自动化网络空间资产测绘,螣龙安科的实践指南
2023/03/27 15:44AI云资讯11618
不过短短数月,ChatGPT又一次爆红
全球的科技巨头们也开始“蹭热点”,关于AI新技术的发布会也都层出不穷,一时间百花齐放。
(发布产品Bard现场答错问题的)谷歌发布会、(发布AIoffice全家桶来革打工人命的)微软发布会、(展示了很多PPT和录像的)百度发布会……
前几天,英伟达GTC2023的春季发布会将这股AI热潮彻底推至新高点。

英伟达最开始被大家所熟知的,是其应用于游戏领域的出色显卡能力。1999年,英伟达就推出了全世界第一个GPU(GraphicsProcessingUnit:图形处理芯片)。
但是因为GPU优秀的图像处理及大型矩阵运算能力,现在也被广泛地应用于深度学习和人工智能(AI)方面——它作为ChatGPT运作的“心脏”,为其提供了超强算力支撑。

“TheiPhonemomentofAIhasstarted.”
这句话在一个多小时的发布会中被英伟达CEO黄仁勋强调了三次。
这场发布会,几乎完全聚焦于人工智能。
发布内容从计算光刻、芯片、DGX超级计算机、DGXCloud云服务,一直聊到了AIFoundations平台等。
从基础设施到产业应用布局,英伟达彻底把握了AI时代的算力脉门,所有AI相关的企业,在软硬件这一块,都要向英伟达交入场费。

这场发布会上,最受瞩目的莫过于是集成英伟达核心技术的全新GPU推理矩阵(inferencelineup)。
它包括了4种不同的配置:
-GraceHopper(超级芯片)
-NvidiaH100NVL(用于部署ChatGPT类的大语言模型)
-NvidiaL4(用于制作AI视频)
-NvidiaL40(用于2D/3D图像生成)

在一一介绍各芯片的功效时,老黄也花了挺大篇幅在芯片升级对于大语言模型类的系统算力提升上。
其中,GraceHopper和NvidiaH100NVL,都是为大语言模型(ChatGPT就是大语言模型的一种应用)量身打造的。
大语言模型为什么会对GPU有特殊需求?
GPT类大语言模型的升级,需要更为庞大的训练集。
2018年,GPT初代训练参数量为1.2亿个,训练数据规模是5GB
2019年,GPT-2训练参数量为15亿个,训练数据规模是40GB
2020年,GPT-3训练参数量为1750亿个,训练数据规模是45TB
从上面的信息就能明显看出:
第二代模型较第一代的训练参数增长超10倍,训练数据规模增长近10倍。
第三代模型较第二代的训练参数增长超100倍,训练数据规模则增长超1000倍。
每次仅仅用了一年的时间。
上周最新版的GPT-4,网传其训练参数已经达到了3000亿????。
在不久的未来,模型的训练参数甚至有可能迈入万亿级别,这就对其模型的底层硬件提出了更高要求。

