基于视觉深度估计的伪激光雷达: 从2D图像到自动驾驶3D目标检测 (IROS)
2019-07-09 09:33:16AI云资讯1589
三维目标检测是自动驾驶中的一项重要任务。如果三维输入数据是从精确但昂贵的激光雷达技术中获得的,那么最新的技术具有很高的准确检测率。到目前为止,基于更便宜的单目或双目图像数据的方法已经导致了精确度大大降低——这一差距通常归因于基于图像的深度估计不佳。然而,在本文中,我们认为,数据的质量并不是数据本身的质量问题,而是数据的表示性能,这是造成差异的主要原因。考虑到卷积神经网络的内部工作,我们建议将基于图像的深度图转换为伪激光雷达表示——本质上模拟激光雷达信号。通过这种表示,我们可以应用不同的现有的Lidarbased检测算法。在广受欢迎的Kitti基准测试中,我们的方法在基于图像的性能方面取得了显著的改进,使30米范围内的物体检测精度从以前的22%提高到目前的74%。提交时,我们的算法在基于立体图像的方法的Kitti 3D物体检测排行榜上占有最高的位置。
主要贡献
首先,我们根据经验证明,立体和基于激光雷达的三维目标检测之间性能差距的主要原因不是估计深度的质量,而是它的表示。其次,我们提出了伪激光雷达作为一种新的三维物体探测深度估计的建议表示,并表明它导致了最先进的立体三维物体探测,有效地将现有技术提高了三倍。我们的研究结果指向了在自动驾驶汽车中使用立体摄像机的可能性——可能会大幅降低成本和/或提高安全性。
算法流程
我们提出了一种基于立体的三维物体检测的两步方法。我们首先将立体或单目图像的估计深度图转换成三维点云,我们称之为伪激光雷达,因为它模拟激光雷达信号。然后,我们利用现有的基于激光雷达的三维目标检测管道框架,我们直接在伪激光雷达表示上进行训练。通过将三维深度表示改为伪激光雷达,使基于图像的三维目标检测算法的精度得到前所未有的提高。
尽管基于图像的三维物体识别有许多优点,但在图像的最新检测率和基于激光雷达的方法之间仍存在着明显的差距。人们很容易将这一差距归因于激光雷达和照相机技术之间明显的物理差异及其影响。我们提出了一种基于立体的三维物体检测的两步方法。我们首先将立体或单目图像的估计深度图转换成三维点云,我们称之为伪激光雷达,因为它模拟激光雷达信号。然后,我们利用现有的基于激光雷达的三维目标检测管道框架,我们直接在伪激光雷达表示上进行训练。通过将三维深度表示改为伪激光雷达,使基于图像的三维目标检测算法的精度得到前所未有的提高。
1.深度估计
使用基于图像合成的深度估计算法,双目相机和单目相机可以在框架中使用.
2.伪激光雷达的产生
我们不需要像通常那样将深度d作为多个附加通道合并到RGB图像中,而是可以在左相机坐标系中导出每个像素(u;v)的三维位置(x;y;z),如下所示:
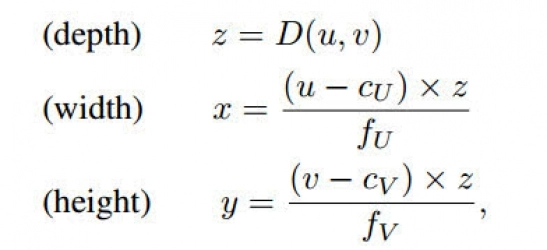
激光雷达与伪激光雷达。为了最大限度地兼容现有的激光雷达检测管道,我们对伪激光雷达数据应用了一些额外的后处理步骤。由于真实的激光雷达信号只存在于一定的高度范围内,我们忽略了超出该范围的伪激光雷达点。

