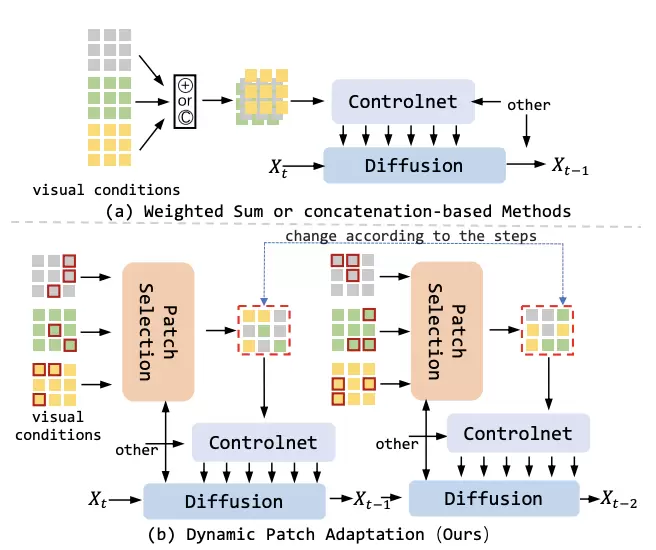
超越ControlNet!腾讯优图实验室联合复旦大学提出AI生图新框架,解决多条件生成难题
2025/05/29 20:24AI云资讯13739
文生图新架构来了!
来自腾讯优图实验室、复旦大学等机构的研究人员最新提出PixelPonder,这是一种新型的多视觉控制解决方案,在多视觉控制任务中显示出多模态融合的巨大潜力。

具体而言,ControlNet架构定义了视觉控制的全新范式,但其统一的时序视觉控制信号阻碍了多模态视觉控制的协同作用,这导致难以实现多视觉联合控制图像生成。
比如你想生成一张“一只在森林里的小鹿”。虽然当前的扩散模型可以实现这个目标,但如果你想加上更多细节,如“小鹿的姿态”、“森林的氛围感”等等,这些不同的条件可能会相互“打架”,导致生成效果不佳。
而在PixelPonder这项工作中,研究人员提出了Patch Adaption,这是一种多视觉控制的全新解决方案,具有多视觉控制任务所需的适应性。
与先前的解决方案在多类测试集的大量实验表明,所提出的Patch Adaption在patch级别上整合了各模态的优势,并在控制力度上优于传统的单视觉控制方案和现有的多视觉控制方案,展示了多视觉控制任务上ControlNet的全新可能。
一种基于补丁的自适应条件选择机制
最近在基于扩散的文本到图像生成方面,通过视觉条件控制展示了令人鼓舞的结果。
然而,现有的类似ControlNet的方法在组合视觉条件方面面临挑战——在多个异构控制信号之间同时保持语义保真度,同时维持高视觉质量。
它们采用独立的控制分支,这往往在去噪过程中引入冲突的指导,导致生成图像中的结构扭曲和伪影。
为了解决这个问题,团队提出了PixelPonder,这是一种新颖的统一控制框架,允许在单一控制结构下有效控制多个视觉条件。
具体而言,团队设计了一种基于补丁的自适应条件选择机制,能够在子区域级别动态优先考虑空间相关的控制信号,从而实现精确的局部指导而不干扰全局信息。
此外,团队还部署了一种时间感知的控制注入方案,根据去噪时间步调节条件影响,逐步从结构保留过渡到纹理细化,充分利用来自不同类别的控制信息,以促进更和谐的图像生成。
大量实验表明,PixelPonder在不同基准数据集上超越了之前的方法,在空间对齐精度上表现出显著提升,同时保持高文本语义一致性。
提出PixelPonder
PixelPonder的整体流程如下图所示。
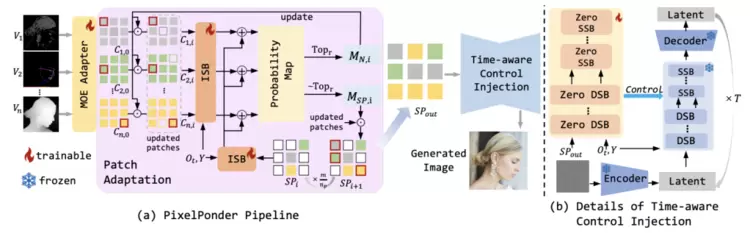
对于各类视觉信号,在每个时间步,采用Patch Adaption获取patch级别上的重构信号,用于控制网络实现精细化的控制信号注入,从而实现高可控生成。
