通过前端工程化将Apollo引入现有React技术栈
2020/02/26 17:30AI云资讯10807
GraphQL 作为一种新的通信协议自 2015 年 Facebook 开源之初,就开始受到技术社区的关注。Apollo 作为目前较为成熟的 GraphQL Client 解决方案,成为腾讯 NOW 直播 Web 业务的首选 。在 GMTC 全球大前端技术大会(深圳站)2019 上,朱林结合腾讯 NOW 直播的实践分享了:GraphQL Client 解决的问题是什么?Apollo 的优势是什么 ?
本文即根据朱林的演讲整理而成。以下为正文:
大家下午好,我是来自腾讯 NOW 直播的高级前端工程师朱林。我是 2015 年进入腾讯的,目前在腾讯最大的前端团队之一的 IVWEB 团队,我在团队主要负责 PWA 以及 GraphQL 等技术栈的业务落地 。
今天我分享的主题是《通过前端工程化将 Apollo 引入现有 React 技术栈》,主要分为三个部分:
首先,介绍什么是 GraphQL。
其次,GraphQL 在前端的选型,即 GraphQL Client 端的选型,目前业界最火的有两个方案,一个是 Apollo,另一个是 Relay,我会对比这两个方案,大家可以结合自己的业务作出选择。
最后,确定好选型之后,我们希望把整个团队的技术栈统一,那么手工拷贝代码或者口口相传的方式肯定是不可取的,我们希望通过类似前端工程化的脚手架这样的方式在新项目中快速推广,统一整体的技术栈。
什么是 GraphQL ?
首先,我简单介绍一下什么是 GraphQL。
在了解 GraphQL 之前,我们先来看下这个页面(可以扫二维码直接看到)。这个页面其实是一个比较典型的列表页面或者说 feeds 页面,很多卡片其实很类似,可能也会有一些分页的需求,每个卡片的元素或者说信息的数据结构比较统一。
单独拿一个卡片来说,这里有主播的头像、昵称,还有你是否关注主播,以及这个主播是否处于开播状态。
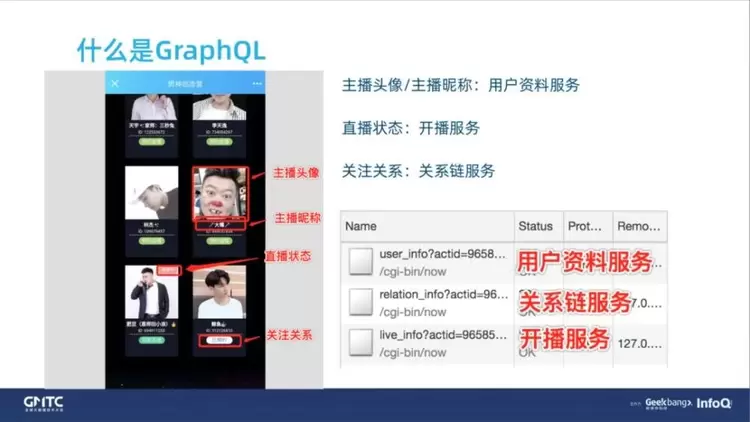
