京东AI 在AAAI 2019崭露头角 8篇论文被收录
2019-01-30 15:45:28爱云资讯
美国时间1月27日,AAAI2019大会在夏威夷正式拉开序幕,AAAI作为全球人工智能领域的顶级学术会议,每年评审并收录来自全球最顶尖的学术论文,这些学术研究引领着技术的趋势和未来。京东AI近日公布,其AI研究院在本次大会上有8篇论文被AAAI收录,内容与京东零售场景紧密结合,涉及自然语言处理、视频图像处理、机器学习等领域。同时,在AAAI2019大会期间,京东还设有人工智能的展区,与全球专家学者探讨人工智能的在零售供应链领域的技术创新和应用成果。
据悉,本次大会投稿数量高达7745篇,录取率仅为16.2%,较往年相比,录取难度大大提升。京东AI研究院共有8篇论文入选AAAI2019,研究领域涵盖与京东零售场景紧密贴合的自然语言处理、视频图像处理、机器学习等技术领域,在2019年首场AI顶会中展现了京东人工智能研究的实力。以下是京东AI入选论文:
机器学习
《AutoZOOM: Autoencoder-based Zeroth Order Optimization Method for Attacking Black-box Neural Networks》提出了一个高效搜索的黑盒攻击通用框架(Autoencoder-based Zeroth Order Optimization Method,AutoZoom),包含两个主要部分:1. 自适应的随机梯度估算策略,用于平衡搜索数量和扭曲,2. 一个自动编码器,既可以用未标注数据在线下训练,也可以是加速攻击的双线性尺寸调整操作。实验结果表明,在不牺牲攻击成功率和视觉质量的情况下,模型搜索量显著减少。
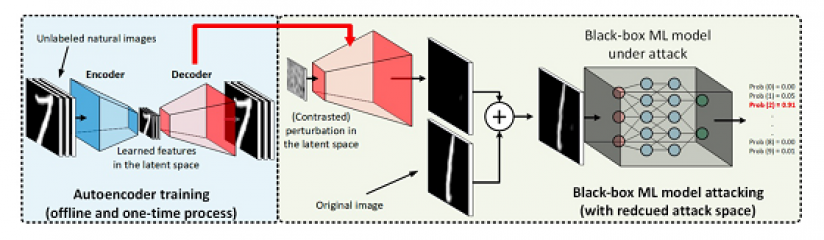
高效搜索的黑盒攻击通用框架示意图
《MPD-AL: AnEfficient Membrane Potential Driven Aggregate-Label Learning Algorithm for Spiking Neurons》提出了一个新的膜电位驱动的聚合标签学习算法,称为MPD-AL。利用该算法,从神经元的膜电位轨迹中识别最容易修改的时间点,并根据突出前神经元在此时间点的贡献来指导突触适应。实验结果表明该算法可以使神经元产生所需数量的脉冲,并从无关脉冲活动与背景噪声中检测到有用的线索,从而比TDP1和多脉冲Tempotron算法有更高的学习效率。此外,我们提出了一个用于难以定义聚合标签的分类任务的数据驱动的动态编码方法。该方法在语言识别任务中有效地提高了聚合标签学习算法的分类精度。
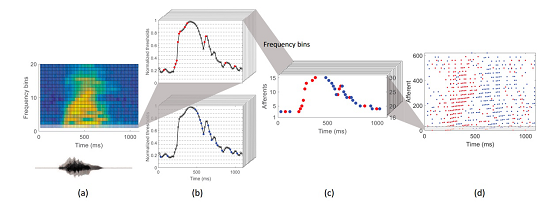
阈值编码机制的示意图
自然语言理解
《End-to-end Structure-Aware Convolutional Networks for Knowledge Base Completion》围绕知识图谱嵌入技术提出一种新颖的端到端结构感知卷积网络(SACN),将GCN和ConvE的优势结合在一起。SACN由加权图卷积网络(WGCN)的编码器和称为Conv-TransE的卷积网络的解码器组成。WGCN有效利用知识图节点结构,节点属性(表示为WGCN中的附加节点)和边缘关系类型等信息生成图节点嵌入。WGCN具有可学习的权重,可以动态调整本地聚合中使用的邻居节点的信息量,从而实现更精确的图节点嵌入。Conv-Trans解码器通过WGCN生成的图节点嵌入和新估计的图链接嵌入实现了图链接预测功能。 解码器中使用了改进的ConvE保持了图节点嵌入和关系嵌入之间的可转换性。我们在标准的FB15k-237和WN18RR数据集上验证了新提出的SACN的有效性。实验结果表明SACN在HITS@1,HITS@3和HITS@10等指标上比之前的ConvE提供了大约10%的相对改进。
