最高10倍加速!北京大学联合腾讯优图实验室将 GQA 改造成 MLA形式
2025-06-25 17:13:11AI云资讯5046

1
前言
Multi-Head Latent Attention(MLA)随着DeepSeek的火爆,成为大家关注的热点。然而DeepSeek V2原文中只通过消融实验验证MLA的训练效果好于MHA,并没有为此提供理论保障。研究人员纷纷下场研究不同设计的能力对比,例如苏剑林提出三个猜想,并通过实验验证注意力头的维度是关键因素[1]。
2
GQA v.s. MLA
本文直接通过理论证明了,给定相同的KV Cache下,MLA的表达能力总是超过目前广泛使用的Group-Query Attention(GQA)。证明思路如图1所示:GQA能够等价转换为MLA,反之无法用GQA表示所有的MLA。
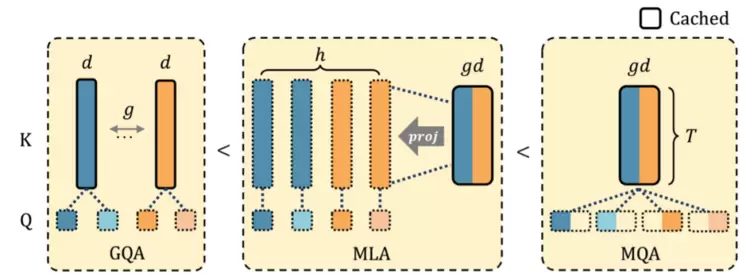
图1给定相同的KV Cache预算,GQA的表达能力小于MLA,小于MQA。
我们将Qwen2.5中的GQA等价转换为MLA,在SmolTalk数据集上进行训练。转换前后的模型,在训练过程中的Loss以及训练后模型的效果如图2所示。
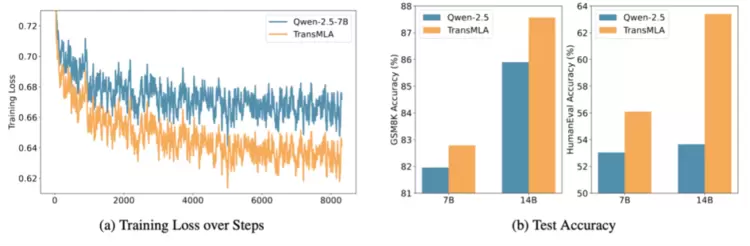
图2将Qwen2.5中的GQA等价转换为MLA,在下游任务中训练的效果对比。
从图中可以看出,经过转换的MLA模型在训练过程中表现出更低的Loss值,表明其对训练数据的拟合能力更强。最终基于MLA的模型在数学和代码任务上的准确率显著高于原始的基于GQA的模型。
3
TransMLA
GQA等价变为MLA能提升模型的表达能力,但并未减少模型的KV Cache。因此并不能提升推理速度,阻碍了TransMLA的实际应用价值。因为通常我们更希望获得一个预训练时强大,推理时高效的模型。因此我们通过如图3所示的RoRoPE、FreqFold和BKV-PCA三项创新,实现了:
1)压缩LLaMA-2-7B 93%的KV Cache;
2)性能损失很小,通过少量训练即可恢复;
3)无需优化,直接使用DeepSeek模型加载,在多个硬件上实现5-10倍加速。

图3TransMLA先将位置信息集中到第一个head,再对KV进行低秩压缩。
整个转换过程为:
1.分组合并。将分组的KV拼接为一个Latent表示,并将分组的RoPE拼接为RoPE'。
2. Decouple RoPE。将RoPE'分为RoPE和NoPE,将位置信息集中到RoPE head,去除NoPE部分的位置编码。
3.压缩KV。对K_rope与 V的大小进行平衡后,进行联合低秩压缩。其中RoRoPE表示我们可以在RoPE'两端对QK进行旋转,只要满足:1)旋转只发生在不同K head的相同维度,2)RoPE'的实部和虚部对应的维度需要使用相同的旋转方式。RoRoPE通过这一特殊旋转方式将K的主成分集中到一个头,去除其他头的位置编码,重新使用一个标准的RoPE表示位置信息。
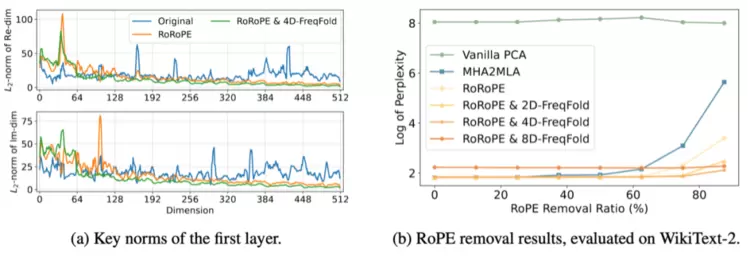