对于我们的后端来说,后端服务都是追求尽量的原子化,或者说微服务;所以用户资料可能是一个独立的服务,关系链关系(即你跟主播的关注关系)是一个独立的服务;主播的开播状态,或者说我们叫房间服务 / 开播服务,也是一个独立的服务。
依据之前很火的 Restful 这样的一个接口风格,可能很多同学没有实践过,它会要求把所有的接口都看做资源,每个资源都是独立、解耦的。可能一个首页的页面会拉三条后台接口,但是,作为前端性能优化的一个最基础的指标来说,你希望你的 HTTP 请求能够尽量的少,这样一方面性能更好,另一方面,前端编写代码的时候不用再去做数据聚合,这样可以降低前端代码的复杂度。
然后,你希望后端的同学聚合下接口。于是得到这样一个接口,如下图所示。
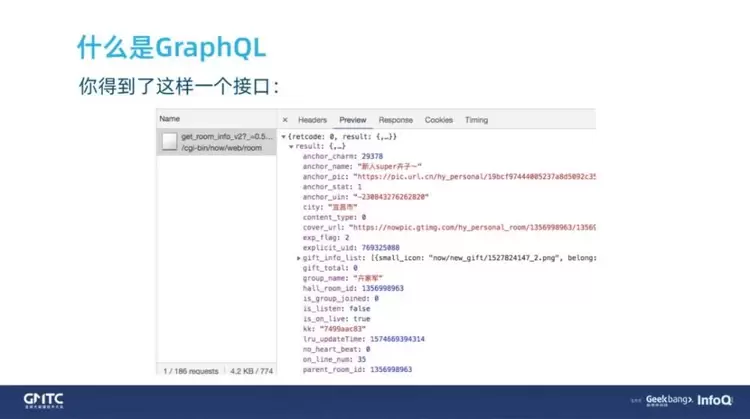
这个接口字段非常多。为什么?因为不止你向这位后端同学提了需求,还有其他同学也提了需求。很多其他的页面可能不是长这样子,其他的同学也希望能够聚合一下。他们页面的有些数据是跟你一样的,比如:主播的头像、昵称。可是也有一些差异,比如:主播拍的短视频、主播开播的房间的封面,后端同学就把这些都聚合到了这个接口,这个接口当然能够满足大家的需求,可多出了很多冗余数据。下面我们简单看一下接口文档。
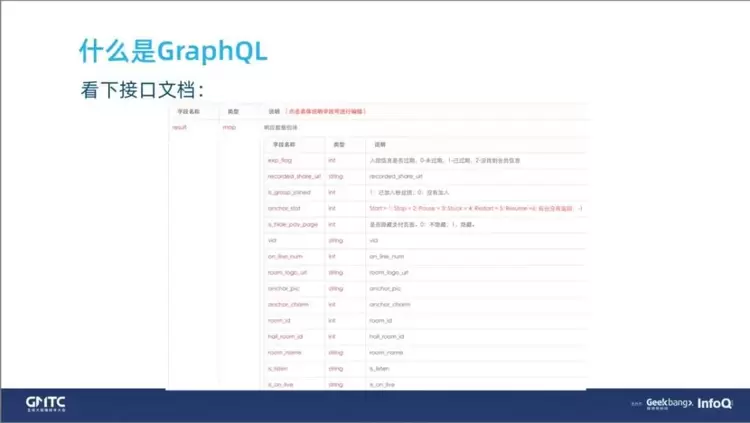
接口文档
当接口非常复杂时,就会暴露出两个问题。如果数据要解耦,我们就会请求很多次接口;即使后端的同学做了聚合,又会有很多冗余的字段,下面是数据聚合后的接口文档,还是非常复杂的,我们看看这样会带来什么问题。
业务报错
下图是我们团队自研的一个前端脚本错误监控的方案,已在 GitHub 开源了,叫 Aegis。突然有一天你的业务报错了,比较典型的就是 null is not an object,那为什么会出现这样的报错呢?
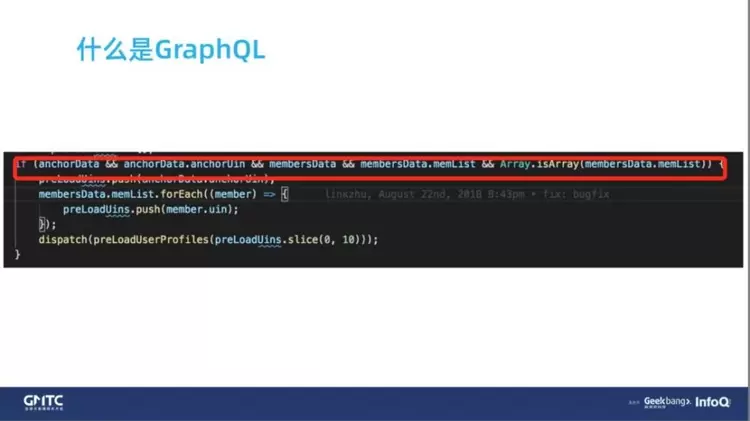
因为,复杂的接口一般都对应着防御性的编程。但是你写代码时,默认就相信后端的接口一定是按照接口文档的形式返回的,没有做防御性编程。