3.3D目标检测
利用估计的伪激光雷达点,我们可以将现有的基于激光雷达的三维目标探测器应用于自主驾驶。在第一个步骤中,我们将伪激光雷达信息视为三维点云。这里,我们使用截锥点网,它将二维对象检测投影到三维截锥中,然后应用点网提取每个三维截锥的点集特征。
在第二个步骤中,我们从鸟瞰图(BEV)中查看伪激光雷达信息。尤其是,三维信息从上下视图转换为二维图像:宽度和深度成为空间尺寸,高度记录在通道中。AVOD将视觉功能和BEV激光雷达功能连接到3D盒子方案中,然后将两者结合起来进行盒子分类和回归。
4.数据表示问题
尽管伪激光雷达传输的信息与深度图相同,但我们认为它更适合于基于深度卷积网络的三维目标检测管道。为此,考虑卷积网络的核心模块:二维卷积。在图像或深度图上操作的卷积网络在图像深度图上执行二维卷积序列。尽管可以学习卷积的过滤器,但中心假设是双重的:(a)图像中的局部邻里有意义,并且网络应该查看局部区域;(b)所有邻里都可以以相同的方式操作。
在左列中,我们显示了原始深度图和图像场景的伪激光雷达表示。场景中的四辆车以彩色突出显示。然后,我们在深度图(右上角)上用一个盒子滤波器执行一个11×11的卷积,它与5层3×3卷积的接收场相匹配。然后我们将得到的(模糊的)深度图转换为一个伪激光雷达表示(右下角)。从图中可以明显看出,这种新的伪激光雷达表示受到了模糊的影响。
主要结果
我们通过不同的深度估计和目标检测方法,评估了在不同设置下有无伪激光雷达的三维目标检测。在整个过程中,我们将突出显示蓝色的伪激光雷达和灰色的实际激光雷达的结果。
1.3D目标检测结果
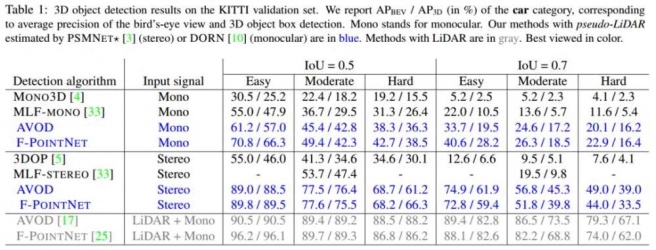 表1KITTI目标检测结果
表1KITTI目标检测结果
2.对比
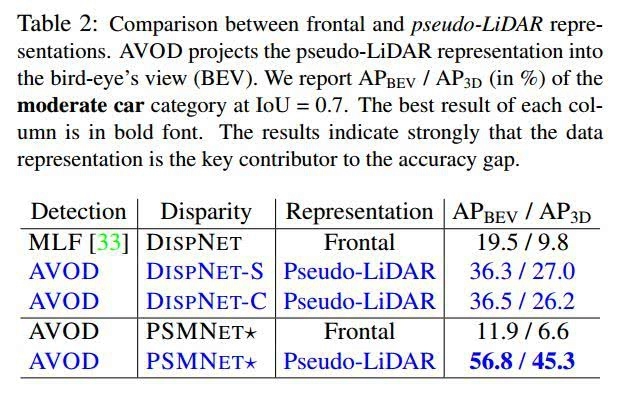 表2 frontal 和伪激光雷达对比
表2 frontal 和伪激光雷达对比
3.比较立体视差和三维目标检测算法的不同组合,使用伪激光雷达。在IOU=0.7时,我们报告了中等车辆类别的APBEV/AP3D(百分比)。每列的最佳结果是粗体。
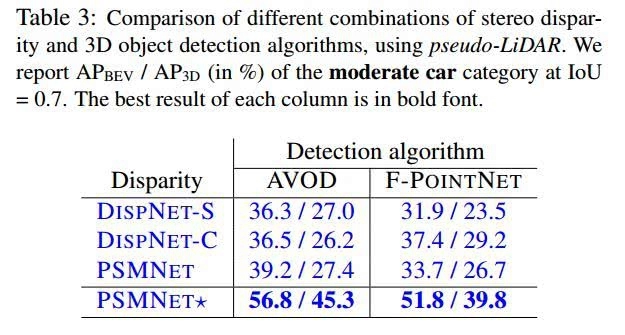
表3比较立体视差和三维目标检测算法的不同组合
4.验证集上行人和自行车手类别的三维对象检测。我们报告的apbev/ap3d为iou=0.5(标准度量),并将f-pointnet与psmnet(蓝色)和lidar(灰色)估计的伪激光雷达进行比较。

图2 3D目标检测效果

图33D目标检测效果2

图4 PSMNET* 与PSMNET对比
相关文章
- 视觉中国发布2025年度ESG报告
- 圆偏光护眼黑科技落地!飞利浦商用显示器关爱职场人的视觉健康
- Vision China 2026(上海)机器视觉展盛大开幕!
- 卓特视觉AI视觉赋能,共筑家用服务机器人新生态
- 中科融合完成近亿元融资,光学芯片量产赋能3D视觉与AI微显
- 视觉+压缩双引擎驱动,度申科技亮相Vision China 2026
- 华感科技热成像机芯视觉引擎再突破,引领红外技术迈向新高度
- 天翼视联视觉智安实验室正式揭牌 重塑视联网行业安全生态格局
- 视觉空间大模型如何与产业深度融合,兔展智能给出AI落地新范式
- Ultralytics Platform正式发布:一站式端到端视觉 AI 平台
- AI视觉重塑竞技体育记录方式,XbotGo猎鹰Falcon新品发布
- 英伟达发布新一代超分辨率技术DLSS 5:神经渲染加持,颠覆性视觉提升
- 硬核无损透视与3D视觉,如何在AI时代定义智能检测新标准?
- 宇视科技闪耀2026 ISLE展,AISD智慧显示重构视觉全链路
- 搭载双目视觉和热活水履带技术,云鲸JX打造3K价位段清洁天花板
- 五载同行!LED+AI+XR,揭秘2026春晚视觉幕后的“洲明力量”