图4RoRoPE能够将多个K head的信息集中到第一个注意力头中,从而以很小的误差将其分割为K_rope和K_nope
如图4(a)中黄线所示,使用RoRoPE后输出分布集中在原来的第一个头。绿线使用一种频率近似的方法,使分布更集中在原来的第一个头中。如图4(b)使用RoRoPE裁剪至一个头(128维)的效果显著好于没有进行主成分提取的MHA2MLA[2]。
4
实验
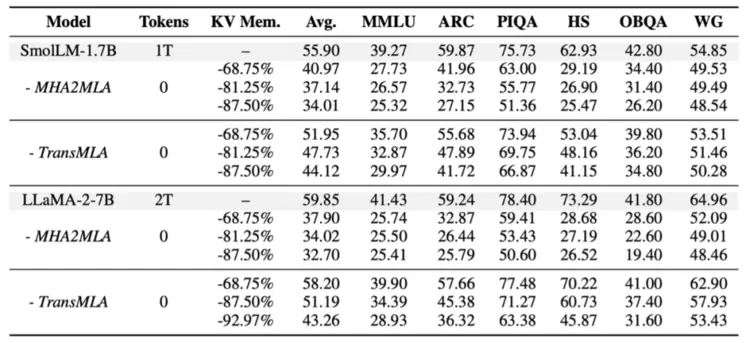
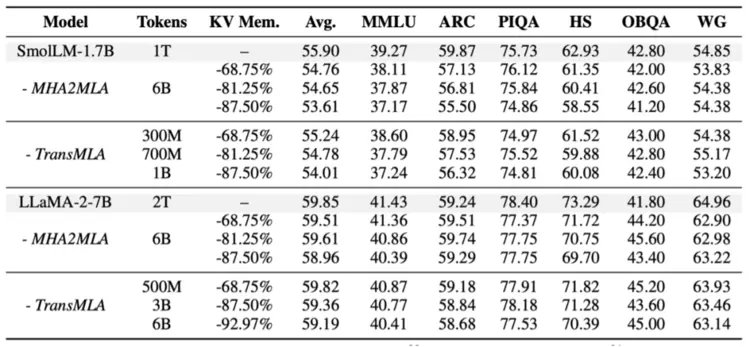
TransMLA减少转换过程的性能损失,能够轻易通过训练恢复效果我们在SmolLM-1.7B和LLaMA-2-7B上验证TransMLA的效果,使用同期工作MHA2MLA作为对比。由于TransMLA使用的RoRoPE、FreqFold和BKV-PCA显著减少转换时的误差,如表1所示,裁剪LLaMA-2-7B 68.75%的KV Cache,无需训练,在6个benchmark上只损失1.65%的效果,而MHA2MLA则损失约21.85%的效果。
表1直接将模型转换为MLA,使用TransMLA和MHA2MLA的效果对比。
如表2所示,由于TransMLA转换后对模型的破坏更小,因此只使用500M Tokens的训练即可超过使用6B Tokens训练的MHA2MLA。
表2通过少量训练后,使用TransMLA和MHA2MLA的效果对比。
DeepSeek模型直接加载TransMLA的Checkpoint,轻易的使用vllm加速
不同于其他KV Cache压缩方法需要专门定制推理框架,TransMLA将所有的模型都统一转换为DeepSeek模型。利用其丰富的生态,只要能支持DeepSeek的硬件和环境,就能支持TransMLA的推理加速。目前我们实现了Transformers和vllm版本的代码,未来将会在SGLang等其他框架上进行测试。
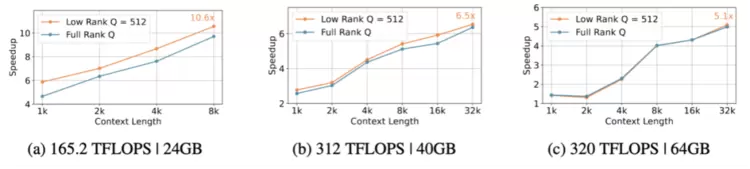
图5TransMLA裁剪LLaMA-2-7B 92.97%的KV Cache,在不同的硬件环境上的加速比。
如图5所示,仅仅将LLaMA-2-7B转为MLA,就带来了最多10.6x推理加速。未来我们将会结合DeepSeek的混合精度量化,MTP等技术进一步优化模型推理速度。
TransMLA已经支持了主流的模型TransMLA已经支持Llama、Qwen、Gemma、Mistral/Mixtral等主流模型,转换代码已经开源,近期将通过训练恢复模型效果,发布MLA加速版本的基座模型。
TransMLA支持Grouped Latent Attention(GLA)近期flash attention和Mamba作者发布的GLA[3]充分发挥了tensor parallel的优势,推理速度能比MLA快2倍。然而他们将这一方法定位为一个从头预训练的架构,从头训练GLA需要巨大的成本。我们指出,MLA模型,包括DeepSeek以及使用TransMLA转化的模型,通通可以转化为GLA模型。