其中,在获取重构信号的过程中,ISB通过各类视觉信号特征以及重构信号的组成状态获取统合概率图。
统合概率图表征了各图像特征的patch挑选倾向,基于概率图,通过自回归的反复迭代获取最终的重构信号,作为ControlNet架构下网络所需输入的统一信号。
参考ControlNet,控制网络由一个较小的流匹配网络构成,与flux的主干网络一一对应,各个模块的输出用于修正主干网络的流生成,从而实现精细的图像控制。
Patch Adaption Module (PAM)Patch Adaption Module(PAM)的目标是将各种视觉条件在补丁级别重新组合成统一的视觉条件。这是通过自回归迭代组合过程实现的,该过程在不同视觉条件之间组合补丁。
将各类视觉特征视为由patch组合而成,也就是:
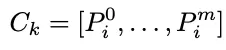
基于此,PAM的自回归更新过程可以简略表达如下:
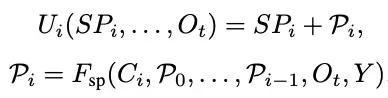
自回归的机制通过Image Stream Block(ISB)能够注意到各类视觉特征中已被挑选的patch和备选patch的隐含关联,并基于当前时间步下图像去噪的状态获取更优的统一信号以优化流匹配路径。
这一过程显著提升了各类模态之间的高低频信息协同作用。
其中,ISB获取概率图的计算公式如下:
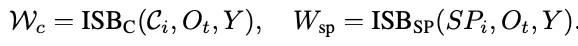
具体而言,ISB基于FLUX的Double Stream Block(DSB)而得,其中包含一个完整的DSB流程。
不同的是,为了确保控制信号的全局信息高度一致,ISB所接受的文本信号以及时序信号是一致的。
最终的概率输出为:
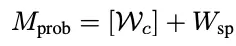
时间步意识的控制注入:来自PAM的统合信号传递到ControlNet。
ControlNet使用一个较小的流匹配网络处理具有时间步特征的统合信号,获取修正流,并注入主干网络,数学形式如下:

实验结果
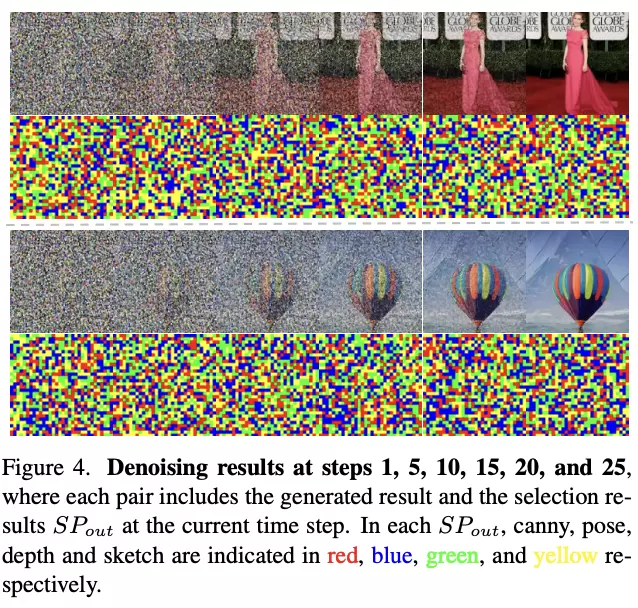
如视觉展示所示,在多视觉控制注入的情况下,现有的其他方法会产生伪影和扭曲的生成。
而PixelPonder能利用各个模态互补的视觉要素生成更稳定,充满细节的视觉图像。

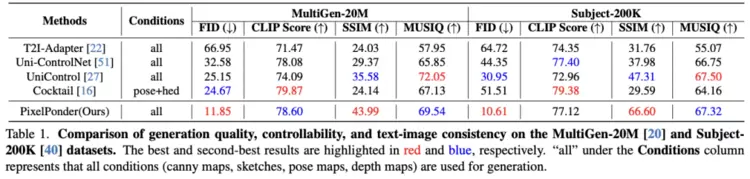
多类别对比实验如下:
单类别对比实验如下:
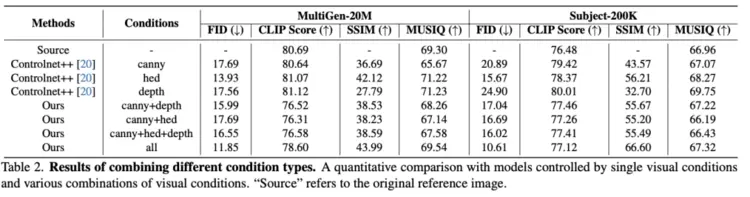
