UCloud优刻得升级推出US3FS 2.0,面向大模型的存储系统改造
2023/08/08 16:40AI云资讯12481
随着2023年ChatGPT的概念不断升温,AI模型的参数规模呈现了指数级增长。云厂商面对的大模型客户也逐渐增多,并对存储系统以及整个IaaS层架构提出了巨大的挑战。
目前大模型的客户在存储系统的选型上可能会有以下几种选择:并行文件系统、基于对象存储的存储系统、NFS等。
首先我们看一下并行文件系统:
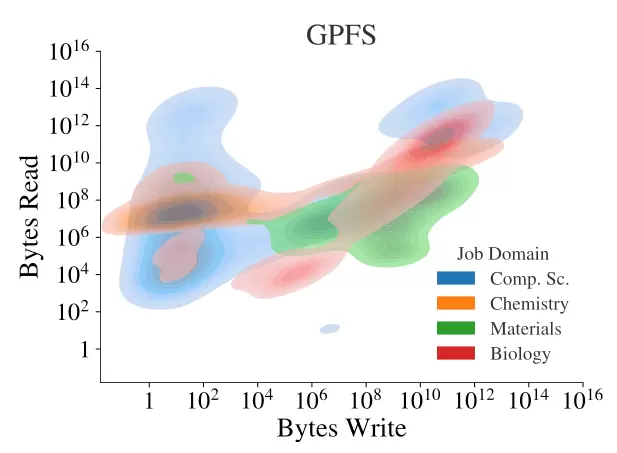
Density distribution plots of I/O activity from ML jobs using GPFS
《Characterizing Machine Learning I/O Workloads on Leadership Scale HPC Systems》中关于ML在GPFS中的IO模型示意图,可以看到在并行文件系统的传统科学计算领域IO模式,读写比例基本平衡且大部分为小IO,这种GPFS适用的IO模式是否能够完全匹配AI大模型下的场景呢?
这里引用Vast Data(https://vastdata.com/blog/five-reasons-why-parallel-file-systems-are-not-silver-bullet-for-ai)的数据,95%的AI Workloads是读密集型的,当然也有例外情况,比如大型语言模型的Checkpoint。并行文件系统在拥有高性能的同时,也引入了高复杂性,包括额外的客户端以及较高难度的维护工作,并行文件系统适用的HPC科学研究场景需要一个对存储系统代码和操作系统有深入了解的团队,这在科研实验室中是相对常见的,但对于商业企业来说,往往缺乏这种人员配置,在目前的大模型场景下,类似于GPFS的并行文件系统并不完全适用。
根据UCloud优刻得云平台上的客户IO模式来看,大模型计算的工作负载大部分场景下是读密集型的,并非大部分文件系统面对的读写比例平衡的场景,短时间的高读吞吐需求较为常见,高吞吐读之前会对文件进行大量列表操作等元数据操作,以及Checkpoint时期会有大量顺序写入,对于历史数据有一定的归档需求。
