引领大模型推理效率革命!浪潮存储发布国内首款推理加速存储AS3000G7
2025-07-29 15:15:57AI云资讯2160
2025年7月25日,浪潮存储营销总监张业兴出席中国信息通信研究院主办的2025(第二届)产融合作大会。会上,张业兴发表题为《融存智用 运筹新数据 ——浪潮存储金融解决方案和实践》的主题演讲,并代表浪潮存储正式发布国内首款推理加速存储AS3000G7。该产品凭借“以存代算”的技术创新,有效破解KV Cache重复计算带来的算力和时延损耗难题,为大模型推理场景提供突破性解决方案,加速推动大模型在金融、科研等领域的规模化落地。

大模型推理效能瓶颈:吞吐量和时延
当前人工智能大模型的应用已渗透千行百业,既推动着产业效能的跨越式提升,也深刻重构着生产生活的底层逻辑,成为驱动数字经济发展与社会智能化升级的核心力量。随着大模型应用的普及和相关技术的发展,各行各业对大模型应用的关注点逐渐从大模型的训练转到大模型的推理。据IDC数据显示,智能算力规模在未来5年增长1.7倍,用于推理的工作负载将从2023年的40%上升到2027年的70%以上。因此,大模型推理将会成为未来大模型应用的焦点。然而,当前大模型推理仍然需要借助GPU服务器来实现,而GPU服务器,也是整个大模型落地中最昂贵的投资。因此,充分发挥GPU服务器的利用率来提升大模型推理效率是大模型的落地关键,推理效率的高低直接决定着大模型从“实验室”到“生产线”的落地速度。
大模型推理效率面临两大核心瓶颈:吞吐量(Tokens/s)和时延。吞吐量是指系统在单位时间内能处理的tokens的数量,数值越高表明LLM服务资源利用率越高、系统成本越低。时延则是用户接收每个token的平均耗时,其中首字时延(TTFT)是长文本对话场景中 “实时交互体验” 的核心指标,直接影响用户体验。
大模型的推理包含两个阶段,第一个阶段是预填充(Prefilling)阶段。Prefilling阶段处理输入,构建初始上下文并缓存成KVCache(key-value键值对),缓存在GPU的HBM显存里。第二个阶段是解码(Decode)阶段,解码阶段则利用Prefilling阶段生成的KV Cache,迭代地生成输出Token,最终给出推理答案。
根据大数据统计分析,超过 76% 的对话都是多轮的,多轮对话会产生大量的KV Cache,上一轮的对话产生的KV Cache也会作为下一轮推理的输入基础,为连续交互提供上下文支撑。但实际场景中,GPUHBM显存容量存在明显限制,因此多轮对话中的KV Cache会被强制丢弃,在下一轮对话中需要消耗算力来重新计算。以DeepSeek 70B模型为例,其每10分钟产生的KV Cache高达25TB,但每张GPU HBM显存只有几十GB,因此,在服务完一个请求后,需清空显存以接纳新请求,KV Cache被强制丢弃,在后续对话中,原本可复用的KV Cache需要重新计算。这种重复计算直接时延增加(首字响应变慢),同时造成GPU算力空转(重复执行相同计算),导致吞吐量下降,最终导致资源利用率降低。因此,高效管理KV Cache缓存成为提升推理效率的关键。
存储产品托管KV Cache,实现“以存代算”
浪潮存储AS3000G7作为国内首款推理加速存储,可存储所有KV Cache及多轮对话结果。其创新架构通过将KV Cache从GPU写入本机内存,再经高速网络缓存至AS3000G7,下轮对话时按需拉取缓存无需重新计算,彻底实现“以存代算”,显著节省算力消耗并提升资源利用率。

作为国内首款推理加速存储产品,AS3000G7以四大核心优势重塑推理效率:
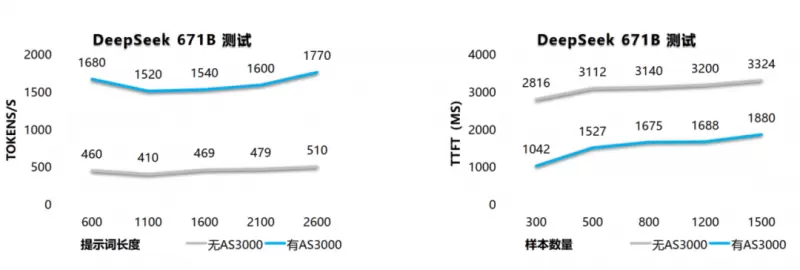
降低响应延迟:将历史Token缓存至AS3000G7存储层,下轮对话从NVMe SSD硬盘中拉取历史token的KV Cache,减少GPU重复计算带来的资源消耗,TTFT降低90%;
承载更多并发:TTFT在400ms以内的前提下,系统可支持的吞吐量(Token/s)可达原方案5倍,单位GPU资源可承载更多推理请求;
降低GPU功耗:TTFT的降低与并发的提升,单Token平均功耗下降60%,在承载同等规模 token 负载时,GPU服务器整机功耗降低。
生态兼容适配:广泛兼容国产与海外芯片的异构算力平台,深度适配vLLM框架下的deepseek等主流大模型,优化推理体验。
在某头部客户联合测试中,采用1台GPU服务器搭配1台AS3000G7推理加速存储的组合方案实现:
稳定支撑500+并发对话,TTFT降低90%,响应速度大幅提升
同硬件配置下吞吐量(Tokens/s)提升5倍,在不增加 GPU 资源的情况下,实现更高并发的推理请求
单token功耗降低70%,单位算力成本降低60%,推理性价比提升
随着大模型推理需求的持续攀升,AS3000G7的推出恰逢其时。其通过 “以存代算” 的技术创新突破 KV Cache 重计算瓶颈,为 AI 规模化应用筑牢存储根基。未来,随着多模态与实时交互场景的普及以及存储与计算的协同优化,KV Cache “以存代算”将成为降本增效的核心竞争力,为智能时代的推理存储构建新基准。
相关文章
- 悬镜安全:穿越周期 在AI浪潮中定义数字供应链安全新范式
- 浪潮计算机亮相通信盛会!以多元智算产品赋能行业发展新未来
- 浪潮下,开目软件与国产工业软件的AI破局之道
- 浪潮 KaiwuDB 亮相 OpenClaw 开发者日,分享Agentic AI 时代数据底座建设思路
- 浪潮开务时序基础模型正式发布
- 数字峰会探新“智”|为AI装上“质检员”,浪潮软件集团发布大模型“体检”方案
- 传音控股出海新篇章:共创共享,融入新兴市场数字化浪潮
- DeepSeek-V4 上线国家超算互联网:以普惠算力与开发者共逐AI新浪潮
- 2026 Q1光通信电源收入同比增166.16%!鼎阳科技拥抱AI+光通信浪潮
- 从全域覆盖到价值深耕,浪潮云海超融合五大行业市占率第一
- Aginode安捷诺:OpenClaw开启的智能体浪潮,如何重塑下一代智算网络?
- 在时代的浪潮中前行:黄宏生与创维的务实之道
- 从Agent 浪潮到组织变革,腾讯云携手业界专家共探OpenClaw时代的安全边界与企业进化
- “十五五”开局之年,国产操作系统在AI浪潮中书写中国方案
- 资源全面利旧,助推云架构再升级,浪潮云海助力长城汽车云平台建设
- 养虾引爆执行式AI浪潮,微盟导购Agent打通零售AI全链路
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


