谷歌公布亚毫秒级人脸检测算法 BlazeFace,人脸检测又一突破
2019-07-31 17:19:51AI云资讯1098

BlazeFace 简介
近年来,通过对深度神经网络中各种架构的改进,我们已经可以实现实时目标检测。在移动应用程序中,实时目标检测通常是视频处理流程中的第一步,接着是各种特定任务组件,例如分割,跟踪或几何推理。因此,目标检测模型推理必须尽可能快地运行,其性能最好能够达到远高于标准的实时基准。
我们提出了一种名为 BlazeFace 的新面部检测框架,该框架是在单镜头多盒检测器(SSD)框架上针对移动 GPU 推理进行的优化。我们的主要创新包括:
1. 有关于推理速度
一个专为轻量级目标检测而设计的在结构上与 MobileNetV1/V2 相关的非常紧凑的特征提取器卷积神经网络。
一种基于 SSD 的新型 GPU-friendly anchor 机制,旨在提高 GPU 利用率。Anchors(SSD 术语中的先验)是预定义的静态边界框,作为网络预测调整和确定预测粒度的基础。
2. 有关于推理效果
一种替代非最大抑制的联合分辨率策略,可在多预测之间实现更稳定、更平滑的联系分辨率。
基于 AR 的人脸检测
虽然该框架适用于各种目标检测任务,但在本文中,我们致力于探讨手机相机取景器中的人脸检测问题。由于不同的焦距和捕获物体尺寸,我们分别为前置和后置摄像头构建了模型。
除了预测轴对齐的面部矩形外,BlazeFace 模型还生成了 6 个面部关键点坐标(用于眼睛中心、耳、嘴中心和鼻尖),以便我们估计面部旋转角度(滚动角度)。这样的设置使其能够将旋转的面部矩形传递到视频处理流程的后期任务特定阶段,从而减轻后续处理步骤对重要平移和旋转不变性的要求。
模型结构与设计
BlazeFace 模型架构围绕下面讨论的四个重要设计考虑因素而构建。
1、扩大感受野
虽然大多数现代卷积神经网络架构(包括 MobileNet,https://arxiv.org/pdf/1704.04861.pdf )都倾向于在模型图中都使用 3×3 卷积核,但我们注意到深度可分离卷积计算是由它们的点态部分主导。在 s×s×c 输入张量上,应用可分离卷积操作,其中,k×k 的深度卷积涉及 s^2ck^2 次乘加运算,而后续的 1×1 卷积到 d 个输出通道由 s^2cd 次乘加运算组成,是深度阶段的 d /(k^2)倍。
实际上,在具有金属外壳的 Apple iPhone X 上,16 位浮点运算中的 3×3 深度卷积对于 56×56×128 的张量需要花费 0.07 ms,相比之下 128 到 128 通道的 1×1 卷积运算会慢 4.3 倍,即后续的点卷积操作需要 0.3 毫秒(由于固定成本和存储器访问因素导致的纯算术运算计数差)。
该观察表明增加深度部分的核尺寸性价比更高。我们在模型架构中使用 5×5 内核,这样使得感受野达到指定大小所需的 bottleneck 数量大大减少,得到的 BlazeBlock 有下图所示的两种结构:
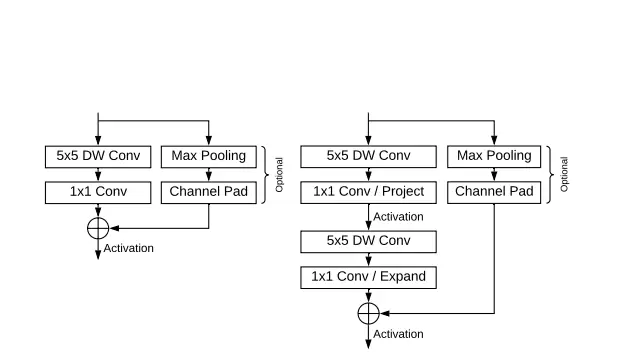
图 1 单个 BlazeBlock (左) 与 双 BlazeBlock (右)
2、特征提取器
对于具体的例子,我们专注于前置摄像头模型的特征提取器。该特征提取器必须考虑较小范围的目标尺度,因此它具有较低的计算需求。提取器采用 128×128 像素的 RGB 输入,包括一个 2D 卷积和 5 个单 BlazeBlock 和 6 个双 BlazeBlock 组成,完整布局见下表。最大张量深度(通道分辨率)为 96,而最低空间分辨率为 8×8(与 SSD 相比,它将分辨率一直降低到 1×1)。
