四年成准独角兽 明略数据缘何成为慢2B市场的一匹快马
2018-07-24 18:24:38AI云资讯1393
四年时间,明略数据已成长为大数据领域的标杆公司,完成C轮10亿人民币的融资,并逐步由大数据公司向行业人工智能公司进化。
2017年,爱分析曾对明略数据进行了深度访谈(每年3倍增长,成立三年的明略数据渐成公安大数据标杆 | 爱分析调研),当时明略数据已从面向多个行业,转变成聚焦安防、金融、工业的垂直领域解决方案公司。过了一年,明略数据有哪些新的进展?产品体系日趋完善,业务产品化率不断提升
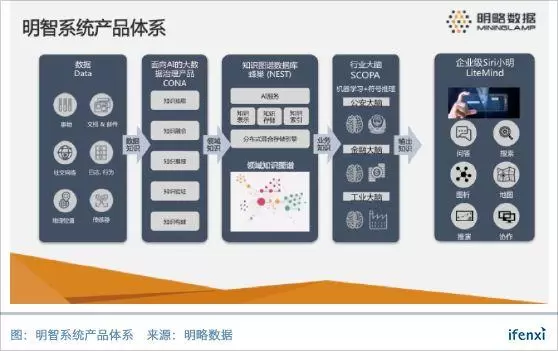
此前,明略数据的产品只包含大数据基础平台MDP、关联分析SCOPA和数据挖掘Data Insight。2017年下半年,明略数据发布了几款新产品,产品覆盖从数据治理到数据应用,体系正趋于完善。
从整个业务流程来看,CONA将明略数据接入的各类结构化和非结构化数据,清洗成知识图谱的基础元素实体、属性和关系,建立了基于垂直行业的知识图谱,NEST这款知识图谱数据库对知识图谱进行存储和计算,通过SCOPA和Data Insight实现垂直行业的数据应用,最后通过“小明”LiteMind实现与业务人员的交互。
从功能来看,数据治理CONA和知识图谱数据库NEST此前涵盖在SCOPA,是明略数据在服务公安、工业等行业客户时,发现数据治理和知识图谱构建非常重要,才逐步将其产品化。
通过将重要组件做成完整产品的方式,明略数据正逐步将业务流程模块化、产品化,提升各项产品的灵活性和兼容性,尽管前端服务客户仍然配备了驻场科学家团队,但通过将业务模块化的方式,明略数据正在逐步提升业务的产品化率。
以服务市级公安局客户为例,原先基于客户20%的数据做建模应用,需要半年时间。现在,借助CONA、NEST等一系列产品和工具,处理客户80%数据只需要2个月的时间。
通过这种方式,明略数据正逐步依靠产品去降低对人力的依赖。当明略数据将全部流程实现产品化,形成整个业务闭环,产品可以解决警务人员的大部分问题时,明略数据切入的客户预算就将从IT预算变成人力资源预算、业务预算,客单价会大幅提高,市场空间更大。公安等重点行业业务深化,数据治理能力构建核心壁垒
公安是明略数据的重点行业,也是当前贡献收入最大的行业,2018年,明略数据在公安领域的行业应用进入到全新的阶段。
此前,明略数据主要针对市公安局的单一警种做大数据应用,如刑侦、经侦、缉毒等,2018年,明略数据开始与一些市级公安局进行深度合作,帮助市公安局建立全局的统一大数据平台,并在平台之上围绕着全局20-30个警种开发各类行业应用。
建设市级统一大数据平台,意味着明略数据从单个项目的解决方案厂商,逐步变成一家定位垂直行业的平台级公司,当整个平台搭建完成后,其他厂商都需要基于明略数据的平台开发应用,很难有其他厂商彻底替换掉明略数据,建立了很高的竞争壁垒。
明略数据业务属性过重,可规模化复制性差,但这一点恰恰构成了明略数据的核心壁垒。
公安、工业领域存在大量图像、文本等非结构化数据,需要大量的数据治理工作,同时基于这些数据构建行业知识图谱,需要非常理解行业应用场景,才能构建适合业务场景的数据关系结构。
此外,明略数据在做单个场景应用时,公安领域特意选择了多个警种,通过三年时间,明略数据覆盖了公安领域几乎所有警种,接触到了几乎全部公安领域的相关数据,为下一步做统一大数据平台打下基础。
上述这些工作都需要大量人力投入,需要数据科学家、数据工程师在客户现场,不断与行业专家进行探讨,结合双方的技术能力和行业经验才能完成。因此,明略数据的核心壁垒实际上是建立在这些驻场科学家团队身上,这些人所具备的数据治理能力是至关重要的。
通过重咨询属性的整体解决方案能力,搞定标杆客户,再通过不断将业务流程产品化、模块化的方式降低对人力依赖,提升人均产能。整个业务模式是“先重后轻”。
经过四年发展,明略数据已经实现了第一步,搞定了数十个市级公安局,拿下上海地铁等工业轨道交通标杆客户,下一步将是如何提升产品化率,提高人均产能。

近期,爱分析对明略数据的创始人吴明辉进行访谈,他对明略数据的业务模式、未来战略,以及他对行业未来趋势的判断进行阐述,现将部分访谈内容分享。新产品CONA和NEST解决行业数据“脏乱差”的问题
爱分析:原先MDP之上只有SCOPA,所以之前CONA和NEST是在SCOPA里面?
