云知声 U2-ASR 2.5上线:首个中文方言语义转写大模型
2026-05-13 10:41:44AI云资讯2171
今年1月,云知声发布了山海·知音2.0,作为云知声面向真实语音世界打造的旗舰语音大模型,其凭借全场景ASR、高拟人TTS与全双工毫秒级响应三大核心能力,重新定义了人机交互的性能基准。
今天,历经多轮算法迭代与大规模地域语料的针对性训练,山海·知音2.0完成新一轮能力升级,正式推出首个中文方言语义转写大模型——U2-ASR2.5,全面覆盖七大方言体系,支持100种以上方言及地方口音识别转写,方言人口覆盖率高达90%以上。在此基础上,模型进一步打通“方言识别-语义还原-普通话表达”链路,支持将晦涩、口语化、地域化的方言表达转化为规范、准确、可理解的普通话文本,让AI不只听清方言,更能真正听懂大江南北。
最新一轮评测中,U2-ASR 2.5交出了一份足够硬核的方言识别成绩:在自有工业级方言测试集上,山海·知音整体识别效果全面超越主流ASR模型,从北方方言到西南官话,从粤语到华中口音,其多项方言识别准确率突破 90%:济南话识别准确率高达 96.2%,四川话达到94.7%,粤语达到 93.0%,武汉话达到 92.1%,充分验证了山海·知音在口音差异显著、地域表达复杂、方言与普通话混合使用频繁等挑战性场景下,具备业内领先的方言ASR基础能力。
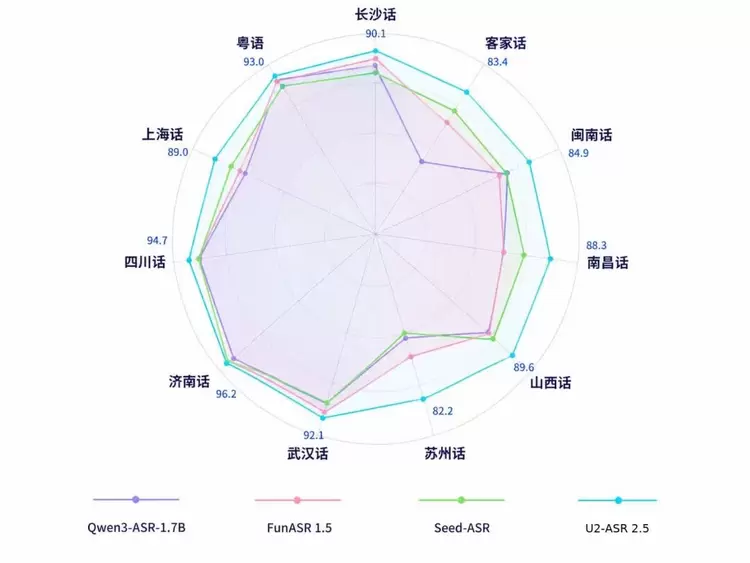
工业级测试集测试结果
与此同时,U2-ASR 2.5在通用中英文识别任务中同样表现强劲:在 AISHELL、FLEURS、LibriSpeech、WenetSpeech Meeting、KeSpeech 等公开测试集上,模型持续取得优异成绩,其中AISHELL-1达到 99.2%,Libri Clean达到 98.4%,AISHELL-3达到 98.4%。这意味着,模型并不是在通用ASR能力之外简单叠加方言识别,而是在扎实的中英文语音识别底座上,进一步向方言这一高难场景拓展。
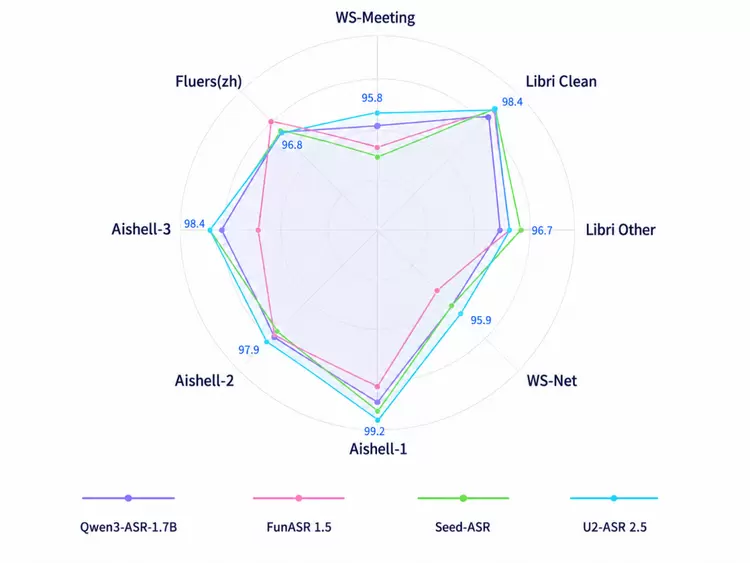
中英文公开测试集测试结果
而此次升级的关键突破在于,在完成方言语音转写的基础上,模型进一步引入方言词义映射、上下文意图识别与普通话语义还原能力,能够将晦涩、口语化、地域化的方言表达,转化为更规范、更准确、更易理解的普通话文本。
01 技术解构:如何实现“方言通”?