为了解决这个问题,防止某些字段不是你期望所返回的样子,你做了一些防御性编程(如下图)。代码非常丑陋,不仅要判断嵌套对象中的字段是否存在,而且还判断这个字段的值是不是数字类型。
API 联调痛点
在上面的小故事中,可以看到一些问题。

请求多个 API
请求多个 API,影响前端页面性能。
冗余字段
当你让后端的同学帮你做聚合时,又多了冗余字段。因为多了冗余字段,可能在实际业务的性能度量中,页面的首屏渲染速度并没有得到提升。
API 文档更新不及时,甚至没有文档
刚刚看到的那个文档非常复杂,不仅要判断嵌套对象中的字段是否存在,而且还判断这个字段的值是不是数字类型;当需求变更时,文档还会新增字段或者改变字段的类型。当再把文档交接给其他同事时,因为文档更新不及时,新的问题会随之产生,毕竟错误 / 过时的文档,还不如没有文档。
参数类型校验
最后,就是刚刚说的所谓的防御性编程。在前端代码里面,因为可能不会信任后端返回的数据,你会写很多所谓的参数类型校验,或者字段是否存在等防御性编程代码,而这些代码跟你的业务逻辑是没有关系的,徒增代码的复杂度。
API 联调痛点解决方案
没有 GraphQL 时的解决方案
假设大家都不知道 GraphQL,那么针对这上面这 4 个问题,我们从零开始去想的话,如何解决这个问题?(如图所示)

GraphQL 解决方案
在有 GraphQL 的情况下,我们又是怎么去解决的。

Query
针对请求多个 API 和冗余字段等问题,在结构化查询语言中,通过 GraphQL 的聚合,不需要写很多冗余的逻辑,也不用手动去聚合,只需要通过写 JSON 的方式配置 GraphQL schema 文件,它可以自动帮你处理这些过滤逻辑以及类型校验逻辑,请求多个 API 时只返回你想要的接口,不多也不少。
introspection(自检性)
针对 API 文档更新不及时,GraphQL 的解决方案是,在写好后端代码后,不需要写接口文档,因为已经和前端的同学定义好字段的类型。写过 TypeScript 的同学应该知道,每个字段对应的是一个强类型的字段校验规则。其次,利用 GraphQL 的自检性,你就可以完全的看到这个接口可以提供哪些字段,每个字段代表的含义是什么,每个字段返回的参数的类型是什么,以及它可以接收怎样的参数。
类型系统
针对参数类型校验,是说每个字段返回的参数的类型是什么,以及它可以接收怎样的一个参数。GraphQL 是一个强类型的协议,有自己的类型系统。