实验显示,在两类不同主题的测试集上,大量的数据(约1w张)结果表明PixelPonder相较于单视觉控制和多视觉控制方案,在视觉和谐度和可控度上有了极大的提升。
同时,在视觉控制和文本控制的trade-off下,文图一致性也保持着领先的水平。
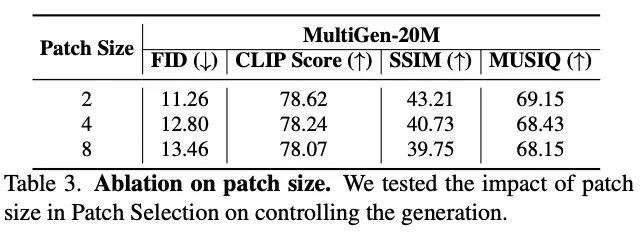
消融实验如下:

总结
在本文中,研究人员提出了PixelPonder,这是一种用于基于扩散的图像生成的组合视觉条件的新框架。
其关键贡献在于解决现有方法在处理来自多个控制信号的冲突指导时的基本局限性。
具体而言,引入了两个新组件:一种基于补丁的自适应条件适配机制,通过可学习的注意力门动态解决空间冲突,以及一种时间感知的控制注入方案,协调去噪阶段中的条件影响。
在多个基准测试上的大量实验表明,相较于最先进的方法,PixelPonder显著提高了性能。通过PixelPonder,用户可以利用各种视觉条件描绘对象的不同方面,从而准确实现他们的各种创作。
论文:
https://arxiv.org/abs/2503.06684
项目主页:
https://hithqd.github.io/projects/PixelPonder/
相关文章
- 千余部纪录片限时免费观看!爱奇艺联合优酷、腾讯视频推出纪录片暑期档活动
- 腾讯WorkBuddy重磅更新,鸿蒙电脑首款桌面办公智能体来了!
- 腾讯ima × WorkBuddy:将中国AI工作流带进全球课堂
- 《全球具身智能技术创新与应用白皮书》首发,腾讯云铸AI数字基座
- 聚焦AI系统性进化 腾讯发布2026人工智能十大趋势报告
- 腾讯云吴运声:智能体成败关键在场景,携手伙伴把智能体带进千行百业
- 腾讯云ADP 4.0 海外版发布,携手伙伴共建场景化解决方案
- 腾讯升级发布具身智能全栈方案,ADP 4.0海外版正式上线|2026 WAIC
- 2026 WAIC丨腾讯AI应用创新论坛,7月18日上海见!
- 联想天禧AI与腾讯Skill Hub达成战略合作,天禧Claw正式接入一站式AI技能平台
- AI智能体从概念走向落地 赞同科技CTO蒲云出任腾讯云AI智能体嘉年华(华东赛区)专家评委
- 领驭科技×腾讯云联合亮相2026深圳国际眼镜业博览会
- 腾讯云发布边缘Web与AI Agent托管平台 EdgeOne Makers:一键开发部署,分钟级全球上线
- 中国企业创新盘点——同时入选《财富》中国科技50强的联想集团与华为、腾讯、阿里
- 腾讯云TVP走进香港数码港,解码AI出海新范式
- 腾讯云以 99.8% 防护率通过AV-C年度评测
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