吴明辉:是的,我们做SCOPA的时候,参考了Palantir一些产品原型。服务客户时发现,真正的痛点不是在展示界面,而是下面“脏乱差”的数据,如何将这些脏乱差的数据连起来,让SCOPA去使用。
最开始我们只是做了一些工具,但是后来发现这个事情越来越重要,最后我们就把它变成一个独立的产品线。
今天我们可以看到各行各业都存在这个问题,不光是公共安全。公共安全的数据是最复杂的、也是最“脏乱差”的。因为很多数据不是面向公安业务设计的,它可能来自社会方方面面的数据。举个例子,有些数据原来是社会企业的系统,主要用来管理企业业务,不是用来破案的。
不同的城市、区域、部门,以前这些系统都是不同的厂商去建立,我们要把这些全部都连到一起,这个工作量是非常大的,所以我们后来就发现,这个问题是未来大数据在每个行业里面落地的巨大痛点。同时,这件事情做不好,人工智能无从谈起。
爱分析:CONA这个产品,和传统ETL公司Informatica等有哪些区别?
吴明辉:区别很大。首先,我们CONA面向的原始表数据库,很多都不是标准的关系数据库,复杂性会高很多。
这些数据中会存在大量的非结构化的内容,比如,短信里面的时间、地点、人名。再加上我们有些时候需要对接各类人工算法识别的结果。这些都需要能够映射到统一的数据结构。
第二,映射到统一的数据结构,这个结构本身是要有行业知识,比如说在公安里面,有人、事、地、物、组织这样的标准知识图谱,这个知识图谱是我们的团队跟公安行业里面最优秀的这些IT专家,一起设计出来的公安业务知识。
第三,面向的解决方案也不是简单的BI统计,我们可以在上面去做逻辑推理。因为数据全都结构化后,才有机会去做逻辑推理。这个推理不是一个简单的表和表、字段和字段之间的关系,而是背后的深刻含义,这个知识体系已经建立起来。
有了真正的知识体系,才能在上面去做研判、做推理,所以跟传统的ETL有蛮大的区别。
爱分析:像NEST产品,定位更多是图数据库?
吴明辉:不是一个简单的图数据库,我们的目标是把NEST构建成为一个像人的大脑一样的存储系统,什么存储都可以做,各种类型的索引都兼容,除了传统的表结构索引,还包括K-value的索引,全文检索、图等。
其实人的大脑存不同信息的时候,用的索引模式是不一样的。大脑的索引其实特别灵活,随便将数据扔进去存下来,要调用的时候,聪明的人很快就把它调出来了。而且,人的自我学习和认知的升级过程中,其实是在更新自己的大脑索引。
我们的公安系统里面经常遇到这个问题,比如说突然发明了一种新算法,这时候是不是所有索引都要重新建。人类的重建是瞬间就完成了,也就是顿悟。但是,你会发现我们现在计算机的数据库做不到,他不太可能顿悟。
我们现在就在着力解决这个认知科学问题,将各类型数据存到系统中,再不断叠加知识,让计算机像人一样学习。这个事情解决了,我们就可以做人的外脑。
爱分析:这个产品完全是自研的还是基于开源做的?
吴明辉:是自研的,底层存储技术大量有开源产品,图数据库有开源的,每种索引有开源的,因此,每种技术都有开源的,但如何利用这些技术。上层架构要做到既有工程的冗余备份,又有足够的灵活性,这些才是核心。
爱分析:明略数据一直有支驻场团队,这个团队会长期保留?
吴明辉:效率会不断提高,NEST等产品不断成熟,随着这些人对数据越来越懂,效率一定会提升。
但我觉得他们面对的问题在不断变复杂,随着这个系统不断产生效果,会有越来越多的数据进入到这个系统,因此,很难被替换掉。公安领域,今年战略目标是建立真正的“公安大脑”
爱分析:公安是明略数据做的最好的行业,过去这一年在向哪些方向延伸?