什么是 GraphQL?
GraphQL 定义
GraphQL 是 Facebook 在 2015 年开源的,那么先来看一下它是什么?
GraphQL 的定义是一种 API 查询语言,它其实是一种语言的规范,跟具体的实现是没有关系的。而且它是一层非常薄的数据抽象层,它既不会负责存储数据,也不会负责渲染数据;简单说就是一层 Proxy(代理),它把后端的数据做一些聚合、校验、判断,再返回给前端。对于前端来说,它是一种结构化的查询语言,长得很像 JSON,其实不是。
数据抽象层
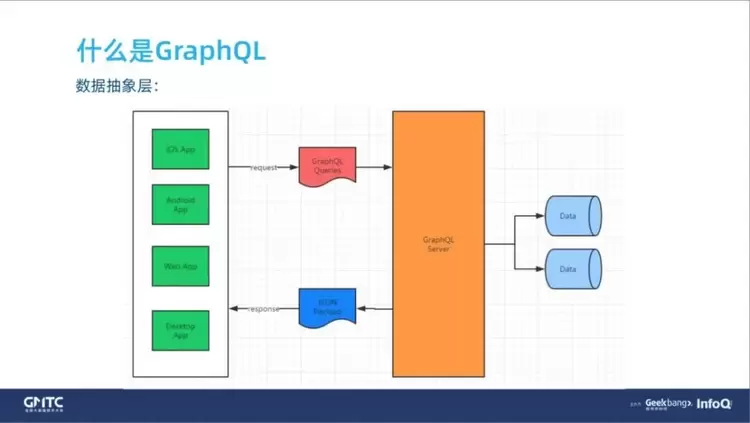
数据抽象层就是中间这一层 GraphQL Server。对于前端来说,你可能是一个 iOS 的 App,安卓的 App,也可能是移动端的 H5 页面,通过一个 Http 协议层把 GraphQL 的 Query(查询参数)请求到了 GraphQL Server,对于 GraphQL Server 来说,它取数据的 Data 层是什么它一点都不关心,但是它吐回给前端的就是一个 JSON。
语言无关
GraphQL 是一个所谓的数据抽象层,它的逻辑轻及薄,且与语言无关。Facebook 官方推荐的实现是 JavaScript,即 Node.js 的实现;在社区这个方案非常活跃,包括 Ruby、Go、Python、PHP、C# 等,在社区都有各式各样的对于 GraphQL 规范的实现。

结构化查询语言
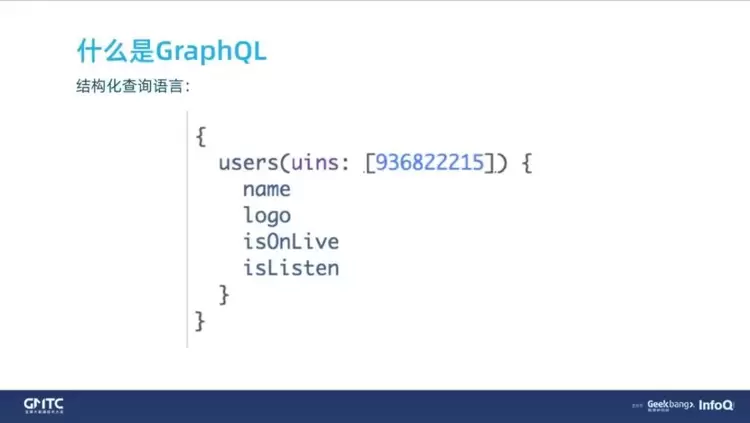
上图就是在前端发起一个 GraphQL 查询的样子,它其实不是 JSON,但是非常像 JSON 包裹起来的。看上图,users 就是 list,它想请求一个用户的列表,那么传入的参数是一个数组,但我这里只传了一个数组元素,这里 unis 即用户唯一标识符。返回的数据就包裹在下面这个花括号里,包括姓名、头像 logo、是否在线、是否在开播,以及用户是不是关注了他(isListen)。
Apollo VS Relay
在前端社区里面,两个最典型的 GraphQL Client 方案就是 Apollo 和 Relay。
Apollo 是由社区驱动的,文档非常丰富。据我所知,目前已经有一个类似于创业公司的组织在驱动它不断迭代,它提供了一整套解决方案,包括 Apollo Client 和 Apollo Server;它也是前后端一体的打包方案,甚至提供了整个链路的一个监控平台,可以监控 Apollo Server 或者说 GraphQL Server 的性能指数。
Relay 是 Facebook 官方出的,只是针对前端,而且只针对 React 的技术栈,它不仅能让你更好、更方便地写 GraphQL Query,甚至还接管了前端的数据管理。
Relay
Relay 示例
那么我们先来看一下,没有 GraphQL Client,前端该怎么发起一个 Graphql Query?