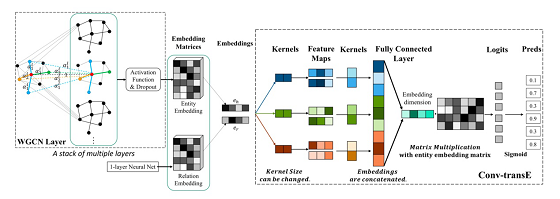
端到端结构感知卷积网络(SACN)样例示意图
《Attentive Tensor Product Learning》中提出了一种注意张量积学习(ATPL)方法,用于在深度学习模型中表示自然语言的语法结构,其创新点在于能够使用无监督学习得到的无约束角色向量来提取句子的语法结构,提高自然语言处理任务的有效性,降低人工标注成本。这种方法可以在图像描述、词性标注等领域获得应用,结合京东电商平台商品识别等业务场景,可以帮助京东向平台的商户和用户提供更优质的服务。
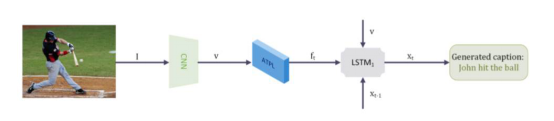
图像字幕体系结构示意图
计算机视觉
《Hierarchically Structured Reinforcement Learning for Topically Coherent Visual Story Generation》在视频内容生成描述方面提出了一种分层结构的强化学习模型。首先,一个 high-level 的解码器 Manager (用LSTM表示) 生成语义连贯的主题,输入给 low-level 的解码器 Worker (用 Semantic Compositional Network, SCN 表示) 生成视频描述。模型基于混合的最大似然和强化学习进行训练。在 VIST 数据上的自动和人工评测表明该模型的结果优于其他深度学习模型。
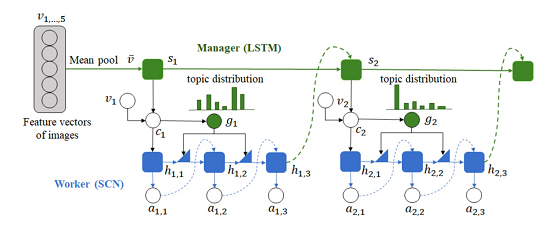
图5. 分层结构强化学习模型的框架结构示意图
《Structured Two-stream Attention Network for Video Question Answering》提出了一种结构化的two stream attention network,用以回答对于视频内容的开放式的自然语言问题。 首先,用结构化片段和编码后的文字特征来推测视频的时序结构;然后,结构化的two stream attention元素同时定位重要的视觉内容,减少不重要内容的干扰。最后,融合内容和询问的不同片段,生成回答。测试结果表明,此方法相比传统方法有更好的表现。
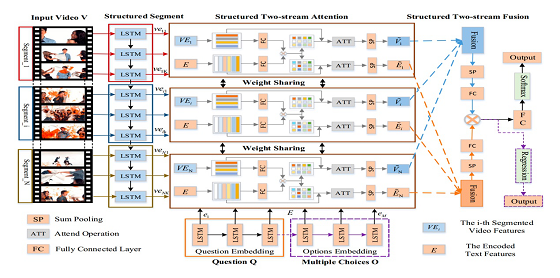
图6. 结构化的two stream attention network框架结构示意图
《To Find Where You Talk: Temporal Sentence Localization in Video with Attention Based Location Regression》提出了一种自动定位一句话在相应的视频中的起止点的方法。该方法基于关注点的位置回归算法(Attention Based Location Regression, ABLR)。为了保留上下文信息,ABLR首先将视频和文字描述用bi-directional LSTM网络加密;然后用多模co-attention方法生成视频和语句的关注点。视频关注点代表视频的整体结构,语句关注点显示了句子的时序位置细节。最后我们设计了一个新的基于关注点的位置预测网络,从之前的关注点对语句的时序坐标进行回归计算。我们在两个公开数据集ActivityNet和TACos上的实验表明,我们的方法从效果和效率的角度均优于已有方法。
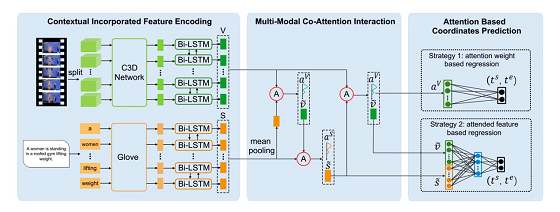
图7. 基于关注点的位置回归算法(ABLR) 框架结构图