针对上述场景,目前UCloud优刻得提供全面优化升级的US3FS 2.0来满足大模型客户的存储需求。
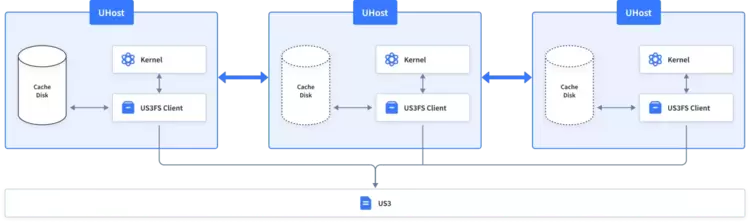
US3FS是基于UCloud优刻得对象存储系统US3的文件系统,支持将对象存储中的Bucket直接以文件的形式挂载至客户端,方便客户业务通过文件的POSIX接口来访问数据,避免客户业务层面做过多的修改适配。面向大模型场景,目前UCloud优刻得对US3FS进行了升级优化,US3FS 2.0 整体架构如下:
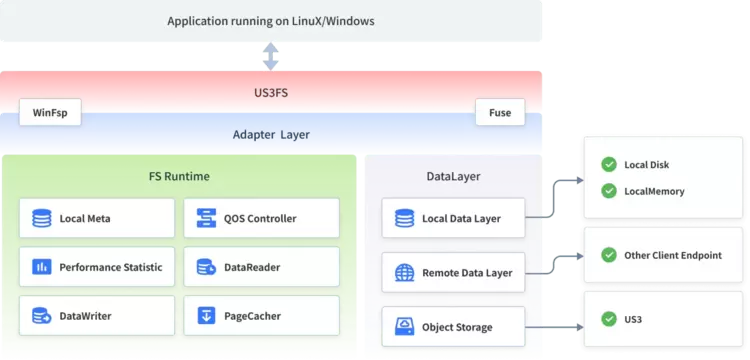
从前述大模型的存储需求来看,后面将从高吞吐读需求,大量列表操作,大量顺序写入这三方面描述UCloud优刻得针对US3FS的优化升级过程。
这里首先考虑高吞吐读之前的大量列表的问题,整体分为两种解决思路:
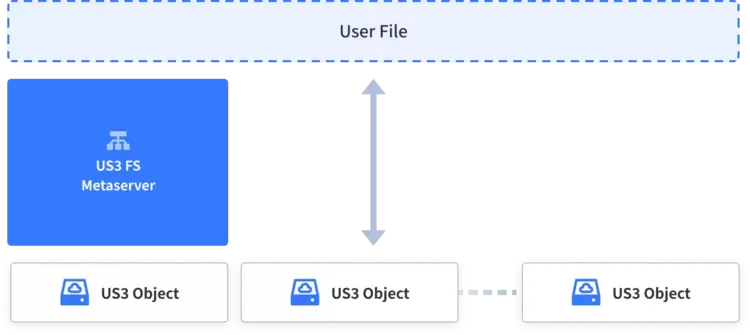
1.打散后端US3的存储结构,旁路一套元数据系统进行元数据的性能优化等维护操作,不利用现有US3的元数据能力。
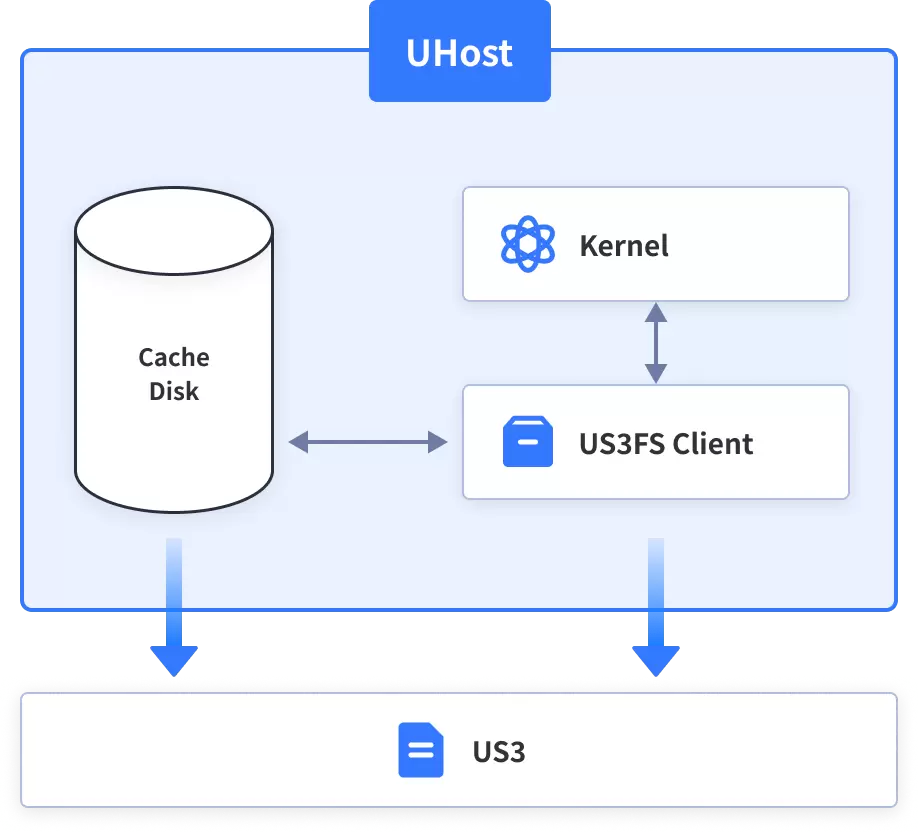
2.不打散后端US3的存储结构,优化升级现有的US3元数据性能,并进行Meta Cache等近计算端优化。
第一种方案理论上可以规避现有架构的历史负担,需要额外的硬件资源来提供元数据服务,改造后能够规避业务层面文件大小等因素对US3在高并发情况下发挥高吞吐能力的限制,也可以优化元数据结构以更贴近文件存储的树状方式,而不是对象存储的KV方式。但此方案整体改动较大,引入的风险也较多,且无法直接利用US3对象存储现有的增值服务,包括但不限于归档、低频等廉价存储的功能。
第二种方案需要对现有关系型数据库的老架构US3元数据进行升级,这里由于US3同时正在进行元数据UKV的升级过程,将US3整体的元数据迁移至KV的方式进行存取,可以直接利用数据,与此同时,还需要对现有的对象存储语义的ListObject进行一定优化来适配文件存储的场景,进而解决对象和文件之间元数据差异的问题。
