基于视觉深度估计的伪激光雷达: 从2D图像到自动驾驶3D目标检测 (IROS)
2019-07-09 09:33:16AI云资讯1681
三维目标检测是自动驾驶中的一项重要任务。如果三维输入数据是从精确但昂贵的激光雷达技术中获得的,那么最新的技术具有很高的准确检测率。到目前为止,基于更便宜的单目或双目图像数据的方法已经导致了精确度大大降低——这一差距通常归因于基于图像的深度估计不佳。然而,在本文中,我们认为,数据的质量并不是数据本身的质量问题,而是数据的表示性能,这是造成差异的主要原因。考虑到卷积神经网络的内部工作,我们建议将基于图像的深度图转换为伪激光雷达表示——本质上模拟激光雷达信号。通过这种表示,我们可以应用不同的现有的Lidarbased检测算法。在广受欢迎的Kitti基准测试中,我们的方法在基于图像的性能方面取得了显著的改进,使30米范围内的物体检测精度从以前的22%提高到目前的74%。提交时,我们的算法在基于立体图像的方法的Kitti 3D物体检测排行榜上占有最高的位置。
主要贡献
首先,我们根据经验证明,立体和基于激光雷达的三维目标检测之间性能差距的主要原因不是估计深度的质量,而是它的表示。其次,我们提出了伪激光雷达作为一种新的三维物体探测深度估计的建议表示,并表明它导致了最先进的立体三维物体探测,有效地将现有技术提高了三倍。我们的研究结果指向了在自动驾驶汽车中使用立体摄像机的可能性——可能会大幅降低成本和/或提高安全性。
算法流程
我们提出了一种基于立体的三维物体检测的两步方法。我们首先将立体或单目图像的估计深度图转换成三维点云,我们称之为伪激光雷达,因为它模拟激光雷达信号。然后,我们利用现有的基于激光雷达的三维目标检测管道框架,我们直接在伪激光雷达表示上进行训练。通过将三维深度表示改为伪激光雷达,使基于图像的三维目标检测算法的精度得到前所未有的提高。
尽管基于图像的三维物体识别有许多优点,但在图像的最新检测率和基于激光雷达的方法之间仍存在着明显的差距。人们很容易将这一差距归因于激光雷达和照相机技术之间明显的物理差异及其影响。我们提出了一种基于立体的三维物体检测的两步方法。我们首先将立体或单目图像的估计深度图转换成三维点云,我们称之为伪激光雷达,因为它模拟激光雷达信号。然后,我们利用现有的基于激光雷达的三维目标检测管道框架,我们直接在伪激光雷达表示上进行训练。通过将三维深度表示改为伪激光雷达,使基于图像的三维目标检测算法的精度得到前所未有的提高。
1.深度估计
使用基于图像合成的深度估计算法,双目相机和单目相机可以在框架中使用.
2.伪激光雷达的产生
我们不需要像通常那样将深度d作为多个附加通道合并到RGB图像中,而是可以在左相机坐标系中导出每个像素(u;v)的三维位置(x;y;z),如下所示:
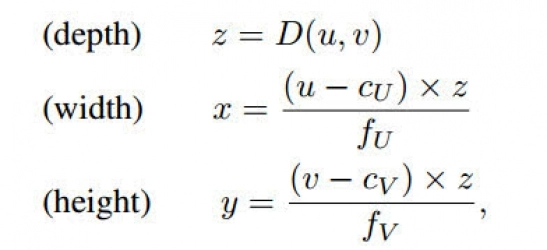
激光雷达与伪激光雷达。为了最大限度地兼容现有的激光雷达检测管道,我们对伪激光雷达数据应用了一些额外的后处理步骤。由于真实的激光雷达信号只存在于一定的高度范围内,我们忽略了超出该范围的伪激光雷达点。