吴明辉:我们其实去年做了一个很重要的战略部署。去年服务了30多个城市级的公安局,在服务的过程中,我们有意的在不同的城市选择了多样性的警种。因为公安系统有不同的子部门,刑侦、经侦、禁毒等20-30个警种,不同的警种面向的数据是不太一样。
我们应该是整个公安系统唯一一家,各个警种数据都碰过的公司。
我们今年的大战略目标是,我们会去选择一些标杆的城市级公安局,去合作整个地市级公安局的大平台,把所有数据全部连起来,形成一个真正的公安大脑。现在正在几个标杆的城市做试点。
因为公安大脑必须把所有的数据都连起来,在一个局部做事情是没用的,但是这种苦活累活很重要,必须各种数据都碰过,否则也没有能力去做。
爱分析:能做这个事情的原因除了接触过各类型数据,还有哪些其他要求?
吴明辉:架构能力决定了这件事情最后的效果,因为需要对整个社会的数据理解非常深刻,有的时候甚至是个哲学问题,要思考整个社会底层是如何运行的,这些方方面面的数据到底应该如何存储和调用。
只有把这些架构想清楚,才能做数据治理。数据治理工作已经不再是简单地做ETL。
爱分析:现在做成这种大平台模式,客单价会达到什么量级?
吴明辉:如果做到城市级,做整个城市大脑,每年投资额会上亿元,这里面包括软件、硬件、包括上云、数据治理等。其中数据治理是这里面最重的工作。我们有很多合作伙伴提供软件和硬件,我们主要是做最辛苦的数据治理。
爱分析:这种城市平台级项目,软硬件投入占比大概是什么比例?
吴明辉:软硬件比例在1:1或者1:2,硬件占比更高一些。国外的规律基本都是1:1,国内长期小于1:1,但是我觉得硬件规划做得越来越好,尤其是云化之后,硬件资源浪费会变少,这时候政府预算会逐步朝软件倾斜。
爱分析:现在来看,整个项目中服务比例应该还是高于产品比例的?
吴明辉:服务的比重的确会更重一点,因为我们现在的数据治理,本身有很大的人工服务。
爱分析:一般一个市级项目需要投入多少人去做?
吴明辉:现在这种城市级大平台需要很多人,因为现在是做试点。我们之前做单个警种,可能需要5-10个人驻场。
爱分析:公安领域,明略数据现在做了三十多个省市,现在做整个城市平台的试点,影响这种城市平台推广的因素有哪些?
吴明辉:核心是地市级的领导、一把手做这件事情的决心,因为这就是一把手工程。
爱分析:未来会考虑做到省级?
吴明辉:我们现在主要是聚焦于市级,省级更多是一些研究项目和联合实验室。因为公安领域,更多的实战是市级,省级更多是作为指导。
爱分析:但从未来趋势上看,会不会整个省建立一个统一的大数据平台?
吴明辉:应用不一定,数据已经在省级有汇聚的趋势。
爱分析:给省级提供数据平台的公司会逐步向下渗透吗?
吴明辉:给省级提供平台的更多是华为云、阿里云等IaaS厂商,他们不理解应用,而且也不太愿意做这些苦活累活。
爱分析:服务公安这样领域的客户,需要哪些方面的能力?
吴明辉:首先,要有在各地市落地驻场实施的能力,管理体系要强,因为这个数据就是拿不出来,没有机会。这不同于银行,银行的数据会汇聚到总行,只需要在一个地方。其次,就是融资能力。没有融资能力支撑不了这么大的团队。这两个是硬能力。
此外,拿下客户的能力,这跟市场品牌、科学家团队能不能让客户信服。
还有就是技术产品能力,产品是为了提高利润率,不做产品就需要能有更好的价格,但客户也不会白给预算。如果有一定产品化率,其实就会有利润,否则就很难赚到钱。
爱分析:未来这个市场规模您是如何判断的?
吴明辉:现在还主要是建眼睛的阶段,眼睛建完后开始建大脑。大脑其实由两部分组成,下面是云平台,上面是我们的系统。到那个时间点,云平台都建的差不多了,主要预算肯定都放在我们这套系统上。
现在这个时间点,肯定是雪亮工程,预算都用来买硬件,涉及到我们业务的,现在其实预算还不大。金融定位行业知识图谱,工业领域聚焦轨道交通的数据共享平台
爱分析:金融行业,之前明略数据做过一段时间的评分,现在是如何考虑的?
吴明辉:与做公安比较类似,通过构建行业知识图谱,挖掘内在关系。比如营销,我们现在主要做的是,利用知识图谱帮客户从老用户身上发掘新用户。我们和保险公司合作,从投保人身上发掘,能不能让投保人的太太来购买保险。
爱分析:现在金融主要做的是哪些场景?
吴明辉:我们在银行和券商做的多一些,主要是反洗钱、内部审计等。我们还会做对公信贷业务的数据分析,因为这里面有大量的非结构化数据的处理,这部分也是我们公司的强项。
爱分析:金融类业务现在有哪些典型客户?