经过对比,UCloud优刻得选择了第二种方案来实现US3FS2.0的元数据部分,依赖于UKV(UCloud优刻得自研的分布式KV存储系统)的整体存储计算分离的架构,可以支持0数据搬迁的Shard Split,快速进行列表请求计算部分的压力分摊,底层的统一存储层Manul也可以进行存储层面的压力分摊。
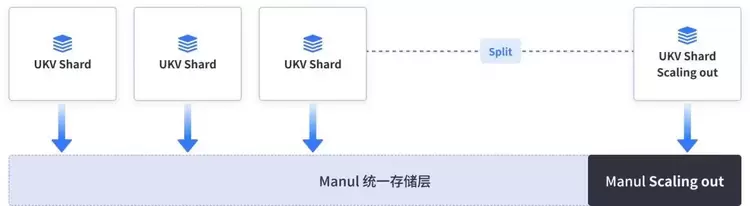
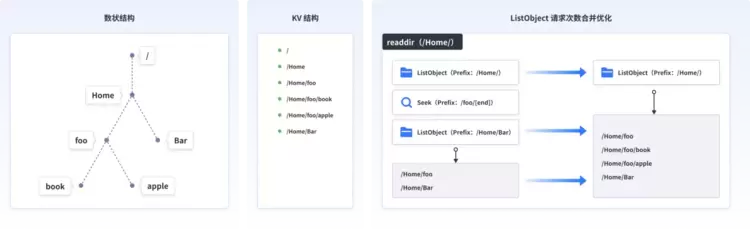
这里UCloud优刻得也会进行近端元数据的Cache,由于对象存储和文件存储存在天然的区别,对象存储的结构近似于KV的方式平铺,文件存储的方式近似于树状结构,客户在文件层面的readdir操作在极端情况下会导致底层KV层的大量seek操作效率不高,这里我们优化成直接进行平铺的ListObject操作并在近端进行整体的元数据重构以及Cache,保证客户的元数据检索效率,以在UCloud优刻得云平台实际上线的某客户为例,30PiB的数据元数据异步Cache的整体时间可控制在10分钟到20分钟级别。
其次,UCloud优刻得还综合考虑了客户高并发读吞吐的需求,这里面向客户的业务实际场景,大模型通常是GiB级别的文件高并发的重复读取,UCloud优刻得并不希望这些重复的读取消耗后端对象存储的带宽。
UCloud优刻得在US3FS的挂载端通过本地NVMe来提供近计算端的分布式缓存,这里的缓存会利用计算节点间的东西向带宽,一般建议实际操作时,在计算网和存储网做网络层面的隔离,防止和计算部分的流量有干扰,UCloud优刻得也提供独立专有化部署的一整套解决方案。
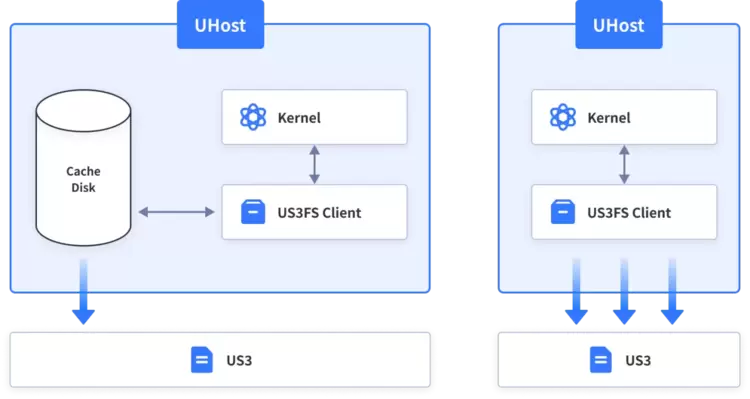
后续UCloud优刻得还会提供通过US3FS的管理节点US3FS Master来支持业务层主动提前Load指定的数据至缓存中的功能,但这需要将业务层和存储层做一些深度的结合才能实现。