在这次发布会之前,性能最强大GPU是英伟达的A100(特斯拉的自动驾驶也是用的它),随着人工智能的不断发展,硬件和成本已经成为嗜需突破的瓶颈。
本次发布的GraceHopper和NvidiaH100NVL,就是在解决这一问题。
GraceHopper,由GraceCPU和HopperGPU连接而成,拥有一个900GB/秒的高速接口。两者的超强结合,能够部署50亿-2000亿参数级别的任何大语言模型。
NvidiaH100NVL,基于Hopper,由两个94GB的HBM3内存的GPU共同组成,专为LLM设计,采用了Transformer(我们后面会讲到)加速解决方案。
相比于之前的A100,H100NVL实现了“更快更强”。
一台搭载四对H100和双NVLINK的标准服务器能将现有使用A100的服务器速度提升10倍。
也就是说,对于现在的ChatGPT的训练速度可以快10倍,并且还可以将处理成本降低一个数量级。原本10天的训练周期可以快速缩短到一天。
GraceHopper和NvidiaH100NVL,充分满足了大语言模型对于内存和算力方面的需求。
一般而言,8个性能最好的GPU(A100)就可以带动英伟达的超级计算机DGX。
而训练出一个ChatGPT,硬件层面则需要数以万计的GPU。
这就是为什么GPT在如此庞大的训练集下,保持高速算力的同时,还能不崩的原因之一:用最先进最前沿的硬件搭建起来的稳定架构。
“OpenAI在训练模型时所需要的云计算基础设施规模,是当时业内前所未有的。网络GPU集群的规模呈指数级增长,也超过了业内任何人试图构建的程度。”
微软负责战略合作伙伴关系的高管PhilWaymouth在本月微软发布的官博中如此表示。
目前ChatGPT所使用的A100,价位在10000-15000美元,数万A100的堆叠,背后是数亿美元打底的巨额财力支撑。
这还不算每天的运维成本。
此前,据美国科技博客Techcrunch报道,运行ChatGPT的成本约为每个月300万美元,相当于一天烧掉10万美元。
按前段时间ChatGPT每天活跃用户100万来计算的话,ChatGPT每回答一人问题,其成本大约有一毛。
GPT-4应用于ChatGPT消息发布的当天,官网一度被挤爆,所以现在的成本可能远不止这个数额。
天价投资和运维的背后,离不开金主爸爸源源不断的财力输送。
从2019年到现在,微软前后给OpenAI投了110亿美元。
2019年第一轮10亿美元投资的时候,微软联合OpenAI打造了一台性能位居全球前五,拥有超过28.5万个CPU核心、1万个GPU、每GPU拥有400Gbps网络带宽的超级计算机——AzureAI超算平台。
当然,微软投资OpenAI的效益,现在大家也都看到了。
微软运用AI成果顺利完成了一轮对自身产品线的反哺,解锁了Bing、Edge、Copilot等工具的AI功能,带来了新一代升级。
微软、英伟达,都是OpenAI的重要股东。
一个出钱,一个出基础设施。
要想再出现一个ChatGPT,没有这种深厚的资金实力和技术壁垒,可能只会是ChatPPT。
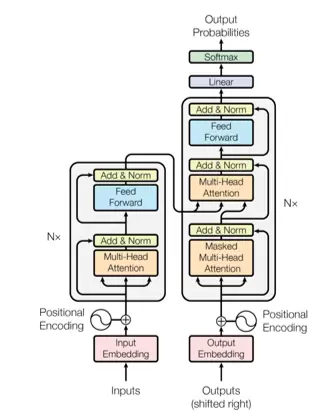
GPT能拥有如此庞大的算力,不仅仅是几乎不计成本地用顶尖硬件搭建起来的稳定架构,更要归功于它底层的深度学习模型——Transformer。
什么是Transformer?
它是一种NeuralNetwork(神经网络架构)。

当年Transformer的发布,也是划时代性的。
可以说是语言基础模型的iPhonemoment也不为过。
它出现以后,能够大规模将数据“投喂”给模型的时代来临。
Why?
在Transformer问世之前,我们用来处理语言的模型主要是RNN,其最显著的特点就是顺序分析。
它相当于是语言模型的起点,通过大量的统计训练,用第一个词来猜下一个词,类似于搜索引擎中的自动补全功能。
谷歌搜索引擎的语言推荐和谷歌翻译都是用的这个原理。
RNN的特性也是其局限性,对于序列性的依赖,导致它的训练只能“循序渐进”,难以具备高效的并行计算力。
而且,它对长序列的数据处理不佳,有一个上下文的限制性,比如我刚输入18个字符串,它处理到后半程可能就开始“烧脑”,以至于能把前面处理完的数据给“忘”了。
这种特性和表现,也就导致了基于RNN的模型训练集有限,训练速度慢,模型准确率也差。
Transformer
Fromsequentialtoparallelized
彻底打破了这种序列性的限制。
最早是2017年由谷歌和多伦多大学共同研发、提出的,不过它最初只是用来翻译。
光看它的工作原理架构图可能有点抽象,不太好懂。
我们可以来看一下它的运作特性来理解。
PositionalEncodings(位置编码)、Attention(权重)、Self-Attention(自权重)
这三大特性也是它区别于其他模型,看起来这么“聪明”的核心原因。
PositionalEncodings(位置编码)
Transformer通过使用内置编码,获取语句中的所有单词后在每个单词后额外加一个按其顺序排列的数字,实现大规模并行处理。
从曾经的理解词语负担转移到只需要处理数据,处理速度的指数级上升得以让它“跑得快”。

