反低俗是世界难题,今日头条“灵犬”的嗅觉凭什么那么灵?
2019-08-08 16:49:30AI云资讯1346
也就是说,无论是输入文字还是上传图片,“灵犬”都能够进行低俗色情、暴力谩骂、标题党等相关低俗低质元素的检测,并给出相应的健康度鉴定结果。
无论是长达数千字的文本,还是信息含量更加丰富的图片,“灵犬”都能够在短短几秒钟检测完毕,并且据说综合准确率高达85%以上。这只“狗子”不仅能识文断字,更能独自进行看图理解。
表面上,“灵犬”只是今日头条旗下的一款小产品,以小程序的形态出现在今日头条和微信里。内容创作者们可以用它来检测自己创作的内容是否包含低俗信息,普通用户也可以参与到“打击低俗”这项看似复杂的工作中来。
事实上,“灵犬”在做的是一件全球内容平台共同在面对的难题:在内容创作如井喷一样增长的环境下,如何在既追求内容发布速度、又追求内容质量的前提下,平台方如何做好内容的审核管理工作?
“灵犬”初体验:小程序如何反低俗?
在体验“灵犬”的检测功能时,我们发现这只“灵犬”可以用喜、怒、哀、乐等各个不同的表情来和你对视。
如果上传的内容不健康,“灵犬”肯定会怒气冲冲地看着你,给你一份健康概率极低的鉴定结果;如果上传的内容是健康的,“灵犬”会”微赠送微笑一枚,并给你一份健康概率正常甚至健康概率颇高的鉴定结果。
灵犬所认为的“不健康”大致可以分为几个方面: 低俗色情、暴力谩骂或者标题党。相反,不包含这些元素的信息,则有理由被“灵犬”认定为健康的。
我们从网上找了一些网络低俗话语和一些正常语句,准备试试灵犬能否准确地分辨出来。
我们首先测试了这一句”你说的都是一堆废话?我完全可以无视你那垃圾语言。“灵犬”的检测结果显示:健康概率为67%。
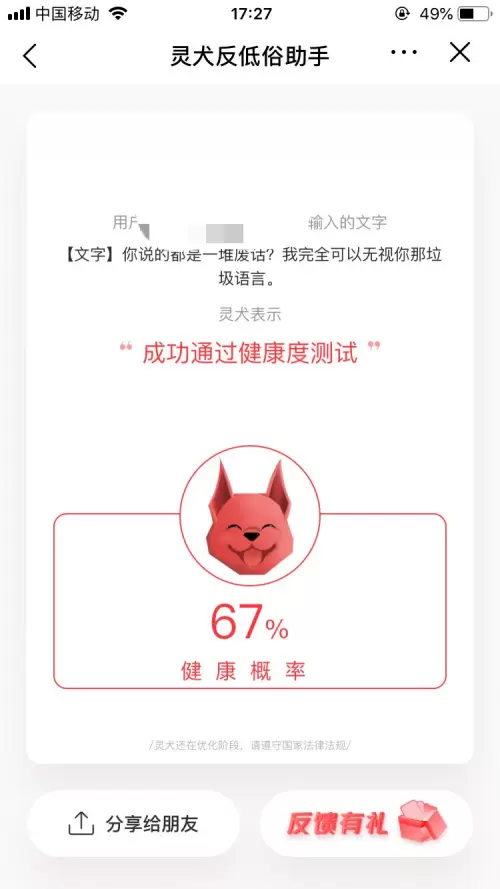
这句低俗语句带有“废话”和“垃圾”这两个字眼,但在“灵犬”看来,这类语言其实并没有到达底线,健康度仍处于可接受的范围内。
接着,我们选择了“从前车马很慢,书信很远,一生只够爱一个人”这句诗人木心的经典情句,“灵犬”的鉴定结果为:健康概率达到了63%,成功通过健康度测试。
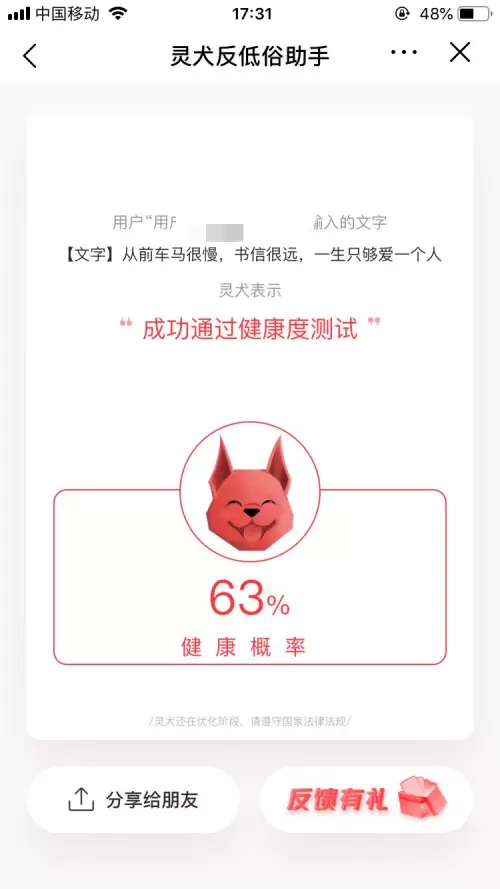
接着,我们决定找一些更敏感的文字来检测。“想跟老子比速度?老子在渝北出了名的飙车,老子看到红灯从来都是闯,我一个电话就可以全改”,这是摘自最近社会新闻的一段话,我们输入“灵犬”后,灵犬依旧表示“我觉得ok”。
