AI先行者大会丨思必驰:通向语音落地的“最后一公里”
2020-11-24 10:35:01AI云资讯960
语言,是人类传递信息、交流沟通的最为自然的方式。近几年来,人工智能技术迎来第三次发展浪潮,众多智能语音企业纷纷对外宣称其语音识别率已达到97%。然而,在实际应用中,用户却并不买账。
造成这一现状的原因是什么?国内领先的对话式人工智能公司思必驰,又是如何在技术应用落地中破解这一难题的呢?
本月1日、17日,思必驰高级技术总监、语音应用技术负责人薛少飞,先后出席2020AI先行者大会、首届智能家电语音识别与交互技术高峰论坛,进行了现场分享。

2020 AI先行者大会
“尽管语音识别技术有了极大的发展,但当前,它还没有达到一套技术能够打遍天下的状态,在很多真实应用场景中,仍然有‘最后一公里’的问题需要去解决。”薛少飞在分享演讲中表示,语音识别在多数应用中还是一个强场景化的技术。比如说话人的方言、口音和特定场景的噪声,很可能会造成通用系统识别准确率的急剧下降。
同时,由于识别内容的领域不同,所需要去识别的话术也不一样。例如,在聊到语音识别技术的时候提到远场,可能就是远场识别的远;而在日常生活当中说到原厂,那可能指的就是手机原厂设置。在不同的场景中,专业术语是不一样的。
另外还有不同拾音设备导致的信道差异,现今我们可见到的手机拾音信道、电话通话信道,是比较普遍的信道。但还有一些特别的拾音设备,它们的采样率、音频失真情况等都具有自己的特点,那业界任何一家公司的通用识别效果,都会因此出现明显的下降。而这,也是行业当前普遍面临的痛点。

思必驰高级技术总监、语音应用技术负责人薛少飞
“只有解决这些问题,AI技术才能够真正的落地到业务场景。”薛少飞说,基于此,思必驰推出了识别自训练平台,赋能客户自己做识别系统端到端体验的优化。首先,它可以完全私有化部署在客户场景当中,具有很强隐私性,解决了敏感数据的安全合规问题;其次,它的功能强大,支持数据标注、声学模型自定制、以及包括段落文本、热词、敏感词在内的各级语言模型自定制;此外,它是一体化的方案,能够赋能客户完成分钟级、一键式的自训练。
当前,识别自训练平台处于2.0版本,在即将发布的3.0版本中,还将发布端点检测自训练、标点断句自训练等新功能,并支持增量学习方案等新特性。
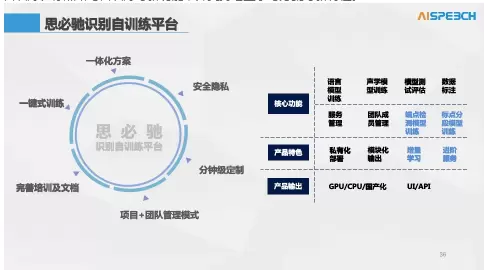
通过思必驰识别自训练平台,客户能够运用自有的行业数据,持续提升在自己行业领域的竞争力;思必驰作为纽带和能力输出方,并不去做客户行业的应用,客户可以没有任何后顾之忧的使用,实现产品持续迭代。
在首届智能家电语音识别与交互技术高峰论坛上,薛少飞重点分享了关于技术趋势的思考。

首届智能家电语音识别与交互技术高峰论坛
薛少飞认为,在家电厂商这端,自训练将赋能家电厂商产品级定制能力,使原有的冗长的交付链路,升级为产品级快速自定制。
而在家的场景中,人机交互体验将实现从“人与单一设备交互”到“人与设备矩阵的交互”的升级。就近唤醒与自然交互,将为家居场景带来更流畅的体验;声音、图像、视频、传感器技术的深度融合,则能够让家居体验更加智慧。结合VR和AR的虚拟家庭管家,也将出现在我们的家中。
相关文章
- 思必驰2025技术进展报告:践行“0-1-N-0”创新范式
- 思必驰自研AI算法突破拾音“禁区”,惊艳世界顶尖学府
- 「思必驰AI办公本·4G畅写版」3月28日发布,高效办公与学习的新选择
- 吸顶麦MC10用实力说话,思必驰助力香港大学经济与管理学院提升教学质量
- 思必驰与上海财经大学达成合作,吸顶麦MC10扩声效果获满分
- 思必驰AI办公本先行接入DeepSeek-R1大模型,简直太强了!
- 删繁就简,思必驰AI办公本数字办公专业之选
- 敏芯股份×思必驰:从Siri史诗级进化,看人工智能的无限应用场景
- 思必驰完成新一轮首期两亿元融资:2023年主营业务收入同比增长50%
- 相约InfoComm China!思必驰携全场景会议数智化解决方案亮相展会
- 思必驰:语音交互迈入“拟人化”阶段
- 7月12日!思必驰“东风生万物”发布会邀您相见!
- 思必驰:从感知智能到认知智能,打造产业级人机智能对话交互能力
- 思必驰“东风生万物”发布会即将开启!
- 思必驰:以数据和软件驱动的智能化,正在成为新的生产力
- 100亿!剑桥海归的苏州独角兽思必驰上市在即
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力
- 昇腾原生支持,科学多模态大模型Intern-S1-Pro正式发布并开源
- 百度千帆深度研究Agent登顶权威评测榜单DeepResearch Bench
- 在MoltBot/ClawdBot,火山方舟模型服务助力开发者畅享模型自由


