媲美DeepSeek NSA!腾讯优图提出混合注意力机制SSA,长上下文外推更强
2025-12-05 15:53:16AI云资讯11782
大语言模型(LLMs)在处理长上下文时面临全注意力机制带来的二次方计算复杂度瓶颈,限制了其推理效率。稀疏注意力通过限制每个查询仅关注部分历史 token 来缓解这一问题,但无需训练的稀疏策略往往导致性能显著下降。尽管原生稀疏注意力方法(如 NSA、MoBA)通过端到端训练改善了这一状况,却陷入一个关键悖论:其学习到的注意力模式反而比全注意力模型更稠密,削弱了稀疏化的有效性。这源于梯度更新缺陷——未被稀疏机制选中的键值对在前向传播中被跳过,未获得梯度更新,导致无法学会自我抑制。
为此,腾讯优图联合伦敦国王学院提出 SSA(Sparse Sparse Attention)训练框架,在每一层同时引入稀疏与全注意力,并强制二者输出双向对齐。该设计保留了所有 token 的梯度流,使模型能主动学习有效稀疏,而非被动剪枝。实验表明,SSA 在多个常识推理基准上达到了稀疏与全注意力推理下的SOTA水平;其模型还能平滑适应不同稀疏预算——随着允许关注的 token 数增加,性能持续提升,支持灵活的计算-性能权衡。尤为突出的是,SSA 在长上下文外推任务中表现最强,通过缓解“汇聚区”(sink areas)中注意力值的过度分配,显著提升了模型对超长序列的泛化能力。

论文标题:SSA: Sparse Sparse Attention by Aligning Full and Sparse Attention Outputs in Feature Space
论文链接:
https://huggingface.co/papers/2511.20102
1
方法
SSA 设计了两个优化的目标:
标准的下一词预测交叉熵损失,在稀疏与全注意力模式下以相等概率采样计算。
层级别的双向对齐损失,用以约束稀疏注意力与全注意力输出的一致性(详见算法1)。
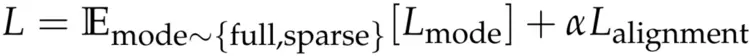
其中,Lmode表示在随机采样的注意力模式(全注意力或稀疏注意力)下计算的交叉熵损失,α 为权重系数,Lalignment为双向对齐损失,旨在促进全注意力与稀疏注意力输出的一致性。

(1)稀疏与全注意力模式
在训练过程中,以相等概率交替采用全注意力与稀疏注意力模式(如图2所示)。引入双模训练有两个原因:一方面,全注意力能自然形成更具区分度、天然自稀疏的注意力分布;另一方面,稀疏注意力更贴近实际推理时的运行方式。为控制计算开销,并确保模型在训练中处理的 token 总量与基线方法一致,研究者并未同时优化两种模式的损失,而是交替进行更新。
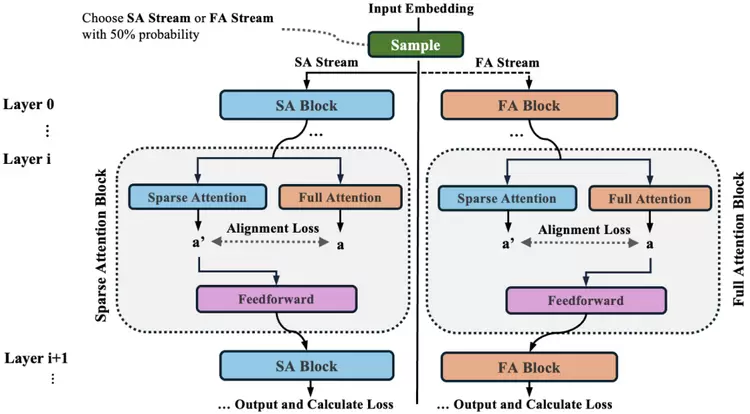
图2 SSA 训练框架示意图
(2)对偶注意力对齐机制
为进一步提升注意力稀疏性并增强两种注意力模式之间的一致性,研究者引入了一种对偶注意力对齐机制。在每一层中,除当前主干路径所采用的注意力模式外,额外计算其对应相反模式的辅助注意力输出(例如,若当前流使用全注意力,则同时计算稀疏注意力输出)。该辅助计算仅用于对齐目标,不参与后续层的前向传播。
对齐目标由两个互补的组件组成。第一个是稀疏性损失,它旨在促进全注意力输出模仿稀疏注意力输出,从而促进形成更稀疏和更具选择性的注意力分布:
