支撑ChatGPT的超强算力,到底需要什么样的数据中心?
2023-02-26 10:27:56AI云资讯1406
2022年11月30日,OpenAI发布ChatGPT智能聊天程序。ChatGPT能够学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动,真正像人类一样来聊天交流,甚至能完成撰写邮件、视频脚本、文案、翻译、代码、写论文等等。截至2023年2月,ChatGPT已经在全球范围内狂揽1亿名用户,成为当下最火爆的头条热点。欧美各大高校甚至明确提出禁止学生使用ChatGPT做作业,足见其智能化程度,是前所未有的。
1、千亿参数超大模型成为常态,高性能网络成为核心诉求
ChatGPT为什么能有如此强大的功能,因为它的背后是一个拥有千亿参数的巨型神经网络模型。作为对比,我们人脑也只有120-140亿神经元。其实,超大模型在这几年已经成为了趋势,从2018年至今,每过一年,模型参数就增大一个数量级。OpenAI的下一代GPT-4将会突破万亿参数,有传闻甚至达到100万亿参数。

那么如此巨大的AI模型,是如何训练出来的呢?首先,一个大规模的GPU集群是必不可少的。以GPT-3模型1750亿参数为例,每个参数在训练时需要存储16bit低精度用于前向传播计算,和32bit高精度用于梯度更新计算。除此之外,当使用Adam优化器进行参数优化时,还需要存储16bit的梯度,32bit的动量和32bit方差。这样可以算出,1750亿参数的模型总共对存储空间的需求是2.8TB。NVIDIA最新的H100 GPU单卡显存是80GB,也就是说,至少需要35块H100 GPU才能放下一个模型。在实际训练中,还需要进行数据并行,即用不同GPU存储相同的模型,但训练不同的数据集,以此提高训练效率和收敛性。因此,要训练GPT-3这种级别的大模型,需要几万个V100 GPU构建成一个集群才能做到,训练费用高达460万美金一次。
大规模集群有一个性能指标叫做加速比,它的定义是一个拥有N个GPU的集群,其算力和单个GPU算力N倍的比值,理想情况下这两者是相等的。但集群训练会引入额外的通信开销,从而导致N个GPU算力达不到单个GPU算力的N倍。因此,高性能的网络互联,是大规模GPU集群所必须的。
2、链路负载均衡与故障快速恢复成为主要诉求
分布式训练需要多台主机之间同步参数、梯度、以及中间变量。对于大模型而言,单次的参数同步量一般都在百MB~GB的量级,因此需求网络高带宽。现在,25Gbps带宽的网络已经成为数据中心内的主流,40Gbps, 100Gbps甚至200Gbps的网络都开始逐步使用,那是不是直接用大带宽网络就能提升GPU集群的性能呢?其实并不尽然,研究表明40Gbps和100Gbps的网络根本无法充分利用其带宽,原因是网络协议栈的开销影响了传输性能。因此,大模型对网络的第一个要求就是能够充分利用现在以太网的大带宽。
大模型训练一般会将数据并行、流水线并行、张量并行等多种并行模式混合使用,以充分利用集群的算力。无论是哪种并行模式,多机之间都会涉及一种叫AllReduce的集合通信。一个AllReduce任务包含多个点对点的通信,而AllReduce的完成需要所有点对点通信都成功完成,因此集合通信存在“木桶效应”,即AllReduce的完成时间,由其中最慢的点对点通信时间决定。

