马上消费知识产权搭建专利授权的桥梁——教会发明人撰写AI专利交底书
2023-05-04 16:07:08AI云资讯696
人工智能(AI)领域的专利容易存在保护客体的问题,马上消费金融股份有限公司深耕AI领域多年,申请了近千件相关的专利。通过大量案例的实践研究,总结出一套企业IPR与发明人沟通的方法论,详细介绍如下:
技术交底书作为发明人与企业IPR及专利代理师沟通的桥梁,其质量不仅影响沟通效率,更是撰写一份优质专利申请文件的基础,直接影响专利申请的授权率,甚至会影响专利的稳定性、维权及许可的价值。
AI领域的技术方案通常涉及算法,对于一名AI方向的企业IPR,你已熟知专利法、及专利审查指南中对涉及“算法特征的专利申请的审查规定”,了解到只有“权利要求包含技术特征、记载了对要解决的技术问题采用了利用自然规律的技术手段、并且由此获得符合自然规律的技术效果”的专利申请才有可能获得授权。然而,“技术特征,技术问题、技术手段、技术效果、自然规律”这些术语,如果直接给到发明人,估计大部分发明人都晕菜了。
那么,如何将这些专业术语转化为发明人能听懂的语言,教会发明人写一份合格的AI技术交底书呢?由于目前在中国的相关法规中,没有非常明确的关于“技术”、“自然规律”等概念的定义,需要通过典型审查案例的研究和总结,来给发明人撰写技术交底书指明方向。
1.技术领域:技术应用的具体技术领域,建议与技术实际应用的至少一个应用场景结合阐述。若为前瞻性的预研类技术,建议与可能应用到的至少一个应用场景结合阐述。
示例如下:信息检索和推荐……
2.技术问题:结合上述场景,先阐述现有的算法、模型在实际应用中或预研过程中存在的问题,进而从技术的角度推导出本方案能解决什么问题。
示例如下:将GAN应用于信息检索,为了解决IGRAN的问题,CFGAN以Vector-Wise Training的方式进行训练:对于每个用户,以他的历史交互序列Vector作为模型输入。但这一做法的问题在于Vector的粒度过大,仅仅依靠GAN的损失函数并不足以充分训练生成器,这样将会导致GAN不能完全捕获文本信息,导致训练GAN的预测能力较低。本方案通过添加G重构后Vector的生成损失(Reconstruction Loss)来辅助训练……。
3.技术手段:对于上述的问题,阐述具体的解决方案。包括不限于:算法应与具体技术领域(应用场景)紧密结合阐述,紧密结合指的是至少算法的输入、输出数据应在该具体技术领域中有技术含义。涉及到公式,写明公式中各参数的技术含义。若算法的输入、输出数据是没有技术含义的数据,如仅为“样本”、“训练数据”等,专利代理师在撰写申请文件时亦无法知晓算法中各数据的含义,则专利申请存在较大的驳回风险。
示例如下:(基于篇幅问题,仅示出部分内容以做克服客体问题示例说明,不是发明的全部内容,亦不涉及创造性问题)
DPGAN的整体架构及流程:如下图所示,DPGAN模型包含生成模型G和判别模型D两个部分。其中,G采用DeepFM模型,D采用BPR模型,目的是在历史数据中获得更多的有效信息,更好的完成商品或者信息的推荐。【tips:与具体应用场景结合】
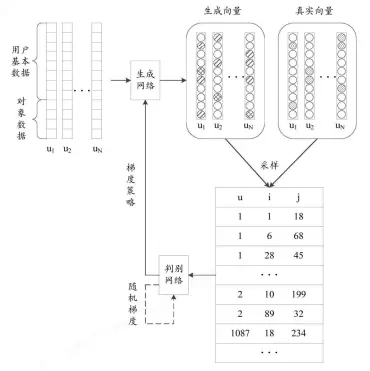
【tips:附图可以更直观的帮助理解技术方案】
在数据方面,使用用户基本数据和对象数据,用户基本数据包含……等结构化数据及隐式信息,对象数据包含……等。推荐过程方面,输入某一用户数据信息,G生成该用户的偏好序列,即图中的生成向量;把生成向量和真实向量组成三元组的形式,即<u, i, j>;采样结果作为D的输入,D估计一个样本来自于训练数据的概率,如果样本来自于真实的训练数据,D 输出大概率,否则,D 输出小概率;其中,采样方式为:正例为用户和物品真实交互的数据;负例为G生成序列,且数量上是正例的2倍,一半取自物品热度靠前的,一半取自物品热度靠后的;目的是为了使数据更加贴合用户的真实情况,使采样样本更能精确表示用户的偏好。【tps:算法的输入、输出数据有具体的含义】
生成模型G:
DeepFM算法有效的结合了因子分解机与神经网络在特征学习中的优点,联合训练FM模型和DNN模型,同时学习低阶特征组合和高阶特征组合。其中,FM算法负责对一阶特征以及由一阶特征两两组合而成的二阶特征进行特征的提取;DNN算法负责对由输入的一阶特征进行全连接等操作形成的高阶特征进行特征的提取。结合深度和广度的特征提取方式,可以更好的获取用户的偏好信息。DeepFM的输入为用户基本数据和对象数据,使用softmax作为输出层,输出的概率值代表用户对物品的喜爱程度:【tips:算法的输入、输出数据有具体的含义】
Pαiu=exprαu,iiNexprαu,i
其中,rαu,i代表用户u对物品i的喜爱程度。生成模型G得到的用户偏好序列与真实序列的近似程度,决定着生成模型G性能的优劣。【tips:公式中各参数有具体的技术含义】
由此可得生成模型G的目标函数为:
LG=-Ei~PT, j~PGlog1-Dβi,j|u+γαα2
其中,γα是G的正则化系数,PT是真实数据的序列,PG是G的生成序列。