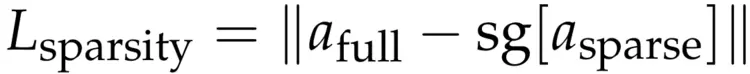
其中sg[·]表示梯度截断,afull和asparse分别指全注意力和稀疏注意力输出。
第二个组件为对齐损失,用于对稀疏注意力输出施加正则化,使其与全注意力输出保持一致。
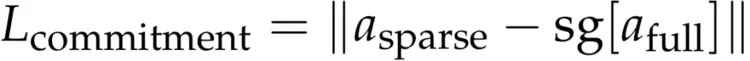
总对齐损失结合了两个分量:
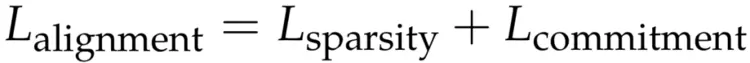
这种双向对齐机制协同作用,一方面促使全注意力在训练过程中自然趋向更稀疏的分布,另一方面确保稀疏注意力分支在训练中保持稳定,并与其对应的全注意力分支保持一致。从概念上看,该损失以基于值向量(value-aware)的方式对齐两种注意力分布。相较于直接对齐全注意力分布,该方法显著提升了效率:后者需要显式构建稠密的注意力矩阵,不仅与 FlashAttention 等基于在线 softmax 的高效实现不兼容,还会造成较大的内存开销和计算负担。
2
评估
(1)语言建模能力
表1 在全注意力和稀疏注意力推理下,不同训练方法的比较
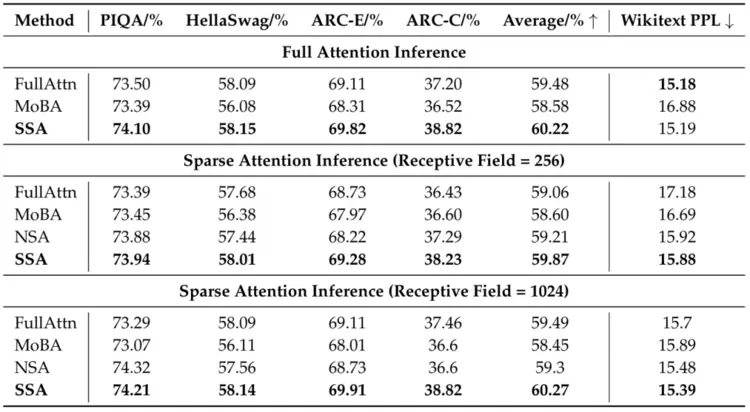
表6 SSA、MoBA 和 FullAttn 在 KL 散度、注意力稀疏性、困惑度及基准任务准确率方面的对比

SSA 通过引入稀疏训练路径和对齐损失,在保持全注意力性能的同时,显著提升了稀疏推理质量。其核心机制是对齐损失促使全注意力分布变得更稀疏,从而减少与稀疏注意力在推理测试时的表达差异。如表1和表6所示,SSA 的稀疏注意力和全注意力性能差距最小(体现在PPL 和 KL 散度两个指标),验证了“增强内在稀疏性可提升稀疏推理效果”这一假设。
(2)常识推理
如表1所示,在PIQA 、Hellaswag 、ARC‑Easy以及ARC‑Challenge这些常识推理任务中,SSA 不仅优于所有稀疏基线,甚至以仅 256 Token的感受视野(receptive field)超越了全注意力模型。两者在全注意力下的语言建模能力(PPL)相当,但 SSA 的下游任务性能显著更高。
由于二者唯一区别在于 SSA 具有更稀疏的注意力分布,性能提升最可能源于这种内在稀疏性。消融实验进一步验证了这一点:移除对齐损失后,推理性能下降。
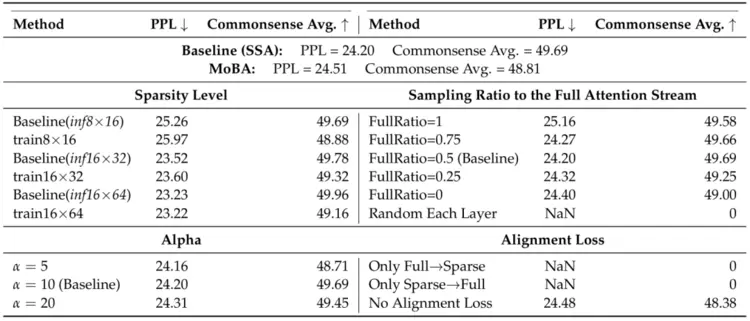
表3 消融实验。Train A×B 表示训练时采用感受视野大小为 A、块大小(bl为 B 的配置;FullRatio 指图2中全注意力流(Full Attention Stream)的采样比例。此外,Only Full→Sparse 表示仅将对齐约束从全注意力单向施加至稀疏注意力路径,而 Only Sparse→Full 则表示对齐方向相反,仅从稀疏注意力向全注意力施加约束。
(3)不同稀疏程度下的外推性能
SSA 在不同稀疏程度下展现出良好的外推能力:随着稀疏注意力中 token 数量增加,其在四项任务上的性能基本呈单调提升。
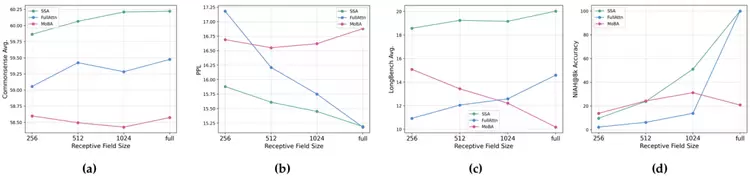
图3 性能与感受视野大小的关系
(4)长上下文评估
表2 在多种上下文长度下的评估结果