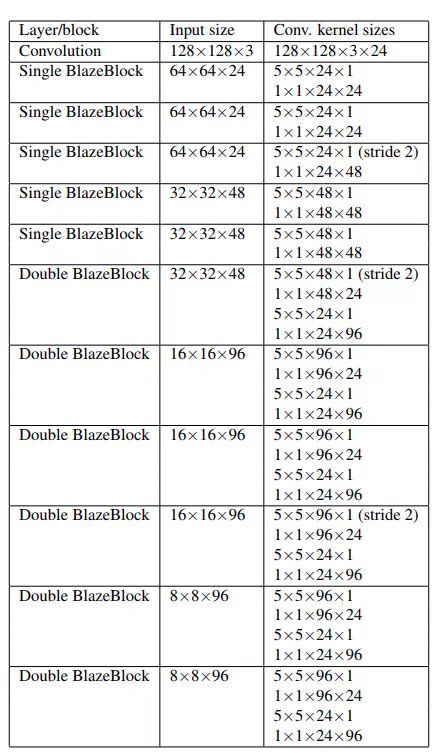
图 2 BlazeFace 特征提取器的网络结构
3、Anchor 机制
类似 SSD 的目标检测模型依赖于预定义的固定大小的基础边界框,称为先验机制,或 Faster-R-CNN 术语中的锚点。为每个锚预测一组回归(可能还包括分类)参数,例如中心偏移量和尺寸调整。它们用于将预定义的锚位置调整为紧密的边界矩形。
通常的做法是根据目标比例范围在多个分辨率级别定义锚点,同时下采样也是计算资源优化的手段。典型的 SSD 模型使用 1×1,2×2,4×4,8×8 和 16×16 特征映射大小的预测。然而,金字塔池化网络 PPN 架构(https://arxiv.org/pdf/1807.03284.pdf)的成功意味着在特征图达到某个特征映射分辨率后,将产生大量额外的计算。
相比于 CPU 计算,GPU 独有的关键特性是调度特定层计算会有一个显著的固定成本,这对于流行的 CPU 定制架构固有的深度低分辨率层而言非常重要。例如,在一个实验中我们观察到 MobileNetV1 推理时间需要 4.9 毫秒,而在实际 GPU 计算中花费 3.9 毫秒。
考虑到这一点,我们采用了另一种锚定方案,该方案停留在 8×8 特征图尺寸处而无需进一步下采样(图 2)。我们已经将 8×8,4×4 和 2×2 分辨率中的每个像素的 2 个锚点替换为 8×8 的 6 个锚点。由于人脸长宽比的变化有限,因此发现将锚固定为 1:1 纵横比足以进行精确的面部检测。
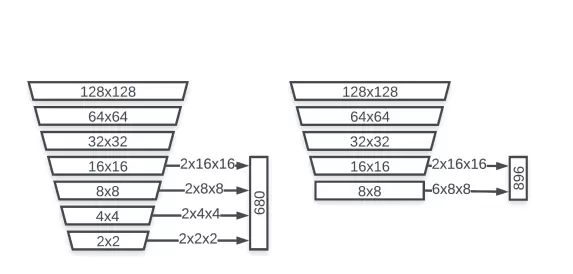
图 3 锚点计算,SSD(左)与 BlazeFace(右)
4、后处理机制
由于我们的特征提取器未将分辨率降低到 8×8 以下,因此给定目标重叠的锚点数量会随目标尺寸的增加而显著增加。在典型的非最大抑制方案中,只有一个锚点被选中作为算法的输出。这样的模型应用于后续视频人脸预测时,预测结果将在不同锚之间波动并且在时间序列上检测框上持续抖动(人类易感噪声)。
为了最小化这种现象,我们用一种混合策略代替抑制算法,该策略以重叠预测之间的加权平均值估计边界框的回归参数,它几乎不会产生给原来的 NMS 算法带来额外成本。对于人脸检测任务,此调整使准确度提高 10%。
我们通过连续输入目标轻微偏移的图像来量化抖动量,并观察模型结果(受偏移量影响)如何受到影响。在联合分辨率策略修改之后,抖动量(定义为原始输入和移位输入的预测之间的均方根差)在我们的前置摄像头数据集上下降了 40%,在包含较小人脸的后置摄像头数据集上下降了 30%。
实验
我们在 66K 图像的数据集上训练我们的模型。为了评估实验结果,我们使用了由 2K 图像组成的地理位置多样数据集。
对于前置摄像头模型,它只考虑占据图像区域的 20%以上的面部,这是由预期的用例决定的(后置摄像头型号的阈值为 5%)。
回归参数误差采用眼间距离(IOD)进行尺度不变性归一化,中值绝对误差为 IOD 的 7.4%。通过上述程序评估的抖动度量是 IOD 的 3%。
图 4 显示了所提出的正面人脸检测网络的平均精度(AP)度量(标准 0.5 交叉联合边界框匹配阈值)和移动 GPU 推理时间,并将其与基于 MobileNetV2 的目标检测器(MobileNetV2-SSD)进行了比较。我们在 16 位浮点模式下使用 TensorFlow Lite GPU 作为推理时间评估的框架。