DeepSeek-V2-Lite原始模型在wikitext2上的ppl为6.3102,直接使用原始GLA的实现加载的ppl为21.0546,这可能是其未提供直接加载DeepSeek模型效果的原因。我们通过解决tensor parallel时RMSNorm和Softmax分割的问题,将ppl降低到了7.2416,通过少量训练即可恢复模型效果。接下来我们将会在DeepSeek V3/R1上进行实验,尽量维持满血DeepSeek能力,同时提升推理速度。
5
总结与展望
本文理论证明了MLA的表达能力大于GQA,呼吁基座模型全面转为MLA架构。同时提供一种将存量GQA模型转换为MLA模型的方法,减少迁移所需的成本。此外将会完善GQA/MHA/MLA转GLA的方法,尝试突破DeepSeek的能力边界。
6
引用
[1] Transformer升级之路:20、MLA究竟好在哪里?https://kexue.fm/archives/10907
[2] Towards Economical Inference: Enabling DeepSeek's Multi-Head Latent Attention in Any Transformer-based LLMs
[3] Hardware-Efficient Attention for Fast Decoding
相关文章
- AI智能体从概念走向落地 赞同科技CTO蒲云出任腾讯云AI智能体嘉年华(华东赛区)专家评委
- 领驭科技×腾讯云联合亮相2026深圳国际眼镜业博览会
- 腾讯云发布边缘Web与AI Agent托管平台 EdgeOne Makers:一键开发部署,分钟级全球上线
- 中国企业创新盘点——同时入选《财富》中国科技50强的联想集团与华为、腾讯、阿里
- 腾讯云TVP走进香港数码港,解码AI出海新范式
- 腾讯云以 99.8% 防护率通过AV-C年度评测
- 值得买科技与腾讯云深化“AI+消费”合作,首个消费决策Skills上线腾讯WorkBuddy
- 一码三端!HDC 2026腾讯视频鸿蒙版跨端方案重磅公布
- 李未可AI眼镜成为腾讯云WorkBuddy首批生态伙伴,加速终端入口商业化落地
- 打破传统网络边界,飞猫引入腾讯云聚通加速能力破解游戏延迟难题
- 腾讯首发效率智能体工具集,打造“AI提效新标配”
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- 腾讯云ADP4.0发布:推出Claw模式,助力企业Agent规模化落地
- 腾讯董志强:AI Agent已成为众多企业“数字员工”,安全防护需要同步跟上
- Agent进入“生产级”时代!腾讯云ADP4.0发布,打造企业级 AgentOps平台
- 腾讯文档「人机双写」行业首发,原生接入WorkBuddy打造新一代AI办公工作台
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


