AI助手查余额,思必驰语音识别支持10多种方言
2021-07-16 14:36:35AI云资讯2157
不论是“勒是雾都”的重庆,还是遍地“靓女靓仔”的广东,“吴侬软语”的江浙,方言都是各地极具特色文化名片。一方面,方言附着极大的亲切感,另一方面,方言也承载着各地强烈的情感认同与文化价值。
科技发展中的语言交流,不能遮蔽地方性的文化和知识。
考虑方言识别存在文化保护的更高立意,同时也在将老年、弱势群体并入科技生活。思必驰放大全链路语音系统应用在方言的识别、理解、合成上,在家居、银行大厅等应用场景落地,形成了能听懂“方言”的医疗陪伴音箱、智能客服机器人等多样化的产品,可识别粤语、四川话等多种方言。
语音识别的“软肋”-口音、方言
语音识别好比机器的“听觉系统”,让机器通过识别、理解,将语音信号转变为可理解的文本。汉语语音识别的研究起始于70年代,经历四十余年发展,得益于技术的演进和海量数据的积累,一般场景下普通话识别都能达到较好的识别效果。但“口音、方言”仍是全球诸多人机交互公司共同面对的挑战。
为了探究方言、口音对语音识别系统的影响,2018 年华盛顿邮报,Globalme 、Pulse Labs (语音研究公司)合作,对市场主流智能音箱进行测试,事实证明智能音箱不能对方言“通吃”。

方言识别究竟难在哪?
多音多义,使用情境各不同。以中文为例,不仅是在文字使用习惯上(例如,“老后悔了”),读音上也存在差异性(“插”读“擦”,“胡”读“福”)。标准普通话由21个声母和39个韵母组成,上海方言中却包含34个声母和54个韵母,不同方言就是不同数量的声韵母组合。同时,语音识别是一个强场景关联的技术,不同使用情境,方言识别效果存有差异。针对性的声学模型+语言模型训练是一个长期的过程。

需要丰富的语料用以训练。可以理解为机器的“词汇量”,思必驰基于多年语音交互领域的研究,积累了大量基于场景化的数据,铢积寸累地汲取方言语料,不断更新、完善语音数据资源库的建设。
需要持续地研究文化、语素、音素,专业人士、方言专家的参与,会让方言识别效果事半功倍。
低资源环境,如何保证识别准确率?
面对低资源环境,如何提升语音识别准确率?思必驰研发了多种跨语言预训练、联合学习、迁移学习的技术,使用较少的数据,来实现方言识别效果的提升。
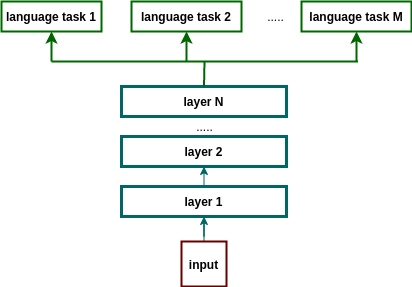
跨语言预训练模型
跨语言预训练,简言之,就是利用大量的有监督或无监督文本,例如用普通话来作为它的基底得到通用的预训练模型,在此基础上叠加少量的方言数据进行模型训练。伴随后期积累起来的方言、垂直场景数据。“炼丹炉”就可以不断提高模型性能表现,从而提升识别率。
多语言联合学习,例如考虑到贵州、四川地理位置上的接近性,因而语言近似性较高。在方言数据样本低资源下,思必驰将近似性语言进行联合学习,从而降低模型的识别难度。
自研的小样本迁移学习技术,用较少的数据量,可以快速实现场景体验优化。例如使用少量带标注的文本数据,即可对标点断句进行优化,相对传统模式调优,节省了83%的数据量。
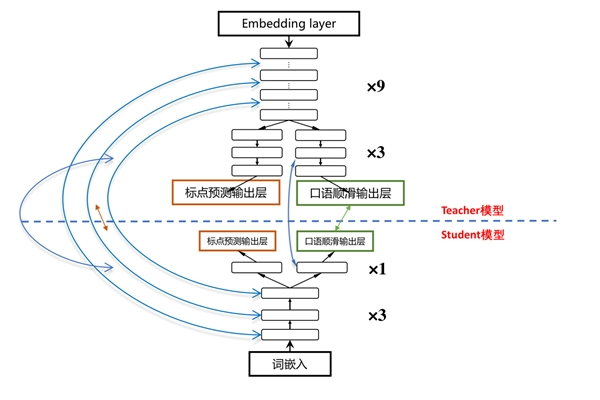
使用联合学习和迁移学习的识别后处理技术
在实际应用中,满足大规模快速自定制的模型,是企业方的切实需求,一是低门槛快速定制,二是能拥有足够的自主权。思必驰方言识别技术,同时具备快速高效的场景化定制能力。通过数据的快速收集和场景模拟,结合自主研发的识别模型自训练系统,短时间内显著提升方言识别模型在应用领域的效果,满足业务需求。
对于有多语言混合需求的集成商,思必驰运用多混合识别模型,在完成识别特定方言的同时,还可识别普通话,最多支持十多种方言的识别。例如,中川混读模型可以同时识别四川话和普通话。
目前,思必驰提供基于云+端混合引擎的连续语音识别,支持四川话、粤语、上海话、闽南语、陕西话、山东话等十几种方言识别。
轻松识别方言,让交互更有温度
探索人机交互的自然、流畅发展,语言的交流一定要足够人性化。
重庆农商行客服机器人刷屏朋友圈,TA能听懂四川话,顺畅完成余额查询、转账等操作,面对说惯了四川话的老一辈人们,这个功能太友好。

基于广泛的生活场景,思必驰与合作伙伴一起将人性化交互的主动权交给用户,聆听更多“新声”。
在家里,美的空调/热水器烤箱等产品均支持多种方言(粤语,四川话,山东话,上海话)识别,方言转普通话等模式,各色乡音无缝交流。思必驰智能医疗音箱亦能听懂方言、重口音普通话,充当家庭医生安心相伴。
汽车里,支持四川话的语音识别服务,导航都略带一丝“麻辣味”。某城市地铁站内,自助售票机支持普通话/中英混合/英语/粤川沪等多语种及方言的识别,准确识别“
相关文章
- 思必驰2025技术进展报告:践行“0-1-N-0”创新范式
- 思必驰自研AI算法突破拾音“禁区”,惊艳世界顶尖学府
- 「思必驰AI办公本·4G畅写版」3月28日发布,高效办公与学习的新选择
- 吸顶麦MC10用实力说话,思必驰助力香港大学经济与管理学院提升教学质量
- 思必驰与上海财经大学达成合作,吸顶麦MC10扩声效果获满分
- 思必驰AI办公本先行接入DeepSeek-R1大模型,简直太强了!
- 删繁就简,思必驰AI办公本数字办公专业之选
- 敏芯股份×思必驰:从Siri史诗级进化,看人工智能的无限应用场景
- 思必驰完成新一轮首期两亿元融资:2023年主营业务收入同比增长50%
- 相约InfoComm China!思必驰携全场景会议数智化解决方案亮相展会
- 思必驰:语音交互迈入“拟人化”阶段
- 7月12日!思必驰“东风生万物”发布会邀您相见!
- 思必驰:从感知智能到认知智能,打造产业级人机智能对话交互能力
- 思必驰“东风生万物”发布会即将开启!
- 思必驰:以数据和软件驱动的智能化,正在成为新的生产力
- 100亿!剑桥海归的苏州独角兽思必驰上市在即