《Temporal Deformable Convolutional Encoder-Decoder Networks for Video Captioning》则提出了一种新的结构设计——时序可变形卷积编码-解码网络(TDConvED)。TDConvED分别使用时序可变形卷积块和偏移卷积块来构建编码和解码网络,通过堆叠若干个卷积块来对长序列进行建模,缓解了传统递归网络在训练优化上带来梯度消失/爆炸问题的影响,提升了训练速度。视频描述是AI领域最具挑战的任务之一,有效地解码视频内容信息,将在定制化广告推荐、实体零售场景数据搜集等应用中具有实际应用价值。
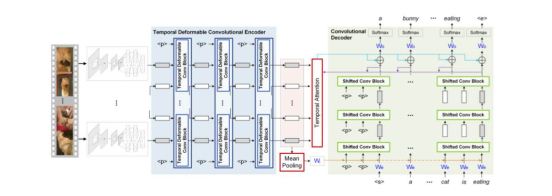
图8. 时序可变形卷积编码-解码网络(TDConvED)示意图
不难看出,京东AI正致力于探索多模态数据的处理,使文本信息、图像信息、视频信息之间的信息转换和处理更加紧密,并基于京东海量数据支持,电商、物流、金融全链条场景的深耕,将知识图谱、语音语义、计算机视觉等技术在时尚、商品推荐、实体零售等领域持续落地应用;这也标志着京东人工智能产学研用,四位一体的进程正在加速落地,解决实际问题,释放社会价值。
登陆夏威夷 京东用人工智能+场景打造无界零售的未来
京东集团副总裁,AI平台与研究部负责人周伯文博士曾多次指出:“将人工智能技术系统性地、大规模地、一致性地应用到在公司的主营业务,是应用人工智能技术助力企业转型升级的关键。目前京东已经在零售全链条场景中应用人工智能,从新购物入口到和用户的交互、到内容的生成、到客户服务、到物流、再到供应链,我们在用人工智能重构零售的每一个环节。”
AI作为京东打造无界零售下商业基础设施的核心之一,除了满足京东主营业务外,也开始将AI能力整合在NeuHub平台,连接供给侧和需求侧。对内全面支持京东各业务板块的人工智能应用落地,对外输出人工智能产品服务与解决方案,致力于通过人工智能打造开放共赢的产业生态。在去年11.11期间,累计调用量达到148.7亿次以上。11.11当天,NeuHub平台单日调用量最高,达到15.3亿次以上。
人工智能如何进行技术和产业的融合一直是AI行业和企业关注的重点。改变正在发生,京东正在用人工智能改变着自己,在中国技术与产业的融合正在如火如荼进行,在全球学术的研究也在思考技术的应用价值。2019年,相信会在更多的全球顶级学术、科技大会上看到京东的身影,深耕技术与实体经济的融合,持续探索技术的边界与应用价值,推动产学研用的一体化,用技术驱动零售产业发展,以开放的视野为社会创造更大价值!
- 5499元起!4月22日京东正式开售HUAWEI Pura 70、Pura 70 Pro+
- 品质之选,钜惠来袭,技嘉AORUS DAY京东品牌会员日活动特惠放价
- 性价比天花板爆款来袭,防晒、出行、宅家速来京东京造“超级品牌日”
- 京东集团与爱丁顿中国达成战略合作 The Macallan麦卡伦京东官方旗舰店盛大启幕
- 华为Pura 70系列斩获100%好评率 京东搜“漂亮系列”入手新机
- 世界读书日加入京东“校猫领阅官” 读书打卡赢取iPhone 15、猫粮等好礼
- BOE(京东方)越南智慧终端二期项目开工 发布Smart GOAL战略开启发展新篇
- 京东先人一步首发联想 YOGA Book 9i AI元启 专享一年免费上门服务
- 内置联想小天个人智能体 联想发布的AI PC新品京东均同步开启预约
- 联想AIPC全系新品重磅发布 京东3C数码采销直播间先人一步直击现场
- ThinkBook AI PC系列新品京东开售 “先人一步”尝鲜价7499元起
- 京东先人一步上线影石Insta360 X4相机 丰富AI功能助你拍摄精彩视频
- 荣登京东工业类图书榜首!《高通量多尺度材料计算和机器学习》开启材料研发“快车道”
- 京东奔图达成战略合作“产品+服务”双升级提升打印体验
- 京东开启激光4K投影大赏 邀你探索家庭影院的N种打开方式
- 五一宅家乐装备首选京东 小度添添两款新品在京东上线