吴明辉:现在做全行知识图谱的公司其实很少,我们其实是拿了第一个,光大银行。我们金融类客户主要定位于股份制银行,因为四大国有银行对创新更谨慎,因此,股份制银行是发力重点,之后会下沉到城商行,最后才是大行。
爱分析:工业领域,明略数据主要是做轨道交通,现在主要做的是哪些场景?
吴明辉:我们现在主要精力是放在数据共享平台上,轨道交通主要分为两类数据,线路和车。我们之前做了一些车辆的数据,现在开始接触路网的数据。我们的目标跟公安一样,就是先做数据融合和治理,帮助我们的这些客户在构建AI平台之前,做好数据准备工作,一定是知识化的数据。
爱分析:数据共享平台之上会延伸哪些场景?
吴明辉:比如智能运维,甚至是无人驾驶。像特斯拉现在只有车的数据,当他接入路况等数据,毫无疑问智能驾驶会做得更好。
爱分析:工业领域设备数据采集是个大问题,因为现在并没有通用协议和接口,这个问题明略数据是如何解决的?
吴明辉:主要还是通过设备制造商,设备运营商客户很多是不清楚内部数据的情况。机缘巧合,我们最开始MDP卖到了中车,因此搞清楚了数据结构,现在服务中车下游公司会相对容易。
爱分析:工业领域,下一步会如何扩?
吴明辉:我们会从轨道交通,扩展到整个大交通范围。定位垂直领域解决方案公司,目标是AI时代的IBM
爱分析:纯粹技术角度,明略数据在行业应用领域的主要优势是体现在前端数据处理?
吴明辉:其实企业级服务的技术很难有“一招鲜”,通常是每一个环节都要比竞争对手好。有的时候,这个地方多一个功能,那个地方性能好一点,最后是一个累计的效果。
有一个竞争优势是,只要是我们进入的行业,我们的数据融合和理解能力绝对是这个行业最顶级的,因为这是我们投入最大资源做的地方。
爱分析:服务能力是否有一些指标去评判?
吴明辉:客户在做任何业务的时候,他会有数据的列表。最简单地方式是,最短时间用什么样的成本,可以将他数据列表中的80-90%数据变成AI算法可用的。
爱分析:前端驻场数据科学家团队目前价值度还是很高?有没有方式降低对这类人的依赖?
吴明辉:我觉得一时半会都降低不了,这个事情就是很重,但这也是企业的核心价值。其实,企业和企业最后PK的就是组织资源能力,人是最核心资源,其次是融资。
爱分析:所以,未来明略数据还是会把自身向类似集成商的角色转变?
吴明辉:可以这么理解。
爱分析:相比Palantir,明略数据的产品化率更高,这主要是什么原因?
吴明辉:主要是我们公司体量相对较小,还是主要聚焦于几个行业。当覆盖的行业越多,产品化率会越低。当然,每个行业做的时间长,产品化率会提高。
我最早做MDP的时候是不分行业的,后来发现这个事情不可行,我就快速开始砍行业,一开始是五个行业,后来变成三个行业。
爱分析:明略数据最后会成为一个类似IBM的公司?或者类似Oracle?
吴明辉:准确来讲,更像是IBM。但是IBM这种公司,它在各行各业的具体问题和业务落地上,会有很多定制化的工作,这些工作不可能开源的,虽然有行业的重复性,但没有那种全人类社会的重复性。因此,长期还是很容易作为一个生意而存在。
爱分析:IBM的人均产能大概是25万美金,这会不会就是明略数据的天花板?
吴明辉:那是之前的IT服务,未来AI服务不是这样的,永远不要用过去预测未来。数据治理是很重的业务,我们不指望这里面产生多高的利润率。
一旦是数据治理完,上面的AI是爆发式指数级的增长。如果AI能力真的非常牛,和公安领导谈的不是IT预算,而是人力资源预算,这个系统节省了100万个警察,那应该卖多少钱?
但是,今天这些脏乱差的活不做,未来AI是做不了的。
爱分析:很多做应用的公司,很容易陷入到做项目中,难以做产品,明略数据是如何兼顾这两方面的?
吴明辉:主要看创始人的价值观。我是个做产品出身的人。我在创办秒针系统之前是做过系统开发的,所以本身我很熟悉项目开发,另外,我本身的数学功底使我有很强的项目抽象能力。
爱分析:明略数据自己一直没有做数据,未来会不会补上这方面的能力?
吴明辉:我们不会倒买倒卖数据,互联网数据抓取的事情,我们将来可能也会去尝试。数据源如果有独特价值,我们会去做投资或者并购。
但坦白来讲,很多数据都多种渠道去获取,不如去买。因为有七八家公司提供,所以购买的时候,可以通过比价选择成本最优的。反而如果内化到企业内部,反而效果不好。
相关文章
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力
- 昇腾原生支持,科学多模态大模型Intern-S1-Pro正式发布并开源