上图是一个 Relay 的 action。
我请求了一个 url(即 GraphQL 的一个接口),上图是直接拼接字符串。
大家可能会问,为什么不直接用模板字符串?直接用模板字符串当然可以,但是会带来一个问题,前端页面会在 Html 这一层去 inline 一段后台接口预加载的逻辑,并把它缓存到内存里(比如挂载到 window 对象上),这样当你的 JS 文件加载完成,发起后台接口请求时,可以优先读取内存中缓存好的接口数据,但是取缓存的 key 值是接口 url + 接口参数。
当使用模板字符串时,因为构建器不一样,或构建配置不一样,没有办法保证这一段 Query 模板字符串最后编译出来的格式,比如有几个换行、空格,这样读取接口缓存时可能会出现 key 值不匹配的情况。

如果没有 GraphQL Client ,但是又想做 Http 接口预加载,用拼接字符串方式可能会更靠谱。
Relay 的缺点

Relay 带来的问题主要为以下三个:
可读性差;
缺少校验;
手动处理缓存。
首先,不光可读性非常差,而且写代码也非常痛苦;其次,也是最重要的一点,Relay 在前端完全没有利用到 GraphQL Client 的类型校验能力。如果传的参数错了,就没有这个字段,一定要到请求完后端之后,才能感知到这代码写错了;如果有 GraphQL Client 方案的话,在构建编译时就会直接报错,不用等到请求后台接口这一步。最后,在前端可能需要自己手动处理后台接口的缓存。
Apollo Client
Apollo
好,我们来我们先简单介绍一下 GraphQL Client 。GraphQL Client 的用法很简单,直接安装 apollo-boost、react-hooks、graphql 三个包就可以了。

这三个包怎么用呢?apollo-boost 这个包,提供了所有前端需要的 API,包括转换,构造 GraphQL Query 的请求参数,以及设置 GraphQL 后台接口等。apollo/react-hooks 是基于 react-hooks 的视图层,如果现有业务代码里面没有用到 react-hooks ,可以先不用管它。graphql 是 Facebook 官方提供的一个包,用来解析官方查询语言,因为它毕竟不是一个 JSON,当发起请求时 ,它会做一些处理。
如果用 GraphQL Client,刚刚那种代码可能就会变成这样(如下图)。