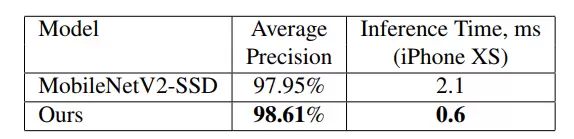
图 4 前置相机人脸检测性能
图 5 给出了更多旗舰设备上两种网络模型的 GPU 推理速度的透视图:
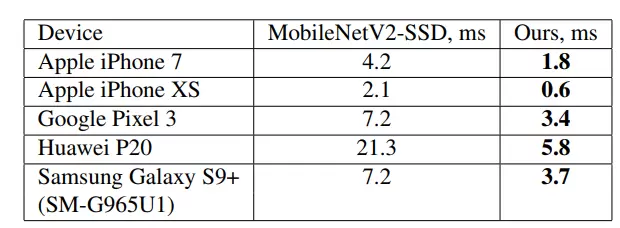
图 5 跨多个移动设备的推理速度
图 6 展示了由于模型尺寸较小引起的回归参数预测质量的退化程度。如下一节所述,这不一定会导致整个 AR 管道质量的成比例降低。
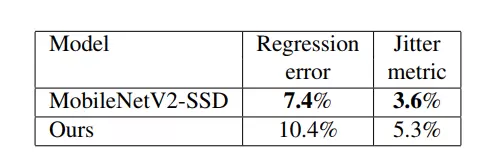
图 6 回归参数预测质量
应用
上述模型可以在完整图像或视频帧上运行,并且可以作为几乎任何与人脸相关的计算机视觉应用的第一步,例如 2D / 3D 人脸关键点、轮廓或表面几何估计、面部特征或表情分类以及人脸区域分割。因此,计算机视觉流程中的后续任务可以根据适当的面部剪裁来定义。结合 BlazeFace 提供的少量面部关键点估计,此结果也可以旋转,这样图像中的面部是居中的、标准化的并且滚动角接近于零。这消除了 SIG-nifi 不能平移和旋转不变性的要求,从而允许模型实现更好的计算资源分配。
我们通过一个具体的人脸轮廓估计示例来说明这种方法。在图 7 中,我们展示了 BlazeFace 的输出,即预测的边界框和面部的 6 个关键点(红色)如何通过一个更复杂的人脸轮廓估计模型来进一步细化,并将其应用于扩展的结果。
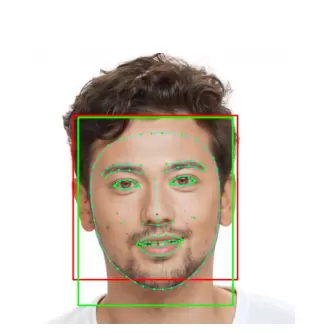
图 7 流程示例;红色代表 BlazeFace 输出;绿色代表任务特定的模型输出
详细的关键点可以产生更精细的边界框估计(绿色),并在不运行人脸检测器的情况下重新用于后续帧中的跟踪。为了检测该计算节省策略的故障,该模型还可以检测面部是否存在所提供的矩形裁剪中合理地对齐。每当违反该条件时,BlazeFace 人脸检测器将再次在整个视频帧上运行。
相关文章
- 谷歌投资A24,共同开发人工智能电影制作工具
- 数据中心耗电远超电网负荷,迫使英伟达与谷歌在2026年第三季度前启动800V直流电架构改造
- 苹果和谷歌新增对Thread 1.4的支持
- 宜选科技出席2026谷歌合作伙伴峰会
- 苹果在新版Siri上作出妥协:依靠英伟达B200 GPU加密技术,防止谷歌窃取用户数据
- 谷歌Beam抢滩多人会议全息赛道,微美全息以AI+5G解锁虚实融合视觉新想象
- Google I/O 2026亮点回顾:晶晨股份携手谷歌共拓端侧AI新生态
- 谷歌搜索的人工智能进化包含更多广告
- 谷歌的未来是一个无所不能的搜索框
- Google I/O 2026:Gemini 将成为谷歌年度开发者大会的主角
- 2026智能眼镜“百镜争鸣”,谷歌/阿里/微美全息引领AR/XR产业全面升级
- 谷歌发布 Chromebook 后继产品——Googlebook
- 谷歌称其首次发现并阻止了一个利用AI开发的零日漏洞
- 谷歌首款AI眼镜即将呼之欲出,微美全息(WIMI.US)扎实推进AI+AR生态落地
- 谷歌母公司发布2026年一季度财报,搜索查询量创下历史新高
- 英伟达Rubin芯片落地谷歌A5X实例,多站点集群规模扩展至近百万颗GPU
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