在未进行预Cache时,上层应用从US3FS挂载点读取数据时,Kernel会将上层的读缓冲区拆分成固定大小传递给US3FS, 当US3FS接收到这些读请求时,会根据读的偏移,传入的缓冲区的大小以及设置的预读大小来确定实际要读的Range。默认情况下,US3FS以1MiB一个CachePage的形式组织文件的缓存区,通过读Range可以确定涉及的Pages,接着根据Page的状态(Ready, Missing or Infight), 如Pages全为Ready,则可直接向上返回,如存在Missing或者Inflight的Pages,则Missing的Pages需要向数据层发送GET_RANGE请求,Inflight的Pages需要等待对应的GET_RANGE执行完成,这里一定程度的耦合了大模型下客户顺序读的IO模型,通过参数能够最大优化在这种场景下的读取并发吞吐。
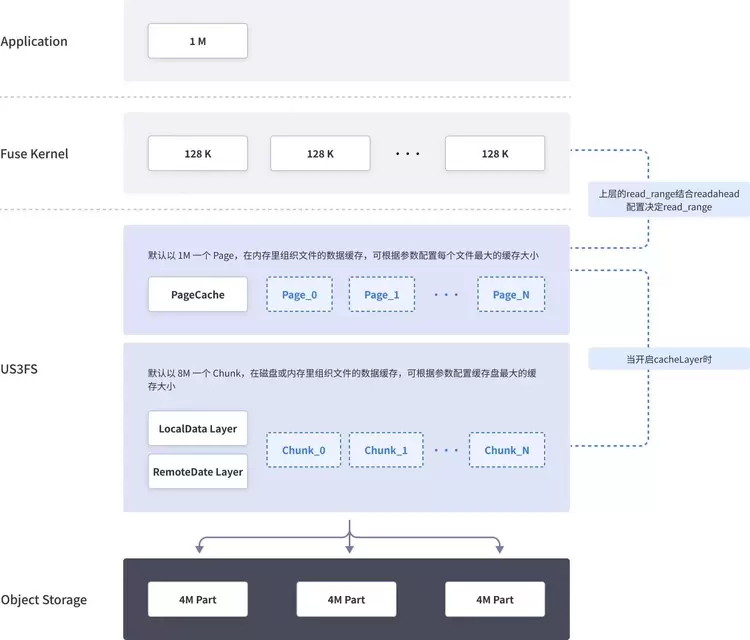
接下来还需要对业务Checkpoint场景进行优化。由于业务的特殊性,写入Checkpoint期间计算训练是暂停的,写入速度的快慢就直接影响了客户整体的效率,又由于此时是大量顺序写,对存储系统的性能需求就明确为写吞吐。
这里也有两种解决思路:
3.写缓存,异步的上传到后端对象存储,保证当时写入的速度是近似于本地盘的速度。
4.提高并发,直接写至后端对象存储,由于后端整体的吞吐是可以支持平行扩展的,这里瓶颈如果能够打满挂载的网络则是最优的情况,那需要提高的就是写入的并发,降低整体吞吐对于写延迟的依赖。
综上UCloud优刻得选择了两者结合的方式。纯粹写缓存的方式在数据一致性以及系统复杂度上都有不少的麻烦,且能否解决问题强依赖于不可控的计算节点的缓存盘,而不是依赖于存储系统自身的环境。UCloud优刻得会在写入时将上层Kernel拆分下载为固定大小的IO进行进一步的合并整合,整合一个4MiB大小的Logic Block,用于后续并发上传至后端US3对象存储。上层的IO到达US3FS之后会直接返回成功,并逐步累积缓存对后端进行并发的分片上传,这里并发的大小以及缓存的度都是支持对参数随时配置修改的。
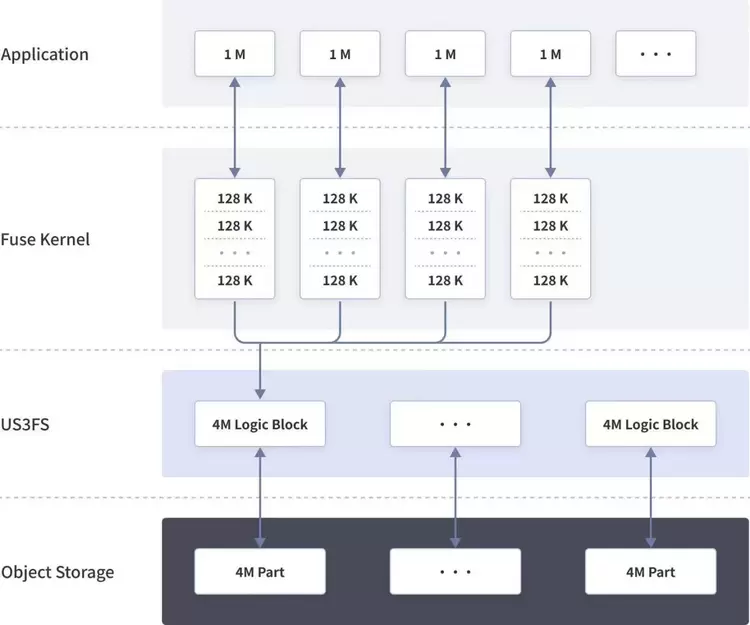
这样上层的串行IO通过US3FS后会变成高并发的分片上传请求到US3后端,进而提升整体的吞吐。