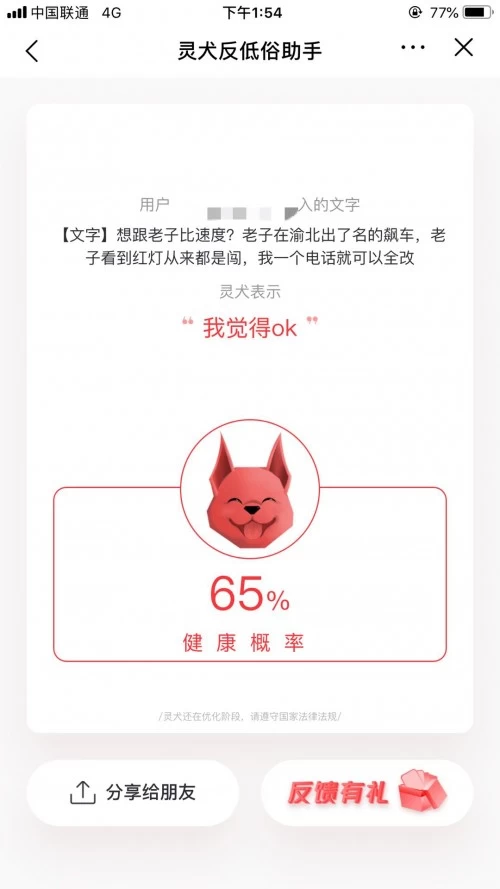
借鉴前段时间“B站被曝低俗内容泛滥”的事件,我们将一位家长对B站的看法也进行了检测。当“灵犬”接收到“该网站动漫作品中竟充斥着大量令人担忧的低俗内容,穿着暴露的少女,暧昧的语言和动作,甚至涉及兄妹恋等乱伦内容”这句更加直白的话后,他终于“变脸”了。一脸愤怒地表示,“嗅到了不好的味道,健康概率只有8%。”
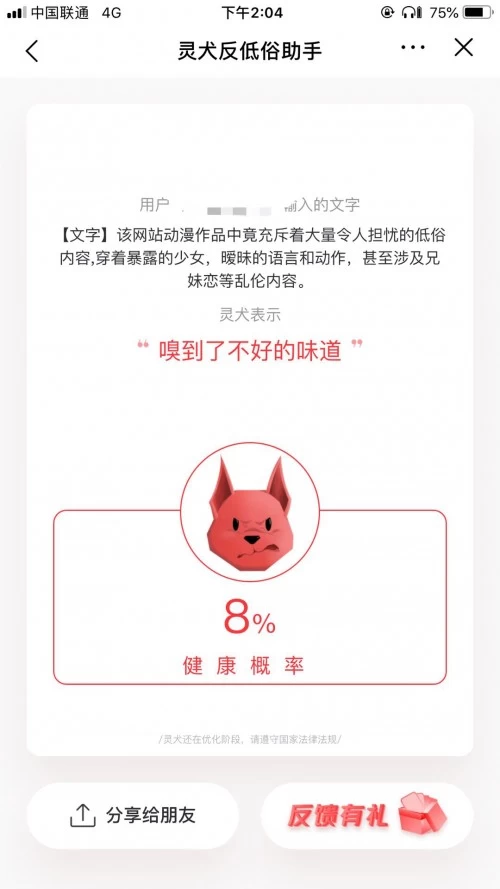
这样看来,“灵犬”反低俗、反暴力谩骂、反标题党的能力并非虚传,大体上还是能够分辨清楚的。
文本识别之后,我们又重点测试了下新版“灵犬”新增的图片识别功能,据说运用了更难的技术,能够识别图片中的低俗色情、甚至暴力血腥的元素。
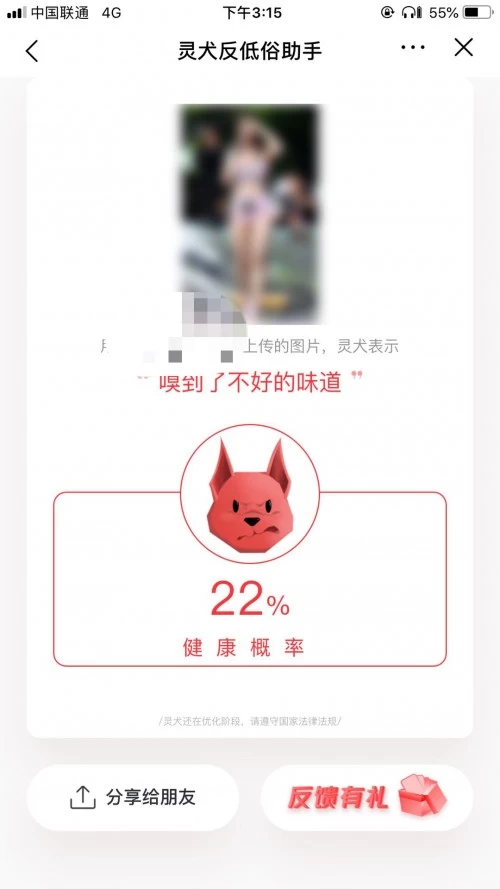
我们先测试的是一位微博红人身着露脐装和短裤的照片。图片的低俗色情相对容易理解,果然,这张照片灵犬给出的健康概率只有22% ,并对图片自动打上了马赛克。
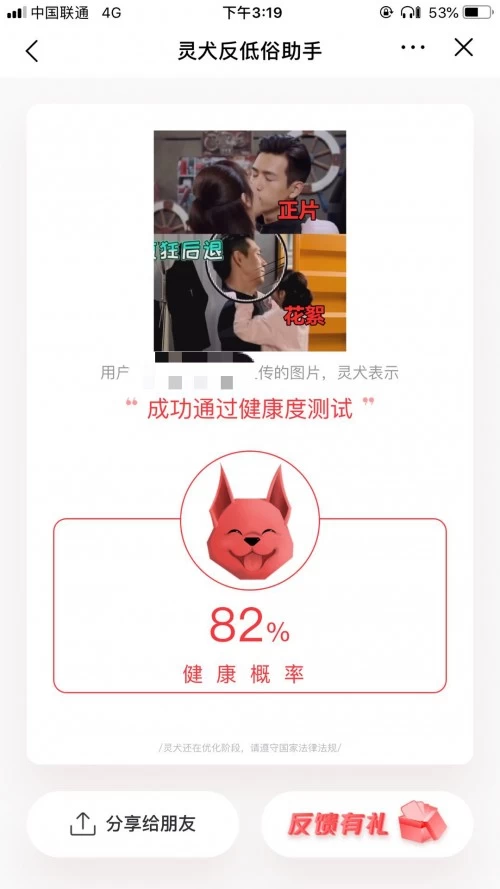
露肤之外,图片里的动态行为是否能检测到?我们将影视剧里吻戏场景放入了“灵犬”,这次“灵犬”给出的检测结果为“成功通过健康度测试,健康概率为82%。”
Bert+深度学习双重保险,让“灵犬”摇身变“警犬”
语义识别也好、图片识别也好,所涉及到的相关技术都是非常前沿的。那到底是什么技术附身在“灵犬”身上,让“灵犬”有了这番本领?
据了解,在文本识别领域,新版“灵犬”同时应用的是“Bert”和半监督技术,在不牺牲效果的情况下调整了模型结构,使得计算效率能达到实用水平;而在图片识别领域,“灵犬”运用了深度学习的解决方案,相当于它在短时间内学会了人类需要上百年甚至更长时间才能掌握的知识。这也就是我们现在所看到的,“灵犬”可以直接通过文字和图片来检测健康概率。
“Bert”其实是当前世界最先进的自然语言处理技术,也可以说是近年来自残差网络最优突破性的一项技术。它被称为AI领域的明珠,可以接收100多种语言,处理阅读理解、常识推理和机器翻译等任务。
有一句这样的流行语,“Bert在手,天下我有”。目前,IBM、谷歌、微软等世界顶尖公司都在运用这项技术,还有百度、阿里、腾讯、科大讯飞等国内知名公司都在运用这项技术。
