放眼人工智能蓝海,数据审核大有可为
2021-07-23 10:03:09AI云资讯891
近年来,随着人工智能的兴起,数据标注与审核行业逐渐成为新兴的人们创业行业之一,对于数据标注与审核来讲,在诞生之初,由于行业需求较小,行业规模不大,因此被人们冠名“人工智能行业的“富士康”。

然而随着人工智能技术的发展落地,数据标注与审核行业正在悄然发生着变化,并将在未来呈现出新的趋势。
首先从智能停车场到无人驾驶,从煤矿挖掘到无人港口,人工智能在不断地改变着世界的潜力,好似没有它无法触及的角落。随着AI行业本身的发展,将进一步带动数据标注与与审核行业。

目前能被建模量化的数据只占真实世界中极少的一部分,现在的数据标注有审核业务主要在自动驾驶、安防、医疗等领域,而随着AI的商业化落地,新的场景数据将不断出现。
其次数据是人工智能底层逻辑中不可获取的支撑要素,标注的质量将成为未来竞争的核心优势。因为人工智能的本质就像人类要不断的通过训练来获取技能一样,AI的根基就是训练,需要经过大量数据进行训练,神经网络才能总结出规律,进而熟能生巧的应用到新样本上。
因此随着应用场景要求不断提升的趋势,机器所需求的数据质量和精度将会越来越高,能提供高质量标注数据的企业与把控标注质量的公司才是市场真正的核心优势。
再次,AI应用几乎囊括了各个行业:工业制造、农业、金融、政务、互联网、服务业等。人工智能的范畴也不再局限于早先的人脸识别、语音识别,而是越来越深化到自然语言处理、知识图谱、人机交互、大数据处理、隐私计算等。
在2021世界人工智能大会上,华为公布了盘古超大规模预训练模型,腾讯则宣布要提供AI技术与中国天眼一起寻找脉冲星。AI的每一次新领域探索,都是需要海量高质精准的数据做支撑的,市场对于数据标注与审核行业的需求量将会更多更精准。
最后,国内人工智能发展已迎来转折时期,从早先技术层面的炒概念,落到了实际应用中——无论消费互联网还是工业互联网领域,各个领域对AI技术及应用的需求大量涌现,推动着AI+行业落地开花。
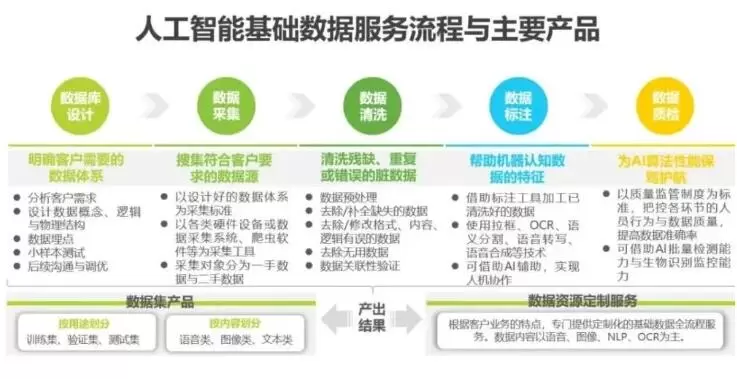
AI的落地第一需求就是高质精准的数据。在数据标注与审核行业中有一个‘garbage in garbage out’的理论,即如果标注完的数据精度达不到标准,那么训练出来的算法也是不精准的。
在这样的大趋势下,数据标注与审核行业随着AI的纵向深入发展,将稳步向前。
相关文章
- 微软2025年的碳排放量增加了25%,可持续发展解决方案未能跟上人工智能需求的步伐
- 深耕人工智能赋能教育,探索育人新模式 —— 天立依托 AI育人实践交出阶段性答卷
- 聚智向善 赋能未来:中国联通数智创新成果亮相2026人工智能向善全球峰会
- 中国移动江苏公司开展“人工智能+制造”专项宣讲活动
- 第7届电力人工智能大会暨第5届电力行业数字化转型大会,10月相约杭州!
- “AI设计师”上岗记:佛山“小巨人”用AI重塑“工业之母”丨佛山向新·人工智能+③
- 复旦大学博导曾新华加盟网萌科技出任人工智能首席科学家,全面赋能电商数智化服务创新
- 三星借助量子计算赋能芯片制造技术追赶台积电,人工智能将重塑芯片制造最关键的环节
- 华为中国行2026·新疆人工智能+产业峰会成功举办
- 探寻人工智能2026|对话张亚勤:智能体落地提速,中国基建构筑AI竞争优势
- 泛在AI:下一代人工智能终极落地形态,东数新业以原创根技术构筑数字经济新质生产力底座
- 谷歌投资A24,共同开发人工智能电影制作工具
- 云从科技参与共建广州市粤港澳大湾区人工智能应用赋能中心
- 中电信人工智能公司跻身IDC报告中国智能体开发平台私有化市场份额前五
- 上海智位机器人正式加入鸿蒙生态,Mind+适配鸿蒙PC共推人工智能教育普及
- 解码AI未来 2026世界制造业大会人工智能与机器人展9月启幕
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布


