OpenAI宣布与AMD、英伟达、英特尔、微软及博通达成超级合作,合力加速AI发展
2026-05-07 07:54:28AI云资讯3744

(AI云资讯消息)OpenAI最新公布了一项超算网络合作计划,旨在加速大规模AI训练。为此,AMD、博通、英特尔、微软和英伟达正与OpenAI联手开发一种名为MRC(多路径可靠连接)的新协议,目标是提升大型训练集群中GPU的网络性能与韧性。
OpenAI 今日已通过开放计算项目(OCP)发布 MRC,以推动该协议在 AI 企业间更广泛地应用。
催生 MRC 需求的问题在于大规模 AI 模型训练时的数据传输。据称,即使只有一次数据传输延迟,也可能打乱整个过程,导致 GPU 闲置。造成这种延迟的主要原因与网络拥塞、链路及设备故障有关。集群规模越大,这个问题就越容易出现。
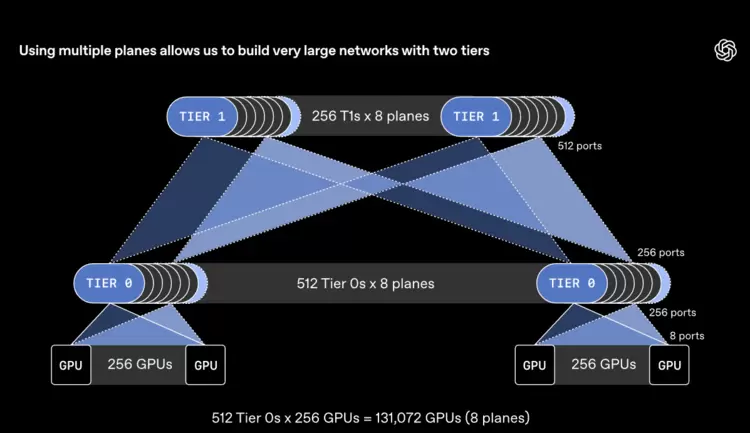
MRC 是面向下一代大规模 AI 超算平台的基础方案。OpenAI 表示,过去两年里,他们与 AMD、博通、英特尔、微软和英伟达合作开发了该协议,并将其内置于最新的 800 Gb/s 网络接口中。这样一来,AI 企业就能将单次传输分散到数百条无中断的路径上,在微秒级内绕开故障重新路由,并采用更简洁的网络控制平面。
MRC 标准将在现有 RoCE(融合以太网)上的 RDMA 技术基础上进行扩展,为 GPU 和 CPU 提供硬件加速的远程直接内存访问能力。OpenAI 已在其搭载英伟达 GB200 Blackwell GPU 的超算集群中部署了 MRC,这些超算用于训练前沿模型,包括位于得克萨斯州阿比林的甲骨文云基础设施(OCI),以及微软的 Fairwater 超算。

相关文章
- 紧随Anthropic之后,OpenAI也提交了IPO申请
- 马斯克在与OpenAI及奥尔特曼的诉讼案中败诉
- OpenAI的Codex已集成到ChatGPT移动应用程序中
- 奥尔特曼称,马斯克离开OpenAI提振了公司的士气
- OpenAI 新模型密集更新,Meta/微美全息强化布局AI核心需求迎爆发增长!
- OpenAI宣布与AMD、英伟达、英特尔、微软及博通达成超级合作,合力加速AI发展
- ChatGPT下载量放缓,或将影响OpenAI的首次公开募股
- 马斯克出庭作证,诉讼指控OpenAI违背了打造惠及全人类的通用人工智能的核心使命
- OpenAI正式发布GPT-5.5模型,编程能力大幅增强
- OpenAI Sora团队负责人比尔·皮布尔斯即将离职
- OpenAI对Codex进行大更新,直接瞄准了Claude Code
- OpenAI疲于应对公众争议、战略调整以及日益激烈的竞争的局面
- OpenAI收购科技播客节目TBPN,进入媒体赛道
- 大英百科全书起诉OpenAI,指控ChatGPT输出的内容与其几乎完全相同
- OpenAI新模型发布,Meta/微美全息以AI芯片+模型布局加速行业创新进程
- OpenAI发布GPT-5.4模型:具备原生计算机使用能力,能够在各类应用中执行任务
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


