大模型推理成本居高不下,浪潮存储帮你来突围!
2025-08-19 10:56:49AI云资讯2633
“模型推理是最直接跟AI应用相关的环节,更多的数据、更大的模型以及更长的上下文窗口能够带来更高效的人工智能。但是有个问题,更高的智能要求的推理负载极重,模型参数以及推理过程中产生的KV Cache都需要很大的存储空间。”
------清华大学教授、中国工程院院士 郑纬民
如郑纬民院士所说,模型推理是最直接跟AI应用相关的环节,也是连接模型训练和应用落地的桥梁。当前,大模型推理仍需要借助GPU算力来实现,在大模型推理过程中会产生大量的KV Cache并存到GPU服务器的HBM显存中。对于连续长文本对话而言,抛弃已有的KV Cache无疑会让GPU服务器陷入“重复计算”的陷阱,延长回复时间,降低用户体验,而要存储全部的KV Cache则需要更多的GPU服务器,这无疑会极大拉高AI infra的建设成本。在这种情况下,如何存储推理过程中产生的KV Cache,避免重复计算,在保证响应速度的同时降低大模型推理的成本,是当前大模型应用落地所面临的最关键的问题。
如果把大模型推理比作连环漫画创作,场景是这样的:
长篇漫画作者小刘有个习惯:创作新话时,总会先回顾前话的全部内容,再参考过往情节脉络逐话推进剧情。每一话完结后,他会把核心情节写在便利贴上(K/V),贴在工作室的“漫画故事墙”(KV Cache)上。后续创作时,他只需扫一眼墙上的便利贴,就能快速衔接前情,不用再翻旧稿。
可读者催更太频繁,开的连载越来越多,一话接一话的内容堆下来,“漫画故事墙” 渐渐贴满了,再也塞不下新的便利贴。没办法,他只能回头翻完整的漫画书,一点点回顾前情。扩大“漫画故事墙”固然可以,但是工作室砸墙扩墙的成本实在太高了。最近编辑催得越来越紧,小刘急得直转圈:怎样才能在截稿日前提高效率,按时交稿呢?
专业漫画家小李(Inspur Data)给出了以下几点方案:

其一,超大档案柜随时补。小李为小刘提供了一个“剧情档案柜”,并给它起了一个响当当的名字——AS3000G7!“漫画故事墙”放不下的便利贴就放到剧情档案柜,小刘回顾漫画内容时,即便“漫画故事墙”没有,档案柜也能够及时补上,给“漫画故事墙”扩了容。
其二,小张调度有一套。有了“档案柜”还不够,还得让小刘能快速取用便利贴才行!为加快取用速度,小李为小刘配备了画稿调度员小张(IO管理容器)。小张是个能人,小刘对剧情便利贴的需求大时,他派多个助理同时去档案柜取(智能多路径优化),“漫画故事墙”便利贴快空时,他立刻安排档案柜补全,还趁小刘更新漫画间隙,提前把热门漫画的历史内容搬过来(动态缓存管理)。无论历史内容便利贴存放还是取用,小张都能安排得顺畅高效。