先看左边代码,与刚刚定义了 GraphQL Query 的模样不太一样,你会发现:
users 的 uins 不是一个写死的固定的值,而是一个变量的 anchorUinList,能够通过参数动态化传入 Query 是非常重要的一个点;
anchorUinList 被定义为了 float(浮点)。
就像我刚刚说的,定义好了前端的 GraphQL Schema,如果实际传参有问题,比如说, User 唯一 ID 有问题,其实根本不用等到跟后台联调阶段才发现问题,写代码编译时就会报错了。那么具体怎么发起呢?在这里设置 GraphQL 后台接口的地址,然后用 Client.Query 的方式发起。当然,这是一个最简单的 demo。可以用 GraphQL.Query 这样一个公共的方法去抽离出来,抽成一个 redux 的 middlerware,也可以通过 dispatch 一个 action 去发起请求。
Relay
Relay 有一个最重要的特点,即强制约定大于配置。什么意思呢?即在 Relay 的规范里面,它规定了很多东西,如命名、查询规范等。
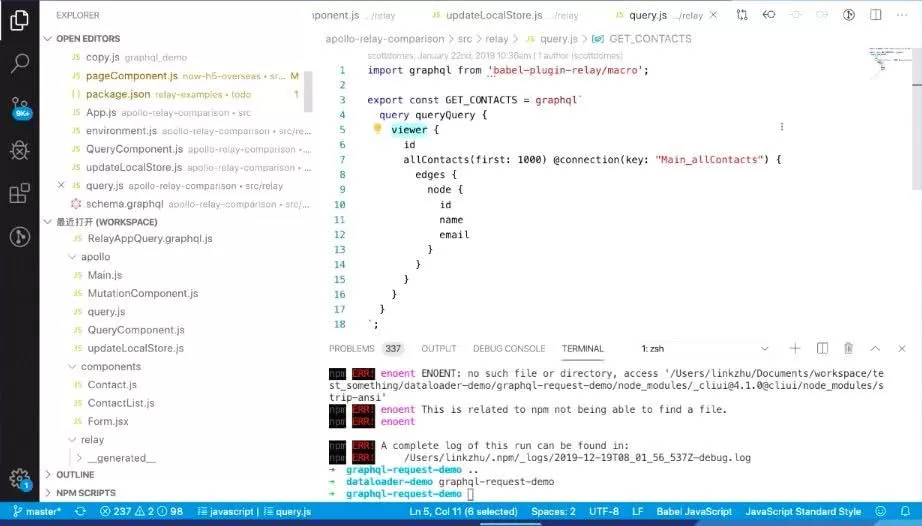
上图是一个 Relay Query 的例子,跟刚刚的 GraphQL Schema 长得差不多,但是不同之处在于:
命名格式
一定要按照它的格式命名。上图,你会发现这个文件叫 Query.js,但是你的 Query 就一定要叫 Query,且下划线后面的驼峰一定不能变,它表示前面那块是 modules,后面的驼峰的大写的首字母表示这是一个读操作。因为 GraphQL 不止支持读操作,还支持写操作,在 GraphQL 里面叫 mutation(突变)。
查询规范
在 Relay 里面还定义了一个点,就是说它的分页方式跟我们在 Restful 的那种风格不一样。它认为你请求的每一个资源都是一条边,前端到后台的一条边。所以,你会看到 connection 包裹的对象叫 edges,然后每一项就是我刚刚页面里面的每一张的卡片,它就是一个 node ,也就是节点。包括你的 GraphQL Client 去定义分页参数的时候,也要遵循这样的查询规范。
GraphQL 还支持第 3 种基本的操作类型,叫 subscription(订阅),如果是 Web 应用的话,可能会基于 WebSocket 的做订阅,取代长轮询这种比较浪费资源的方式,来主动监听页面数据的变更。
Apollo VS Relay
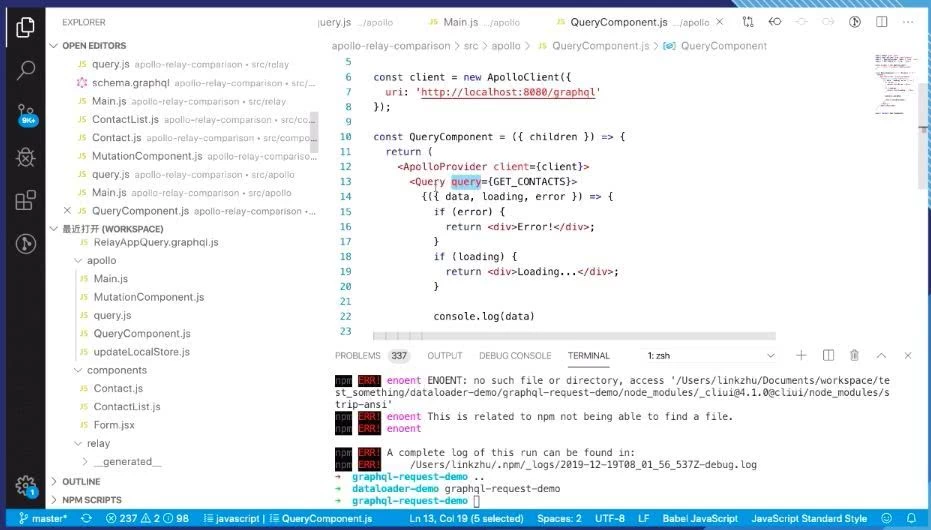
这是 Relay 的 GraphQL 形式,它实际是 Query 是通过一个 React Apollo 这样的组件发起的,然后直接把后端请求的数据以 props 的形式传递到真正的业务组件里面去。
以上是通过一个 demo 简单的对 Apollo 和 Relay 做一个对比。
Apollo 优点:
文档丰富社区驱动,生态丰富代码侵入性低(相比 Relay)
Apollo 缺点:
非官方出品
Relay 优点:
Facebook 官方出品约定大于配置
Relay 缺点:
文档复杂
侵入性较强
手动处理缓存

