复杂场景中,Qianfan-OCR能够表现出更强的鲁棒性与一致性。此外在部署效率上,单张A100 GPU,W8A8量化,吞吐量达1.024页/秒;相比pipeline系统需要CPU做检测+GPU做识别+GPU做LLM的异构编排,Qianfan-OCR只需一个vLLM实例。
从OCR到文档智能:
范式正在发生变化
Qianfan-OCR的发布,不仅是一次模型能力的升级,更体现了文档处理技术路径的演进:从多模型拼接的流程式架构走向统一建模的端到端范式。这一变化使文档智能从“工具能力”进一步演进为“系统能力”,也为企业级应用提供了更高效、更稳定的技术基础。
同时,Qianfan-OCR模型已在GitHub发布配套skills,用户可自行下载使用,为自己的小龙虾“加点技能”,轻松实现文档转化与理解。
未来,百度千帆将持续推进多模态模型在产业场景中的落地应用,推动AI能力在更广泛行业中释放价值。
相关文章
- 华硕商用电脑联手百度智能云,发布企业级AI办公解决方案
- 百度发布2026年Q1财报
- 百度智能云与帕西尼达成战略合作 共同推动具身智能产业规模化落地
- 百度智能云:加大三方面投入 解决具身智能产业硬问题
- 百度沈抖:自我进化,开启超级个体黄金时代
- 百度一镜升级,数字人进入“全场景+全球化”时代
- 百度智能云升级百度一见视觉智能体平台:内置1000+专业视觉Skills,可自主进化
- 百度智能云发起智慧养老产业联盟,8家企业首批加入
- 百度Create2026:AI Agent走进家庭,小度给出落地样本
- L4级自动驾驶车辆驶入中国农业大学 百度Apollo星火计划再落一子
- 百度百科20周年沙龙致敬百万UGC用户:让3000万+词条成为时代的知识方舟
- AI生万象,灵感疯长——百度百家号AI创作者漫谈大会圆满落幕
- 2026百度创作者大会:AI引擎赋能创作 共生共筑新生态
- 领跑中国乘用车NOA辅助驾驶地图市场份额 百度地图实力亮相2026北京车展
- 百度百科“繁星计划”再加码,投入2000万基金激励权威内容建设
- 行业首发!鸿蒙版雅迪智行App深度集成百度地图SDK,上线投屏导航,实现“抬头骑行,眼不离路”
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