其三,老赵管理有高招。为了提高档案柜的使用效率,小李推荐了档案管理员老赵(Turbo KV加速引擎),老赵更有诀窍。他把历史剧情便利贴定向规整存放(KV Cache定向压缩),同样的空间能多存一半。他还把那些放了半年没有翻过的历史剧情稿及时清理(容量管理加速),让档案柜空间得到充分利用。
接下来,我们将一一介绍这三个推理效率提升手段背后的实现原理及主要价值。
01外置存储:用“剧情档案柜”突破容量极限
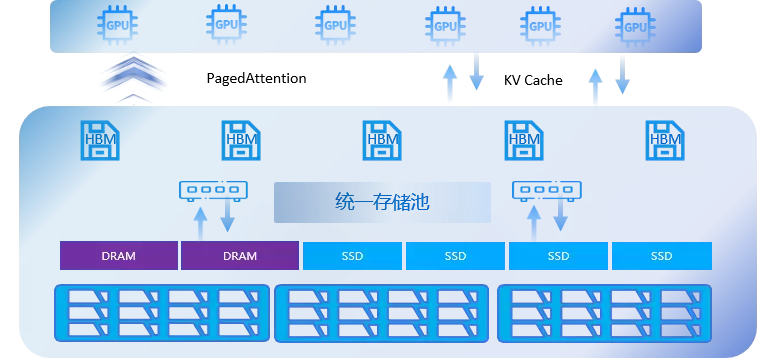
大模型在推理过程中会产生大量的KV Cache,如DeepSeek-70B每10分钟就会产生25TB的KV Cache,这些KV Cache需要存储到GPU服务器的HBM显存里,以加快连续长文本对话的反响应速度。而在当前主流的GPU服务器中,HBM显存容量普遍不超过128GB,相对动辄几十、上百TB的KV Cache来说,显然有些不够看了。
为了处理这类问题,外置存储成为学研用界都在考虑的方案。基于此,浪潮存储推出专为提升大模型推理效率的推理加速存储----AS3000G7。
在硬件上,AS3000G7采用硬件池化技术,对HBM显存、DRAM、SSD存储资源进行统一整合,虚拟为统一资源池。同时采用Pagedattention技术来对接大模型,对KV缓存进行“分块-局部计算-跨页关联”,将长序列分割成固定大小的Block,并通过虚拟页分配技术实现非连续内存分配,进一步提升存储资源池的利用率。通过AS3000G7,可以将HBM的空间“扩展”300多倍,减少GPU重复计算带来的资源消耗,TTFT降低90%。
02 智能调度:让“画稿调度员”盘活供需链路
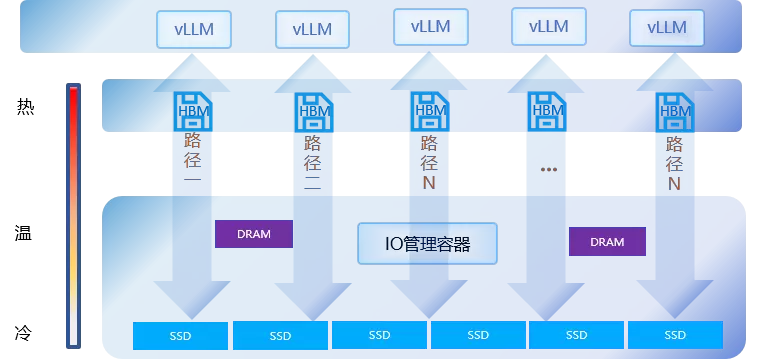
仅用外置存储来存储KV Cache并无法完全实现连续长文本对话的快速响应,原因显而易见:DRAM和SSD的读写速度与HBM存在近百倍的差距(HBM:1-3TB/s,DRAM:40-50GB/s,SSD:10-15GB/s)。因此,加快外置存储和HBM之间的通信是保证外置存储方案落地的关键点。
针对这个问题,AS3000G7提出了IO管理容器的方案。在应用过程中,AS3000G7和大模型结合进行智能多路径优化,为每个LLM层分配独立NVMe队列,实现多GPU张量并行下的many-to-many连接,针对LLM高频、随机、小IO特征(10KB-160KB),动态优化数据传输路径。同时,AS3000G7基于动态缓存管理技术对vLLM调度器算法进行了优化,实时监控Block使用频率,将高频Block保留在HBM,低频Block下沉至AS3000G7,KVCache可以基于使用频率在不同的介质中自由流动。通过动态缓存管理和智能多路径优化,AS3000G7支持的GPU服务器吞吐量(Token/s)可达原方案5倍,单位GPU资源可承载更多推理请求。