以上为一个实例集群US3FS Runtime的实时Stat功能展示的写吞吐,相较于优化前有50%左右的吞吐提升。
本文描述了面向大模型场景的存储需求,UCloud US3FS2.0 在元数据性能、读缓存、写吞吐三个方面的优化内容。在AI大模型的需求推动下,对整个存储系统以及IaaS计算、网络架构提出了较大的挑战。对于对象存储来说,前端的压力能够释放到后端之后,后续,UCloud优刻得还将在存储容量与性能需求不匹配、读缓存预热等方面持续进行优化。*图片来源由UCloud优刻得提供授权使用
相关文章
- 对象存储能力进阶,UCloudStor统一分布式存储全新版本发布
- 助力合作伙伴打造自主云服务,UCloud优刻得正式推出专属云产品
- 全球工厂集约化管理,海泰新能基于UCloudStack私有云“智造”升级
- 2023中国移动全球合作伙伴大会开幕,UCloud优刻得与中国移动共创产业数智化!
- UCloud优刻得联合中科院自动化所、杭州设维打造“AI智能文案应用平台”
- UCloud优刻得即将亮相2023中国移动全球合作伙伴大会
- UCloud优刻得正式启动2024届校园招聘
- 新网与UCloud优刻得联合发布“新网云”,为中小企业提供优质高效云服务
- UCloud优刻得与新网联合发布「新网云」,为中小企业提供优质高效云服务
- UCloud优刻得模型服务平台UModelVerse全新发布,即刻搭建您的专属AGI应用
- 《中国AIGC产业算力发展报告》发布,UCloud优刻得大模型智算底座加速应用落地
- UCloud优刻得荣获IDCC长三角绿色算力基础设施奖,以智算底座助推大模型产业发展
- 全球性医疗健康公司的大数据平台实践,UCloud优刻得助力晖致在中国探索数据智能
- UCloud优刻得亮相第九届中国行业互联网大会,展示自建数据中心成果和大模型算力底座
- UCloud优刻得升级推出US3FS 2.0,面向大模型的存储系统改造
- 创意大作一键生成,UCloud AIGC图像产品精彩亮相IXDC设计大会
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