方言识别之所以难,是因为它面对的不是一套标准化语言,而是真实世界中极其复杂的声音样本和表达方式。
不同地区、不同年龄、不同语境下,同一种方言都可能存在明显差异;同一个词,在不同地方可能发音不同、写法不同、含义也不同。再叠加录音设备差异、环境噪声、语速变化、方普混说等因素,方言ASR从一开始就不是简单的语音转文字任务,而是一项系统性的语音理解工程。
针对这一工程挑战,U2-ASR 2.5围绕数据、解码与语义理解三条关键链路进行了系统性优化:
●数据:先把真实世界的声音教给模型
方言识别的难点,往往不在模型本身,而在数据。
相比普通话语料,方言数据天然面临样本分散、录音条件不一、转写标准不统一,以及同音异形、借词混说更频繁等问题。围绕这些挑战,我们构建了“真实数据收集+公开语料补充+半监督扩增+人工校准”的数据治理闭环,通过 VAD、降噪、去重、语段切分与置信度过滤等多环节处理,提升可训练数据的纯度与一致性,并结合语音合成与数据增强技术扩大样本规模。
针对同一方言内部“十里不同音”的现实,模型训练不再按方言名称做粗粒度划分,而是在统一语音底座上,通过跨区域采样与发音变体建模,让模型学习可迁移的发音规律,而非依赖少数样本的口音模板,从而在更大方言区间内保持稳定识别。
●解码:在混合语境中保持连续与稳定
真实对话里,方言、普通话、英语往往不是分段出现,而是以词级、短语级形式交替穿插。为此,我们引入了更细粒度的语言边界检测,实现三大技术创新:
一是在模型输入层引入语种边界预测模块,实时预判语种切换发生的时间点;二是设计了动态语种注意力机制,在解码过程中根据当前语音特征自动调整对方言、普通话、英语三类语言模型的权重分配;三是构建了数万小时级的语种切换语料库,覆盖常见的方言-普通话混合表达模式。
●从听清到听懂:语义层能力升级
此次升级不仅停留在“听清说了什么”,更进一步走向“理解在说什么”。
在完成方言语音转写的基础上,我们通过方言词义映射、上下文意图识别以及多源知识融合,对原始表达进行语义还原,输出更易理解的普通话文本。
这意味着,我们的大模型不只是逐字记录方言内容,而是能够在保留原始表达的同时,对其进行规范化解释,从而为后续的意图理解、任务执行等能力提供更清晰、可用的输入基础。
从这个角度看,U2-ASR 2.5不只是ASR模型的识别能力升级,更是语音理解能力的一次跃迁。
02 从“能识别”到“稳识别”:方言语音的工程化挑战
在真实业务中,模型不仅要识别得准,还要在噪声、设备差异、多语音并发、长时间运行等复杂条件下保持稳定。云知声更关注的,正是语音能力能否从实验室测试走向工业级落地。
围绕这一目标,U2-ASR 2.5构建了贯穿前端信号处理、模型适配、热词增强、推理优化与后端纠错的全链路工程化体系,让方言识别不仅“分数高”,更能“用得稳”。
●高识别率:先赢在准确率,再赢下复杂场景
在方言语音识别中,准确率不仅取决于模型是否“听见”方言,更取决于其能否在口音差异、方普混说、口语化表达等复杂输入中稳定理解用户意图。
从官话、晋语到吴语、湘语,从赣语、闽语到客家话、粤语,U2-ASR 2.5 面向多类主要中文方言体系持续扩展能力边界,覆盖南北多区域、多语系、多口音的真实表达场景,并在代表性体系样本中展现出更稳定、更准确的方言识别能力,在自有工业级方言测试集上,其综合识别表现整体领先主流ASR 模型。