正因为如此,大模型训练对网络提出了另外两个要求:
一是链路负载均衡要做到完美。因为“木桶效应”,只要有一条链路出现负载不均导致网络拥塞,成为了木桶的短板,那么即使其它链路都畅通无阻,集合通信时间仍然会大幅增加,从而影响训练效率。当前的负载均衡技术基于哈希随机,只能做到流比较多时的一个近似均衡散列,并不能保证所有链路都完美均衡开。因此,寻找一种完美的负载均衡技术,是提升机器学习大模型训练效率的关键。
二是网络出现故障能快速恢复。随着集群规模增大,链路故障在所难免。类似的,一条链路故障就会导致整个AllReduce通信停滞,进而使模型训练停滞。如何做到故障后快速恢复,最好是上层训练业务不感知,是保障一个AI大规模集群性能的关键。
3、RDMA智能无损,大幅提升带宽吞吐
传统TCP网络因为主机侧协议栈开销大,无法充分利用网络带宽。RDMA通信技术通过网卡硬件实现通信控制,绕过了主机侧协议栈,因此既避免了协议栈内存拷贝,又节约了CPU的开销。使RDMA通信相比TCP,具有更低时延和更高吞吐的特点,非常适合大模型GPU训练的场景。
但是,RDMA是无损协议,需要链路层PFC来保障不丢包。PFC在大规模集群可能会出现队头阻塞、拥塞扩散,甚至网络死锁等危害,因此直接大规模部署RDMA存在很高的风险。华为智能无损RDMA,在标准RDMA over Ethernet(ROCE)的基础上,通过PFC防死锁技术解决了死锁问题;通过基于AI的自适应拥塞控制技术,解决头阻问题的同时保证了网络的有效吞吐。
基于无损以太的数据中心网络已经可以支持RDMA应用的规模部署,并且已经在互联网、教育、科研、气象、金融、油气等领域得到了广泛的应用。这些技术在大规模GPU集群中,也拥有极高的价值。

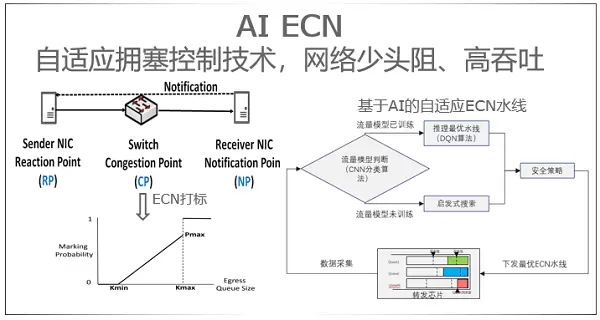
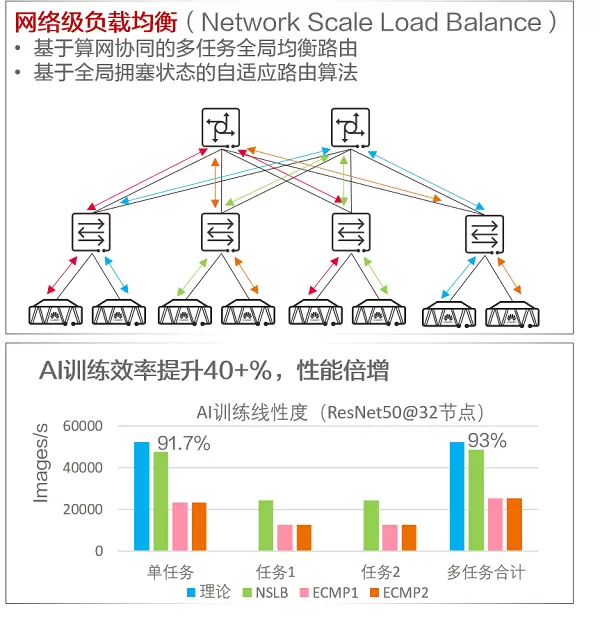
4、NSLB全网负载均衡,实现90%超高吞吐
现有的网络负载均衡技术绝大多数只是解决了本地等价路径之间的均衡,但对于整个网络而言,局部均衡并不意味着全局均衡。更何况,对于ECMP这种依赖哈希随机性的负载均衡技术,在网络流量比较少时,对于本地路径的完美均衡都难以做到。就像抛10000次硬币,正反面各出现一半很正常;但抛4次硬币,就有63%几率不是2正面2反面。AI训练是一种吞吐敏感型业务,其典型流量特征是流数少、单流带宽大、强同步,在这种场景下,ECMP技术因为可能出现的哈希不均匀,难以保证网络负载均衡。
针对这个问题,华为提出了网络级负载均衡(Network Scale Load Balance, NSLB)的概念。华为基于算网协同实现多任务全局均衡路由,基于全局拥塞状态的自适应路由算法,实现AI训练流量满吞吐和网络带宽的完全利用。类似于拥有多条跑道的超大型机场的智慧调度系统,多条跑道同时起飞降落时,也不会互相冲撞,同时也满足最大游客吞吐量。基于NSLB,AI训练效率都可以大幅提升,如下图的测试结果,单任务、多任务线性度均达到90%以上。
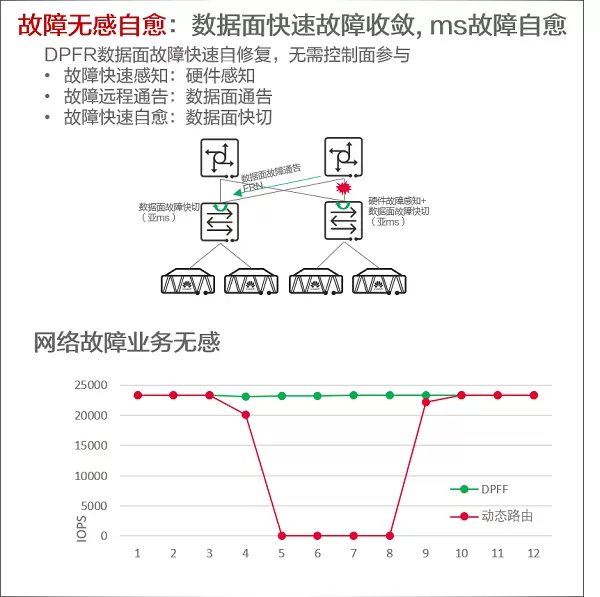
