自定义AI加速走势高涨 将引起更加广泛的关注
2020-03-18 12:22:22AI云资讯953
自定义AI加速走势高涨。在云计算领域,阿里巴巴继亚马逊、谷歌之后,推出了自己的定制加速器。Facebook也参与其中,微软在Graphcore中持有大量股份。英特尔(Intel)和Mobileye在汽车领域拥有强大的边缘人工智能(AI),而无线基础设施开发商正在为5G的小电池和基站增加AI功能。所有这些应用程序都依赖于大量灵活性和对未来的检验,以便在快速发展的环境中获得长期的相关性。
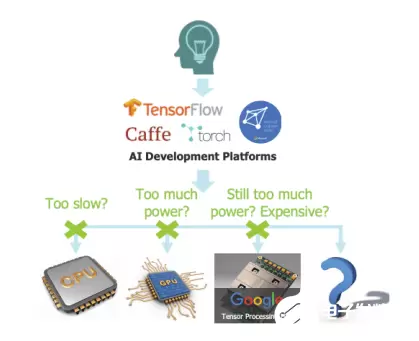
但是有许多应用程序,对于它们来说,功率、成本或透明的使用模型是更重要的度量标准。一个农业监视器在一个偏僻的地方,一个微波语音控制器,交通传感器分布在一个大城市。对于这些问题,一个通用的解决方案,甚至一个通用的AI解决方案,都可能是多余的。所以,一个特定的应用程序的AI功能将会更加引人注目。
在人工智能时代之前,你会立刻想到一个硬件加速器——它可以做任何它必须做的事情,但比在CPU上运行一个软件要快得多。这就是人工智能加速器的作用。它可能仍然是以软件驱动的,但与通用CPU方式不同。软件是在大型平台(如TensorFlow或Torch)上用Python开发的,然后通过多个步骤编译到目标加速器上。
这就是神奇之处。只要加速器保持在神经网络架构的一般范围内,它就可以像你希望的那样狂野。它可以支持多个卷积引擎,每个引擎又由SRAM作为一个整体来支持,同时还支持本地内存,以优化对操作的优先顺序的访问。
它可能支持专业功能池等常用操作。为了提高速度和性能,它通常会在不同的推理阶段支持不同的字宽,并在处理稀疏数组时支持专门的优化。这两个领域都是神经网络架构的创新热点,一些架构师甚至尝试使用单比特权值——如果一个权值只能是1或0,那么你就不需要在卷积和稀疏性增加中进行乘法运算了!
所有这些的挑战在于,当你想要致力于最终架构时,你会发现有太多的旋钮,以至于很难知道从哪里开始,或者你是否真正探索了全部的可能性空间。更加复杂的是,你需要在大范围的大型测试用例(大图像、语音样本等等)上测试和描述。
用C语言而不是RTL来运行大部分测试是常识,因为它比RTL运行速度快几个数量级,而且比RTL更容易调优。此外,神经网络算法可以通过高级合成(HLS)很好地映射,因此你的C模型可以不仅仅是一个模型,它还可以是生成RTL。你可以探索你正在考虑的选择的能力、性能和区域含义——多个卷积处理器、本地内存、字宽、广播更新。所有这些都具有快速的周转时间,允许你更充分地探索可能的优化范围。
相关文章
- 数字厨电36%增速背后,老板电器2025年报交出了“AI+烹饪”答卷
- 获新华网重磅报道!科大能通AI储能充电机器人闪耀第四届中国科交会
- Think 2026全新发布:IBM推出“AI运营模式”蓝图,弥合日益扩大的AI鸿沟
- AI真正的战场不在聊天框:“北大系”爱化身祭出企业级AGI,扎进车间、门店和供应链
- 海能达CCA 2026重磅发声:以AI赋能关键通信,探索智联新方向
- 浩鲸科技亮相数字中国建设峰会,携手中国电信以AI-Native驱动云网智能化
- 焕新升级,快鹭智能办公AI CRM引领销售管理2.0时代!
- 智生影像・共创未来 智能影像时代AI影视创作主题研讨共绘视听产业新图景
- 图灵进化亮相GITEX AI Kazakhstan,三款AI一体机发布,总统亲临关注
- 找个尼日利亚单身妈妈做代言?橙果视界AI智能体矩阵破解本地化难题
- 法大大发布智能合同助手,打造人人可用的AI合同助手
- 全球首款8K AI拇指运动相机!光子跃迁LEAPTIC Cube正式预售
- SpaceXAI宣布将向Anthropic开放搭载22万张英伟达GPU的巨像一号超级计算机
- OpenAI宣布与AMD、英伟达、英特尔、微软及博通达成超级合作,合力加速AI发展
- 宇信科技亮相印尼华为大会:全栈AI+生态协同破局金融数智化本地挑战
- 格创东智亮相福州峰会,携双引擎演绎AI驱动工业“提质增效”与“绿色低碳”
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力
- 昇腾原生支持,科学多模态大模型Intern-S1-Pro正式发布并开源
- 百度千帆深度研究Agent登顶权威评测榜单DeepResearch Bench
- 在MoltBot/ClawdBot,火山方舟模型服务助力开发者畅享模型自由