我们对于Transformer特性的理解与总结,以作参考
Attention(权重)和Self-Attention(自权重)
可以简单理解为计算机语言里对于“语言”的理解。
语言模型在输出文本时对内在逻辑和规律的“洞悉”,是需要通过大量的语料库训练而来,而不是仅靠人为设定的规则。
通过训练,它们了解到各类型单词之间的关系,以及如何尊重语法的多样性和规则,因此有了权重的文本语言往往更类人言而非词不达意的机器语言。
深度学习模型,即底层神经网络模型的运作逻辑巨变,带来了深厚影响。
从只能按顺序演进到可并行处理,可以大规模将数据“投喂”给模型的时代来临。
Transformer之后的语言模型,才能真正称之为“大”语言模型。
也是我们现在常说的,为什么数据给的越多,训练时间越长,模型会跑得越好,甚至GPT-3的1750亿量级的参数都能处理,原因之一,就在这里。
OpenAI看到了Transformer模型的划时代意义,将其运用于GPT的创造,5年来,一路背靠金主爸爸和硬件爸爸,带着GPT疯狂迭代更新,也就有了让全世界都叹为观止的AI应用:ChatGPT。
ChatGPT在全球的走红,还是因为它足够“通人性”+“好用”,让人们看到了AI商业化应用的潜力和巨大价值。
比起陷入认为AI会取代自身工作岗位的悲观氛围,我更倾向于AI是新时代的福音,会将我们从重复的脑力劳动中解放出来,释放新的创造力。
ChatGPT是人工智能科技革命的缩影。
实际上,2010年前后,以人工智能、云计算、大数据、物联网等组成元素的新一轮科技革命就已开始孵化、孕育和成长。
最简单的例子,智能汽车、新能源汽车现在已经开始逐步替代传统燃油汽车,广泛地应用生产生活。
而科技革命爆发的标志就是新一代科技成果开始广泛应用生产生活,解放生产力、发展生产力,提高全要素生产率。
宏观层面
AI已在科技、医疗、金融、图像、物流配送等各行各业的应用场景中大显身手。
微观层面
AdobeFirefly、CopilotX、Microsoft365Copilot……更自动化,更智能化,AI在一系列设计/编程/办公软件中表现不凡,
新应用的井喷式涌出,也让格子间打工人从被设计/编程/办公软件支配每一天,到只要输入指令就可以实现自动化的内容生成,即使初版不那么好,需要人工调整改稿,也是相当“省心”了。
AI或将成为人类历史上第四次里程碑式的科技革命。
我们都期待这一天。
相关文章
- 智云先锋 | 天翼AI云电脑护航影刀RPA自动化进阶之路
- Solar应急响应团队:一次管家婆漏洞事件,揭开 AI 自动化漏洞审计与勒索攻击的新趋势
- Solar应急响应团队丨AI 正在改写漏洞战争:从管家婆 211 端口 RCE 看自动化勒索攻击链
- 九科信息企业级Agent,打通企业全链路智能自动化
- WPS开源鸿蒙性能瓶颈自动化分析工具,帮助开发者快速锁定性能瓶颈
- QQ音乐沉浸式音频自动化生成新突破 臻品全景声3.0核心算法论文被国际顶级学术会议收录
- 捷象灵越与极智嘉达成深度合作,共拓全球托盘自动化市场
- 全球首条!尼卡光学百万片级体全息光波导自动化产线在天津正式投产,以未来产业铸产业未来
- 亚马逊发布Proteus智能机器人,自动化升级伴随大规模裁员潮
- 【智造链动·聚力共赢】富士康自动化核心技术交流会(越南)活动完满落幕!
- 荣获“国机杯”卓越奖!安世亚太以多智能体协同引领CAE仿真从自动化迈向“数字工程师”
- 林德自动化亮相机器人产业质量安全盛会,以安全可靠理念赋能产业健康发展
- 九科信息,以企业级自动化Agent重构数智生产力
- Testin XAgent拆解:大模型+多智能体如何重构测试自动化工程
- 深耕晶圆自动化新赛道 锚定强链补链大方向——日扬弘创以核心技术突破重塑磨抛工艺新格局
- 格雷希尔G80P系列快速密封接头助力卡钳自动化密封测试
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