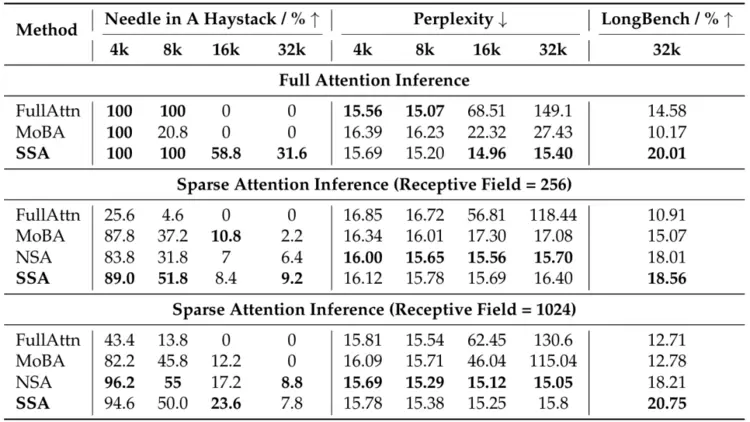
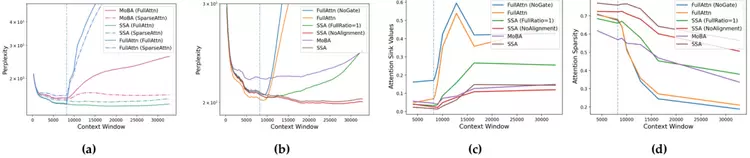
图4 (a) 不同上下文长度下的困惑度。(b) 在 SSA 中提高稀疏注意力训练的比例,可提升模型在长上下文上的外推能力。(c)相较于 MoBA 和 FullAttn,SSA 在局部位置分配了更高的 logits 权重。(d) FullAttn 将大量注意力质量分配给了 8K 以外的 token。其中,图 (a) 使用 1B 参数模型,图 (b–d) 使用 300M 参数模型
如表2所示,在大海捞针任务(Needle-in-a-Haystack)中,SSA 在几乎所有感受视野下(除 1024 外)均为最强的稀疏注意力方法,并在全注意力推理下达到 100% 准确率。
当上下文长度超过训练最大长度(8K)时,FullAttn 性能骤降至 0%,而经稀疏注意力训练的模型仍保持非零检索能力,甚至在全注意力模式下也能恢复可观性能。
在困惑度方面,FullAttn 和 MoBA 在上下文超出预训练窗口后均出现 PPL 剧增;相比之下,SSA 与 NSA 在长达 32K 的上下文中仍保持低且稳定的 PPL。尽管 NSA 的 PPL 略优,但其架构更复杂,且无法外推至全注意力推理;而SSA 在全注意力评估下依然稳定,体现出更强的简洁性与鲁棒性。
在更全面的长上下文理解基准 LongBench 上,SSA 在所有推理模式下均取得最佳结果,进一步验证了其综合优势。
相关文章
- SOTA达成!腾讯优图D-Search算法登顶国际AI权威榜单
- PRCV2025大会顺利召开,腾讯优图携前沿科技成果亮相现场
- 腾讯优图携Youtu-Agent开源项目亮相上海创智学院首届TechFest大会
- 拿下SOTA!腾讯优图联合厦门大学提出AIGI生成图像检测新方法
- Interspeech 2025 | 腾讯优图实验室4篇论文入选,涵盖超声波活体检测、神经语音编解码、语音合成等方向
- ICCV 2025 | 腾讯优图实验室大模型8篇论文入选,涵盖风格化人脸识别、AI生成图像检测、多模态大语言模型等方向
- 最高10倍加速!北京大学联合腾讯优图实验室将 GQA 改造成 MLA形式
- ACL 2025 | 腾讯优图实验室大模型4篇论文入选,涵盖智能体、角色扮演、自动推理等方向
- 超越ControlNet!腾讯优图实验室联合复旦大学提出AI生图新框架,解决多条件生成难题
- 喜报!腾讯优图联合项目获CSIG科技进步奖一等奖
- PRCV 2021 | 视觉AI飞速发展,腾讯优图分享内容理解新实践
- AAAI2022腾讯优图14篇论文入选,含语义分割、图像着色、人脸安全、弱监督目标定位、场景文本识别等前沿领域
- AICon2021 | 腾讯优图鄢科:以AI技术助力内容安全 促进互联网环境健康发展
- 腾讯优图人脸安全能力再获认可!优图专家入选“护脸计划”专家委员会
- 腾讯优图斩获ICCV2021 LVIS Challenge Workshop冠军及最佳创新奖
- CCAI 2021 | 腾讯优图汪铖杰:用AI生成更优更新的内容
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力


