寒武纪第四代MLUarch03构架采用chiplet(芯粒)技术
2021-12-13 20:21:40AI云资讯1496
近日,寒武纪正式发布第三代云端AI芯片思元370、基于思元370的两款加速卡MLU370-S4和MLU370-X4、全新升级的Cambricon Neuware软件栈。
回顾今年年初1月,寒武纪思元290智能芯片及加速卡、玄思1000智能加速器在官网低调发布,这是寒武纪今年发布的第二款产品,这在业界实属难得。毕竟芯片行业基本2-3年推出一款或一代芯片,外加根据不同客户需要,还要1-2年的适配导入周期。
先从三个方面,解读下本次寒武纪370的优势所在。
在架构上,思元370属于寒武纪第四代自研智能芯片架构,第一代架构MLUarch00主打智能加速IP核,第二代MLUarch01主打多核架构,第三代MLUarch02主打多核共享片内存储,第四代MLUarch03更是寒武纪首款采用chiplet(芯粒)技术的AI芯片,在国内应该也属于行业首颗chiplet AI芯片。
在应用场景灵活性上,由于思元370在一颗芯片中封装2颗AI计算芯粒(MLU-Die),每一个MLU-Die都具备独立的AI计算单元、内存、IO以及MLU-Fabric控制和接口,不同MLU-Die可以组合规格多样化的产品,为用户提供适用不同场景的高性价比AI芯片。
在算力上,基于台积电7nm制程工艺、整体集成390亿个晶体管的思元370最大算力达到256TOPS(INT8),相比上一代思元270算力直接翻倍。
此外,思元370,不仅可以作为推理芯片,也可以作为训练芯片使用。这样做的好处不仅是寒武纪自己的产品能够兼顾训练与推理,也方便客户全流程的模型部署、业务落地。
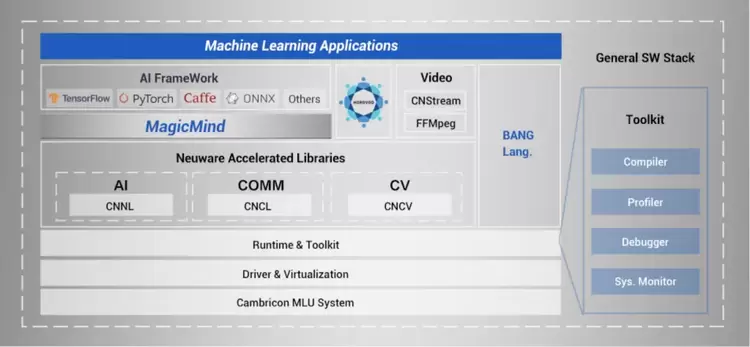
实际上,寒武纪发布的首颗训练芯片思元290,在训练为主的同时也可以进行推理。借助Cambricon Neuware软件栈提供的软件及应用生态,就可以在思元290芯片上实现图形图像、语音、NLP、搜索推荐等多种应用的训练和推理。
此次思元370发布,Cambricon Neuware进一步整合了训练和推理的全部底层软件栈,包括底层驱动、运行时库、算子库以及工具链等,将MagicMind和深度学习框架Tensorflow、Pytorch深度融合,实现训推一体。依托于训推一体,在寒武纪全系列计算平台上,从云端到边缘端,用户均可以无缝地完成从模型训练到推理部署的全部流程,进行灵活的训练推理业务混布和潮汐式的业务切换,加快了用户端到端业务落地的速度,减少模型训练研发到模型部署之间的繁琐流程,可快速响应业务变化,提升算力利用率,降低运营成本。
在外界看来,一代接着一代是分段的。但对于寒武纪来说,每一代架构之间都是互相勾连、镶嵌、攒接的,虽然每更新一代处理能力提升、效率优化都很大,但代际之间并非替代关系,而是适配不同的市场,从而实现资源的最大化利用。比如思元370和思元290之间就不是替代的关系,因为前者主要是推理芯片,后者主要是训练芯片,两者是互补的关系。
以每一代的架构为基础,都可以开发出适合不同端的IP、芯片矩阵。而每一款芯片,又都会分成不同组件,比如按照十几个组件设立十几个研发小组,每个小组来做一个组件,最后把组件拼起来形成智能芯片。不同的小组可以根据项目需求,对组件进行多种组合、拼接,并实现不同芯片功能组件上重叠部分的高效复用。
一方面,这就使得云、边、端、车不同芯片拥有很多可以复用的组件与设计,让“云边端车”协同优势成为可能;另一方面,这也使得过去的积累不会因为业务线变化而浪费,哪怕是现在总营收占比已经很小的IP授权业务,对于其他覆盖面更多的业务线,仍然有着生态拓展、技术复用的价值,比如在边缘侧智能芯片设计上复用。
相关文章
- 寒武纪业绩快报:2025年营收同比增长超4倍,盈利指标全面转正
- 寒武纪2025年业绩大幅增长 登顶胡润AI企业榜单
- 算力需求激增引风口 寒武纪技术迭代赋能智能化升级
- “硬核创新”寒武纪入选2025福布斯中国创新力企业50强
- 锚定智能算力机遇:寒武纪以技术创新响应行业差异化需求
- 《2024胡润中国人工智能企业50强》发布:寒武纪荣登榜首
- 探索创新人才培养模式 寒武纪积极开展产学合作
- 寒武纪积极助力人工智能的实际应用落地
- 寒武纪AI训练卡MLU370-X8荣获2023年度卓越创新产品奖
- 寒武纪统一的平台级基础系统软件打破开发壁垒
- 寒武纪通用型智能芯片:技术壁垒高但应用面广
- 寒武纪:通用型智能芯片在性能和功耗上存在优势
- 寒武纪:具备云、边、端芯片产品和生态开发协同优势
- 寒武纪2022年业绩说明会:研发成果显著,核心技术持续突破,知识产权积累创新高
- 寒武纪入选星辰20:2023中国AI算力层创新企业
- 寒武纪灵活多样产品满足多元市场需求
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力
- 昇腾原生支持,科学多模态大模型Intern-S1-Pro正式发布并开源
- 百度千帆深度研究Agent登顶权威评测榜单DeepResearch Bench