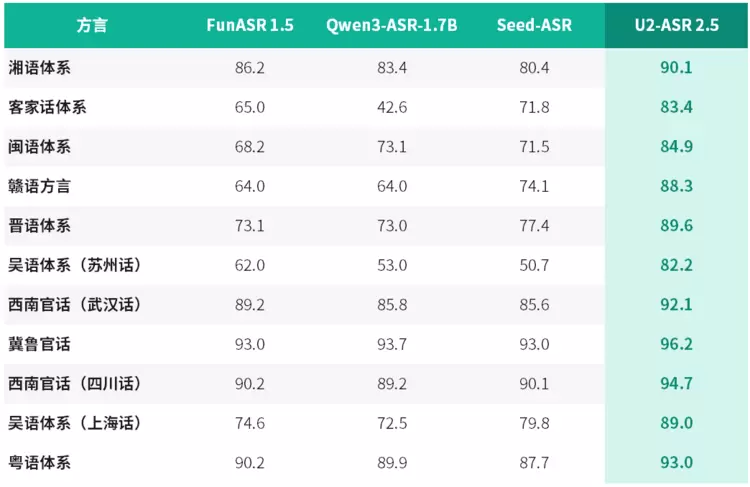
工业级测试集测试结果
同时,U2-ASR 2.5在 AISHELL、LibriSpeech、FLEURS 等中英文公开测试集上同样保持优异表现,进一步验证了其扎实的通用 ASR 底座能力。
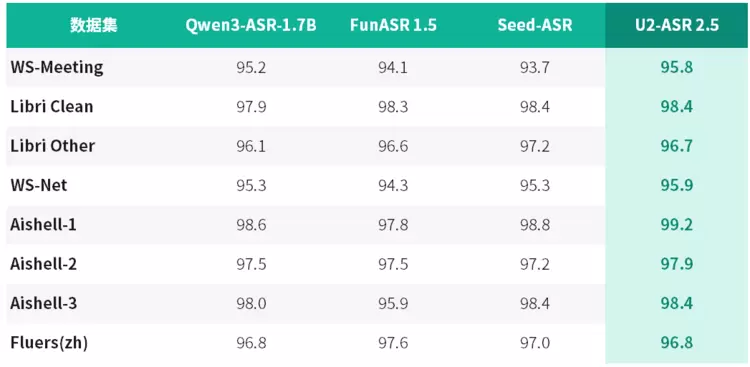
中英文公开测试集测试结果
这意味着,U2-ASR 2.5不是只在单一方言上“刷高分”,而是在更广泛、更复杂、更接近真实世界的语音场景中持续领先。它能覆盖更丰富的地域表达,也能适应更复杂的口音差异,让方言语音识别从“可用”进一步走向“好用”。
●高噪识别:听得懂夜市,也听得懂医院候诊区
真实世界从来不是录音棚。在早点摊、夜市、政务大厅、医院候诊区、客服中心等场景中,背景音复杂、说话人距离不一、多人声音交叠,传统 ASR 模型很容易出现漏识、错识和语义断裂。
U2-ASR 2.5在语音进入模型前,通过多通道降噪、自适应回声消除与非稳态噪声优化,对复杂声学干扰进行预处理,在压制噪声的同时尽可能保留有效语音信息。同时,结合鲁棒性建模与端点检测优化,模型能够更准确地捕捉有效语音,降低设备差异和环境噪声带来的影响。即使在高噪声、高干扰的真实场景中,也能保持较高识别稳定性。
●专业增强:听得懂方言,也听得懂业务
在医疗、政务、客服等场景中,用户表达往往不只是方言,还会夹杂大量专业词汇、业务术语和专有名词。
云知声支持热词动态注入与行业词表适配,可针对医疗、政务、客服等专业场景,对高频术语、专有名词和业务关键词进行识别增强,降低误识别概率,让方言识别结果更贴近业务语义。
这也是U2-ASR 2.5区别于普通ASR模型的重要能力:不仅懂语言,也懂场景。
● 低延迟响应:识别更强,也要响应更快
U2-ASR 2.5通过模型量化、算子融合、流式解码与服务端并发调度优化,压缩推理链路,降低复杂方言识别带来的计算开销。同时,结合重打分与纠错机制,对人称代词混用、语气词误识、口语化表达等细粒度问题进行校验与修正,使输出结果不仅更快,也更稳定、更可用。
03 应用场景:让技术回归“人”的温度
在中国,方言依然是许多人日常交流中最自然、最熟悉的表达方式。尤其在政务、医疗、客服、适老化服务等场景中,语言习惯的差异,仍可能影响信息传递的效率与服务体验。
进入大模型时代,语音交互不应只适应标准表达,也应更好地理解真实人群的自然表达——
智慧政务:在基层政务窗口、便民服务终端等场景中,群众往往更习惯用方言表达诉求。U2-ASR 2.5可帮助系统更准确地理解方言表达,并转化为规范、可处理的普通话文本,减少反复沟通带来的理解成本,让公共服务更自然地触达不同地域用户。
智慧医疗:在医院导诊、问诊记录、随访沟通等场景中,患者的口音、表达习惯和专业词汇交织在一起,容易影响信息记录与理解效率。通过抗噪声优化与医疗热词增强,U2-ASR 2.5可辅助系统更稳定地识别患者主诉和关键信息,降低因口音差异带来的沟通成本。