判别模型D:
使用BPR作为判别模型,用于区分真实数据和生成数据。在BPR算法中,把用户u对应的物品进行标记,如果用户u在同时有物品i和j的时候点击了i,那么就得到了一个三元组<u,i,j>,它表示对用户u来说,i的排序要比j靠前。依据贝叶斯最大后验概率估算BPR模型参数∅为:
P∅>u∝P>u∅P∅
假设<u,i,j>数据对之间彼此独立,则上式可变形为:
lnP∅>u=<u,i,j>∈DslnPi>uj∅+γ∅2
其中,γ是正则化参数,>u表示排序序列,i>uj表示与j相比用户更偏爱i,Ds是采样获得的数据集。
对判别模型D,可表示为:
Dβi,ju=exprβu,i-rβu,j1+exprβu,i-rβu,j
其中,rβu,i=vuTvi+bi代表用户u对物品i的喜爱程度,Dβi,ju表示与j相比用户更偏爱i的概率,vu和vi分别是用户和物品的隐向量,bi是物品的偏置表示。
由此可得生成模型G的目标函数为:
LD=-Ei~PTlogDβiu+Ej~PGlogDβju+γββ2
=-Ei~PT, j~PGlogεvuTvi-vj+bi-bj+γββ2
其中,γβ是D的正则化系数。
生成模型G训练、优化:
……
判别模型D训练、优化:
……
4.技术效果:从技术角度推导出的效果,即技术手段和技术效果之间是强关联的,需结合技术手段阐述技术效果的产生原因。技术效果若有实验数据证明,效果更直观,如本方案的模型与现有模型的结果对比数据。若效果和技术手段是孤立的,或者仅为数学意义上、用户体验上的效果,则不能被认定为本方案的技术效果。
示例如下:
如前所述,GAN网络具有许多优势,但是,GAN网络也存在着训练过程复杂的问题。其一,训练不稳定问题,容易出现震荡和收敛假象。因为判别模型 D 损失降级会改善生成模型 G 的损失,反之亦然,因此无法根据损失函数的值来判断收敛。其二,模型崩溃问题,GAN的训练过程可能发生崩溃问题,生成模型开始退化,总是生成同样的样本点,无法继续学习。当生成模型崩溃时,判别模型也会对相似的样本点指向相似的方向,训练无法继续。
本方案使用模型预训练来优化GAN网络的训练问题,即分别对生成模型G和判别模型D进行预训练。生成模型G是在DeepFM算法基础上完成的,该算法既可以作为特征提取器,也可以独立使用完成推荐过程,因此可以预训练生成模型G;判别模型D是在BPR算法基础上完成的,依据采样数据对的特点,可采用矩阵分解的方式预训练判别模型D。当生成模型G和判别模型D处于稳定状态时,DPGAN模型再依据对应的优化方式不断迭代持续优化,进一步提升网络的效果,解决了训练困难的问题,进一步提升了模型性能。
本方案基于GAN网络思想的DPGAN网络架构,DPGAN具备更好的特征抓取能力以及更加精确的推荐性能,解决了现有模型并不能完全捕获文本信息,且模型精度较低,以及这些模型忽略了用户的辅助信息以及隐式信息,因而不能更加准确的获取用户的喜好的问题。
综上,若发明人能参考上述建议撰写算法类(AI)的技术交底书,专利代理师撰写出的专利申请文件,通常都能满足客体要求,即“权利要求包含技术特征、记载了对要解决的技术问题采用了利用自然规律的技术手段、并且由此获得符合自然规律的技术效果”。
相关文章
- 两会聚焦严打专利恶意诉讼,擎策·知海FTO综合分析为企业筑牢合规防线
- 狂飙800%!追觅吸尘器凭硬核专利领跑市场,以创新能力定义未来
- Shokz韶音加冕全球“双冠王”:2557件专利,炼成19%的市场份额
- 国内卫浴十大品牌华艺卫浴:800 + 专利加持,技术创新领跑国货卫浴赛道
- Questel报告:百度大模型专利申请量全球第一,智能体、数字人专利申请量国内第一
- 康西爷鲜湿粉保鲜专利技术打破行业困局!10 个月常温锁鲜,筋道免泡更便捷
- 云知声入选上海市高价值专利升级培育项目,以全栈AI实力驱动高价值创新
- 趣链科技入选2025年度浙江省高价值专利培育项目
- 知医邦脉象仪发明专利已获证,明显软件重硬件轻,主打Al+性价比
- 华为“碰一碰”新专利公布:重塑内容分享模式 引领设备交互新范式
- 创新实力再获认可!广东华弘活动地板公司新增“组合拼装”防静电地板专利
- HMO专利母源配方落地,伊利金领冠珍护源初配方奶粉耀世来袭
- 三重守护+专利赋能,伊利金领冠托菲儿系列特医配方奶粉引领行业研发创新
- 拟赴港IPO上市,华曦达以新型散热专利强化产品竞争力与静音体验
- 定制无线耳机发明者——听智慧,以技术创新+118项专利壁垒,引领行业新范式
- 海信发布三款重磅激光显示新品,逐步开放1300余项专利推动三色激光显示技术普及
人工智能企业
更多>>



人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力
- 昇腾原生支持,科学多模态大模型Intern-S1-Pro正式发布并开源
- 百度千帆深度研究Agent登顶权威评测榜单DeepResearch Bench
- 在MoltBot/ClawdBot,火山方舟模型服务助力开发者畅享模型自由