不过,可别以为这个技术离我们的日常生活很遥远。
“Bert”已经应用在了知识图谱、情报检测以及法律文书等方面。知识图谱是人工智能研究中的核心问题,它能够赋予机器精准查询、理解与逻辑推理等能力。以《红楼梦》来说,我们可以利用Bert搭建起知识提取的机器学习模型提取红楼梦中的人物,并分析人物与人物之间的关系,这对我们快速了解小说人物结构非常有帮助。
在情报检测方面,传统的灾难信息检测方法已经不能满足当前迅速发展的互联网环境。而基于Bert的机器学习模型可以迅速对情报信息中的灾难信息进行处理,比如爆炸检测、情感分析、危害评估等,这是人工无法达到的效果。
在法律文书方面,最近,清华大学人工智能学院发布了民事文书和刑事文书Bert,这对法律行业来说是一大福音。对于法律行业来说,拥有高质量的文本数据至关重要。因为法律文书、合同等文本的质量高低与相关人员的利益密切关联。民事文书和刑事文书Bert可以反复检查文书内容,确保文书质量。
不同于文本识别,“灵犬”图片识别的技术难点主要在于三方面:网络上的低俗图片占整体图片内容的比例较低;低俗种类非常丰富和繁杂;低俗图片的内容特征千差万别。换句话来说,现在一百万张图片里面可能只有两三张图片是低俗的,低俗种类有几十种甚至更多,比如性暗示、性器官、内衣等,甚至还涉及不同的场景。
为了解决这个问题,我们也了解到,今日头条人工智能实验室分别在数据、模型、计算力等方面做了很多优化。数据层面,“灵犬”累积了上千万级别的训练数据。模型层面,“灵犬”针对许多困难样本做了模型结构调优,尝试解决多尺寸、多尺度、小目标等复杂问题。计算力层面,“灵犬”利用分布式训练算法以及GPU训练集群,加速了模型的训练和调试。
技术与人工结合 助力反低俗
虽然,目前“灵犬”已经能够同时支持文本识别和图片识别,但是无论“灵犬”也好,Facebook和 YouTube 也好,技术都还无法百分之百地解决问题。比如一些存在歧义的句子和词汇,就不能完全准确地判断出健康程度。而这些技术难以搞定的问题,现阶段还有赖于人工判断。
机器通常是“就事论事”,考虑不到艺术作品的的人文价值。比如世界名画中常常出现裸体女子,如果完全交由机器判断,机器通过识别画中人物的皮肤裸露面积,就会认为这幅画是色情低俗的;某些拍摄芭蕾舞的图片,以机器的视角来看,其实类似于裙底偷拍。