3.3D目标检测
利用估计的伪激光雷达点,我们可以将现有的基于激光雷达的三维目标探测器应用于自主驾驶。在第一个步骤中,我们将伪激光雷达信息视为三维点云。这里,我们使用截锥点网,它将二维对象检测投影到三维截锥中,然后应用点网提取每个三维截锥的点集特征。
在第二个步骤中,我们从鸟瞰图(BEV)中查看伪激光雷达信息。尤其是,三维信息从上下视图转换为二维图像:宽度和深度成为空间尺寸,高度记录在通道中。AVOD将视觉功能和BEV激光雷达功能连接到3D盒子方案中,然后将两者结合起来进行盒子分类和回归。
4.数据表示问题
尽管伪激光雷达传输的信息与深度图相同,但我们认为它更适合于基于深度卷积网络的三维目标检测管道。为此,考虑卷积网络的核心模块:二维卷积。在图像或深度图上操作的卷积网络在图像深度图上执行二维卷积序列。尽管可以学习卷积的过滤器,但中心假设是双重的:(a)图像中的局部邻里有意义,并且网络应该查看局部区域;(b)所有邻里都可以以相同的方式操作。
在左列中,我们显示了原始深度图和图像场景的伪激光雷达表示。场景中的四辆车以彩色突出显示。然后,我们在深度图(右上角)上用一个盒子滤波器执行一个11×11的卷积,它与5层3×3卷积的接收场相匹配。然后我们将得到的(模糊的)深度图转换为一个伪激光雷达表示(右下角)。从图中可以明显看出,这种新的伪激光雷达表示受到了模糊的影响。
主要结果
我们通过不同的深度估计和目标检测方法,评估了在不同设置下有无伪激光雷达的三维目标检测。在整个过程中,我们将突出显示蓝色的伪激光雷达和灰色的实际激光雷达的结果。
1.3D目标检测结果
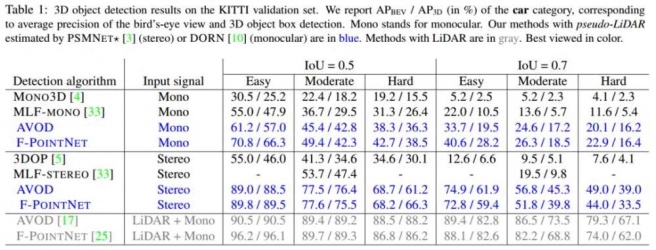 表1KITTI目标检测结果
表1KITTI目标检测结果
2.对比
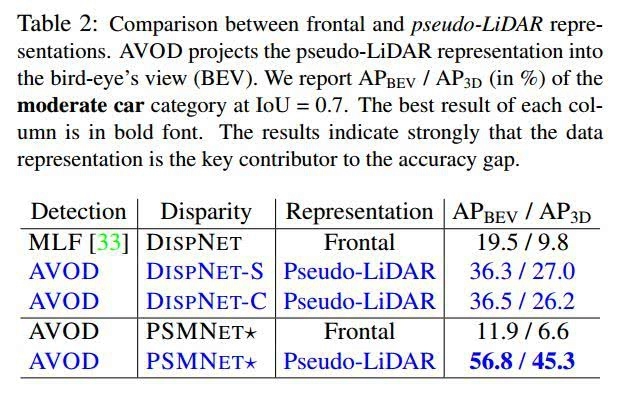 表2 frontal 和伪激光雷达对比
表2 frontal 和伪激光雷达对比
3.比较立体视差和三维目标检测算法的不同组合,使用伪激光雷达。在IOU=0.7时,我们报告了中等车辆类别的APBEV/AP3D(百分比)。每列的最佳结果是粗体。
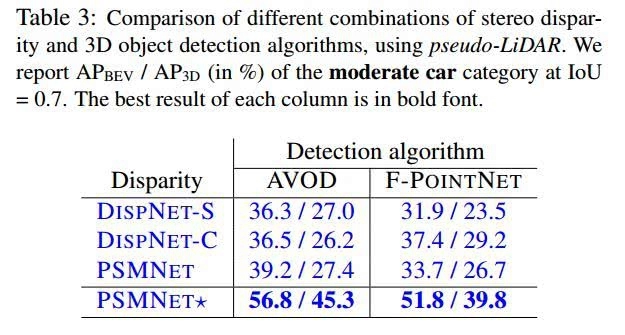
表3比较立体视差和三维目标检测算法的不同组合
4.验证集上行人和自行车手类别的三维对象检测。我们报告的apbev/ap3d为iou=0.5(标准度量),并将f-pointnet与psmnet(蓝色)和lidar(灰色)估计的伪激光雷达进行比较。

图2 3D目标检测效果

图33D目标检测效果2

图4 PSMNET* 与PSMNET对比
相关文章
- 创新奇智稳居中国视觉AI第一梯队 AI私有部署市场走向应用深水区
- 百度智能云升级百度一见视觉智能体平台:内置1000+专业视觉Skills,可自主进化
- 以科学标尺重新定义视觉体验! 京东方发布OLED显示通透感核心研究成果,赋能行业首个通透度标准落地,为用户提供至臻显示体验
- 视觉脑机接口领军企业「暖芯迦」完成新一轮融资,丰年资本超额追投
- 破解数据瓶颈!青瞳视觉Project Decode重磅首发,荣膺“2026具身智能数采贡献奖”
- 望圆科技:融合AI视觉与SLAM技术,推进清洁机器人智能化跃迁
- AI+3D视觉双擎驱动 | OPT&华盛控解锁机器人拆码垛“随机堆叠”新范式
- 专注视觉检测赛道 昆山捷翔以硬核技术打造细分市场“隐形冠军”
- 卓特视觉×刘兵克丨3款特色免费开源字体来了! 商用、个人全解锁
- 哈曼推出面向量产的智能视觉体验解决方案
- Neousys宸曜亮相2026 Vision China上海机器视觉展
- AI拍照解题技术新突破,传音相关研究成果入选计算机视觉顶会CVPR 2026
- “正版+AI”赋能跨境出海,卓特视觉摘得AMZ123“年度领航AI赋能”奖
- 视觉中国发布2025年度ESG报告
- 圆偏光护眼黑科技落地!飞利浦商用显示器关爱职场人的视觉健康
- Vision China 2026(上海)机器视觉展盛大开幕!
AI企业
更多>>




AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