5、DPFR数据面故障快速自愈,使业务对故障0感知
传统网络的故障收敛依赖设备控制面或者集中的控制器的动态路由收敛,网络故障收敛时间数百ms到数s,网络故障尽管是可以恢复的,但是故障期间大量丢包,会导致RDMA连接中断,直接影响AI训练业务的稳定性和性能。下图的红线测试结果,我们看到由于链路故障,导致长达数秒的业务性能跌零。
针对这个问题,华为提出了一种基于数据面的故障无感自愈的方案,我们称为数据面故障快速自愈(Data Plan Fast Recovery, DPFR),故障的感知、通告和自愈完全在数据面实现,不需要控制面参与,基于这种技术网络故障收敛,网络故障基本可以做到业务无感。下图的绿线就是开启DPFR之后的业务表现,在发生故障后数据面自动恢复,使得上层应用无感知。这项技术可以有效消除网络故障对大规模AI训练的影响。
这就好比在一个部门里面,上级一开始就和下级以及周边部门协商好了任务处理模式,当有任务触发时,下级部门直接就和周边部门协同处理来提高工作效率,不用像传统模式一层层协商汇报后再等上级部门下达命名再处理任务。华为做的就是开发出了这个“下级部门”的处理能力,不再单纯只做执行者。
6、应势而起,领势而上
在机器学习大模型火热的今天,如何有效训练这些大模型成为各大企业关注的焦点。华为超融合数据中心网络中的智能无损RDMA技术,网络级负载均衡的NSLB技术和数据面故障快速自愈的DPFR技术,给大规模GPU集群带来了高质量的网络底座,助力超大模型的高效训练。
MWC 2023世界移动通信大会将于2月27日在西班牙巴塞罗那会展中心拉开帷幕,邀您相约在1号馆Intelligent Data Center展岛。华为将全新升级Easy CloudFabric数据中心网络解决方案,助力各行业迈入多元算力新时代。
相关文章
- OpenAI推出GPT-5.6,并宣布推出AI智能体ChatGPT Work
- OpenAI推出首款自研AI推理芯片Jalapeño,专为处理 ChatGPT 请求的服务器设计
- OpenAI的Codex已集成到ChatGPT移动应用程序中
- ChatGPT下载量放缓,或将影响OpenAI的首次公开募股
- 苹果CarPlay已支持ChatGPT,打开了仪表盘上与AI聊天机器人对话的大门
- 大英百科全书起诉OpenAI,指控ChatGPT输出的内容与其几乎完全相同
- OpenAI开始向ChatGPT的低成本用户推送广告
- OpenAI试水ChatGPT广告业务,每千次曝光量收费60美元
- ChatGPT利用年龄预测技术限制未成年人所浏览的内容
- OpenAI推出ChatGPT Health,鼓励用户关联个人医疗记录
- OpenAI在进行测试ChatGPT广告,暂时不会在聊天中出现
- ChatGPT和Copilot被移除出WhatsApp平台
- ChatGPT Atlas新增垂直标签页,对标Arc浏览器
- OpenAI在ChatGPT中推出群聊功能
- OpenAI正式发布GPT-5.1,ChatGPT可提供8种对话模式
- OpenAI推出新款AI网页浏览器ChatGPT Atlas
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