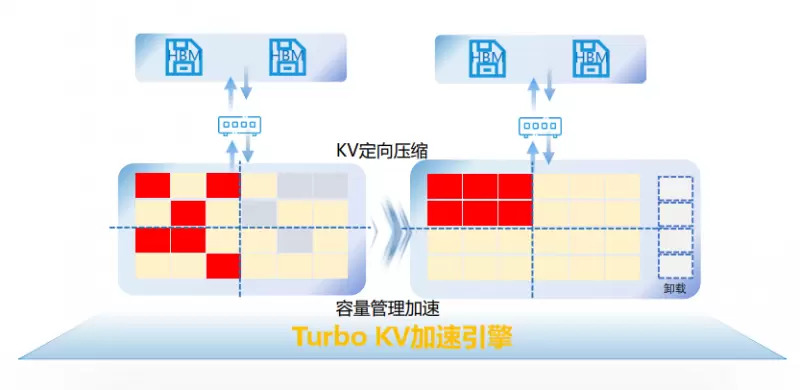
03 精细管理:靠“档案管理员”提升经营效率
对于大模型的存储集群而言,充分利用存储空间同样有助于降低大模型推理成本。AS3000G7采用KV Cache定向压缩技术,针对LLM重复KV进行优化,降低SSD写放大,提升空间利用率。同时,AS3000G7采用容量管理加速算法,基于TTL/LRU策略对无效KV Cache进行卸载,并通过自定义的Block Container元数据结构,精准追踪跨层(KV缓存层、HBM层、SSD层)的关联KV块,实现“卸载一个对话路径=净化整个计算链路”。与原方案相比,AS3000G7存储KV Cache数量可增加50%
小刘听了专业漫画家小李的建议,立刻照着方案动了起来。有了 AS3000G7 “剧情档案柜”当 “大储备”,小张调度剧情便利贴又快又准,老赵把档案柜打理得井井有条,小刘创作时,不管是从 “漫画故事墙” 直接取用还是从“剧情档案柜”调取前情,速度都比以前快了大半。多话连载衔接时,剧情随用随取,卡壳的时间少了,哪怕同时推进好几部连载也能稳稳应对。更重要的是,不用再花冤枉钱砸墙扩 “漫画故事墙”,成本降了,效率却提了上来 —— 曾经让小刘头疼的截稿压力,这下全解决了!
相关文章
- 人人都有大模型,千匠网络押注的是落地能力
- AI大模型产业应用创变营顺利举办,智数集团携东莞软协共探AI产业落地路径
- 全球前三!中国电信网络大模型及智能体 斩获GSMA多项国际权威认证
- 大模型重塑视觉 AI,商汤获Gartner认定为全球前沿技术创新者
- 国内首家!浩鲸科技鲸智大模型Token运营平台获信通院双认证
- 天数智芯全栈算力底座Day0适配GLM-5.2 自主创新架构铸就国内大模型长程推理新标杆
- 越疆将发布下一代陪伴交互AI人形机器人,以自研大模型重新定义家庭具身智能
- 联想ThinkPad P14s/P16s AI 2026移动AI工作站发售,轻松驾驭大模型和专业创作
- 科技照进现实 鸿蒙原生首个3D大模型AI应用V2Fun正式发布
- 大模型驱动算力需求扩容 寒武纪产品落地多行业
- 斑马智能董事长张建锋:全模态端侧大模型将实现座舱主动智能
- 云知声发布 U2:为执行而生的原生智能体大模型,可自主拆解并完成 100+ 步复杂真实工作流
- 中科闻歌重磅发布通用决策大模型Decitron决策机,内测邀请开启
- 端侧AI构筑“新丝路”:面壁智能大模型开源与端侧推理框架的出海实践
- 告别“数据枯竭”,迈向“价值坐标”——艺恩发布《全球大模型数据市场白皮书》
- 星辰大模型能力升级 天翼智铃推出30秒长视频动画制作
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