智慧金融保险:在银行、保险、理赔等场景中,用户表达往往包含方言口音、口语化描述、金融保险术语与复杂业务信息,一旦关键信息识别不准,就可能影响后续核验、审核与服务效率。U2-ASR2.5可结合方言识别、专业热词增强与语义理解能力,更稳定地识别理赔、疾病名称、赔付范围、费用明细等关键信息,并将口语化、方言化表达转化为规范、可处理的普通话文本,增强理赔材料整理与风险审核等业务的准确性、可追溯性与服务可信度。
智慧客服:在方言使用高频区域,用户并不总是愿意或能够切换为标准普通话。面向热线客服、智能外呼、智能坐席等场景,U2-ASR 2.5可支持更自然的方言表达识别,帮助客服系统更快理解用户需求,减少重复确认,提升服务效率与交互体验。
文旅与内容创作:在文旅宣推、纪录片制作、地方文化记录等场景中,大量真实、生动的方言素材往往难以被高效整理和传播。U2-ASR 2.5可将方言语音转化为更易理解、可编辑、可检索的文本内容,为地方文化传播、非遗记录和内容生产提供新的技术支撑。
每一种方言,都是一套完整的意义系统,承载着当地的生活经验与文化记忆。理解方言,不只是识别一段声音,更是在复杂口音、混合表达与真实语境中,准确捕捉用户的意图。此次上线U2-ASR 2.5,正是云知声从“听清”迈向“听懂”的一次探索。
未来,云知声将持续拓展方言语音能力,覆盖更丰富的地域表达、更复杂的真实场景与更多元的人群需求,让AI真正听懂每一个人的自然表达。
目前,包含U2-ASR 、U2-TTS、U2-TTS-Clone在内的山海·知音系列模型已全量上线云知声Token Hub大模型服务平台,开放标准API,支持一键接入、按需调用,按Token计费,灵活可控。
相关文章
- 云知声 U2-ASR 2.5上线:首个中文方言语义转写大模型
- 云知声U2Claw:桌面AI Agent,更安全、更省Token的超强SOTA龙虾
- 博鳌论道!云知声CEO黄伟登全球顶级舞台,解码AI普惠与产业变革新范式
- 全员顶尖大模型及AI 编程工具保障,云知声开启 AI Native 组织进化
- 云知声三大核心Skill登陆ClawHub,文档解析+全场景ASR+TTS三重赋能智能体高效办公
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 云知声确定性业绩筑牢价值基石,稳健增长印证长期信心
- AGI技术+地铁服务!云知声助力济南地铁打造全国首个远程集中式智能客服,让出行更智慧
- 深度观察|云知声“山海·知音”2.0破解大模型落地“最后一公里”
- 智启山海 交互无界|云知声山海·知音2.0重磅发布,三大能力进化
- 智启山海,交互无界——云知声山海·知音 2.0 重磅发布
- 云知声荣登2025中国人工智能企业前30强,稳居行业第一梯队
- 云知声深度参与杭州市富阳区人工智能高质量发展大会,以“链主”担当助推区域AI生态繁荣
- 实力领跑AI应用落地!云知声荣耀入选《2025爱分析・Agent厂商全景报告》三大领域
- AI产业拐点下技术落地提速,云知声山海大模型赋能千行百业
- 云知声CEO黄伟斩获2025年度“安永企业家奖”殊荣,诠释新时代企业家精神
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