内衣和内衣模特出现在购物平台上,我们人类会默认为正常,但如果频繁出现在新闻资讯平台上,就可能被认为有低俗嫌疑;正常的热舞内容,提供给成年人看,是符合常规标准的,但如果开启了青少年模式,这些内容就不应该出现。
同一句话在不同的语境下面会有不同的意思。比如“菊花”、“我下面给你吃”在正常环境和网络环境下就会出现不同的意思。还有“寒暄”、“安抚”、“讽刺”这种言语修辞行为,“灵犬”也难以准确判断健康概率。
针对这些低俗问题评判的复杂性和不同判断方式的局限性,看来灵犬还有很大的进步空间。而就目前来说,想要应对反低俗这项大挑战,一方面需要不断进化灵犬的技术模型,另一方面则是需要有效结合技术和人工判断两种方式,通过人机协作来共同完成。
不过,值得注意的是,“灵犬”目前已经建设了比较完善的模型迭代系统。通过“数据收集—数据标注—数据清洗—模型训练—模型评估—badcase分析”这一套完整的流程,持续做优化。
在信息大爆炸时代,低俗的定义相对笼统,很难完全精确地定义出来,反低俗这项工作对人类来说也不容易。“灵犬”的出现,恰恰能弥补这一不足。在技术与人工的结合下,我们相信反低俗这条路会越走越远。
相关文章
- 今日头条x中国建设银行深度访谈上线:2026年,王坚院士解码 AI “世纪问题”
- 鸿蒙版今日头条安装量突破2000万!新增创作中心、碰一碰和隔空传送
- 今日头条平台治理开放日:AI与同质化治理问题备受关注
- 持续加强社交互动探索,今日头条首次推出社交年度报告
- 中兴通讯携手今日头条举办2024新洞察媒体沙龙 共探AI、智慧应急与新质产业未来
- 2022今日头条生机大会聚焦创作者生态建设,解读优质、兴趣、多元三大关键词
- 2022今日头条生机大会发布年度扶持政策,全方位助力创作者成长
- “头条十年,看见彼此” 2022今日头条生机大会将于12月27日启幕
- 2022今日头条生机大会百大人气作品榜单公布,多元内容优势不断显现
- 两大赛区、百大晋级名额,2022今日头条生机大会百大人气作品评选活动火热开启
- 今日头条发起「点亮真知计划」,洪晃、刘擎、史航、沈奕斐倾力加盟大咖直播
- 共筑防疫长城,今日头条上线“新冠疫苗”预约服务
- 今日头条年度娱乐大赏名单公布 《八佰》《三十而已》获最佳影视作品荣誉
- 今日头条发布2020年度数据报告:行家创作者崛起
- 今日头条CEO朱文佳:在头条,看见更大的世界
- 今日头条职业认证创作者超过13万人