这是前端的一个比较,对于在后端的业务迁移来说,我个人的建议是,前端同学可以先把现有的 HTTP 的后台接口作为 GraphQL Server 的数据源,多一层很薄的一层,然后慢慢的把整个前后端的技术栈往 GraphQL 技术栈平滑迁移,这样的话,你可以一个接口一个接口的迁移,步子不会迈得太大,也不会出太大的问题,改造成本也不会太高。
N+1 Query 的问题
GraphQL 的特性所带来一个问题,即“N+1 Query”的问题,就是我请求 4 个字段,前端请求了 1 次,后台请求了 4 次”,遇到这个问题怎么解决?
Facebook 提供了一个解决方案,一个非常薄的工具,才 300 多行代码,里面还有很多是注释叫 dataloader。解决原理:
第一是缓存,既然你每次都会发起 5 次请求,但其实很多字段它的 Key 是一样的。比如说,刚刚那个例子,某一个特定主播的头像、名称,其实只要请求一次,就可以缓存住了。缓存策略还可以自己控制。
第二点是,它会在 Node.js 那一层,也就是 GraphQL Server 那一层会批量的请求数据。
三、总结

做一个简单的总结:
我们可以基于之前的 Restful 接口,或者这些基于之前的后台的 Http 接口,渐进式改造,把现有前后端的通信链路改造为 GraphQL 技术栈。
使用到 GraphQL 之后,未来研发模式一定是 schema 优先。前后端共同维护 GraphQL schema,也就不存在接口文档了;代码写好了,文档就自然而然的生成好了,包括需要什么样的字段,字段是什么类型,是否允许否为空。
选择合适自身业务特点的技术栈。
我们是可以通过业务抽象的脚手架去统一前端模板。可能通过 yeoman 去生成一个统一的规范的脚手架,来在新项目中去统一大家发起的 GraphQL 请求的方式,或者统一大家 GraphQL Client 一个技术选型,包括构建工具,而不是说每个同学去写一个新页面的时候,都要重新去搭建前端技术的开发环境,或者说重新安装一遍开发环境。
我个人认为 GraphQL Server 其实不是说让前端去侵入后端,更多的是去提升前后端双方的研发体验,以及未来项目上线之后的运营质量。
相关文章
- 上海联通携手华为、百度Apollo率先完成全球首个5G物联RedCap连片部署验证
- 豪华纯电市场迎来新“老兵”,传奇超跑Apollo重新定义“智慧出行”
- 全球画质最高赛车“游戏”!百度Apollo 5G云代驾曝光:真地球Online开车
- 智慧治城 广州黄埔与百度Apollo达成双智战略合作
- 百度Apollo车路协同系统多点落地 智能交通运营商模式成效凸现
- 百度Apollo智舱接入福特EVOS,开启燃油汽车智能化新进程
- 百度Apollo活力TIME携同济大学汽车学院在沪举办
- 广州车展群英荟萃,百度Apollo或成最大赢家
- IDC:百度Apollo拥有未来发展的强大势能
- 百度Apollo参编汽车信息安全国家标准,持续深耕车辆全生命周期安全防护
- Apollo Moon三款量产无人车集结 Robotaxi规模化部署持续进发
- 百度Apollo成立汽车机器人部,打造新时代的智能“大黄蜂”
- 百度Apollo汽车机器人部成立,绘制无人驾驶新蓝图
- 百度Apollo 5G云代驾企业版首发,四大创新优势、三大应用场景
- 百度Apollo一天发两款新车,领航辅助驾驶到完全无人驾驶车型全覆盖
- 现代汽车中国前瞻数字研发中心在沪揭幕,携手百度Apollo打造智能出行新方式
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


