节点集群带宽突破 513GBps 焱融存储再度登顶MLPerf Storage 全球榜单
2025-08-05 17:49:00AI云资讯2339
2025 年 8 月 4 日,全球权威的 AI 性能基准评测组织 MLCommons® 正式发布最新一轮 MLPerf® Storage v2.0 基准测试结果。来自中国的存储厂商焱融科技在此次测试中表现突出,其全闪存储一体机 F9000X 不仅在全部模型测试中性能领先,更以三节点存储集群 513GB/s 的总带宽刷新 3D-Unet 模型测试的纪录,登顶 MLPerf 全球性能榜单。
MLPerfStorage:AI存储性能的黄金衡量标准
MLCommons 作为全球人工智能工程联盟,始终致力于规范 AI 技术的准确性、安全性、速度与效率评估,推动 AI 系统性能优化,其权威性得到全球业界广泛认可。而 MLPerf Storage Benchmark 作为该联盟专为 AI 场景打造的存储基准测试,通过模拟真实 AI 训练中的 I/O 操作,精准衡量存储系统向 GPU 输送训练数据的速度与能力。
此次发布的 MLPerf Storage v2.0,在 v1.0 基础上进一步升级:除保留 3D-Unet、ResNet50、CosmoFlow 三大训练模型外,新增 Checkpoint 工作负载,更全面覆盖训练中断点恢复、模型存档等实际场景。为确保结果的严谨性与公正性,v2.0 要求每项基准测试必须多次重复执行(训练任务 5 次、Checkpoint 任务 10 次),且全程连续运行无失败,同步提交完整测试日志,最终结果取多次运行的平均值 —— 这一系列严格规范,使其成为业界衡量 AI 存储性能时最具参考价值的权威标准。
焱融全闪刷新全球纪录最小规模集群性能第一
MLPerf Storage 基准测试既支持单个计算节点(客户端)运行多个 ACC(GPU 加速器)的模型测试,也适配分布式训练集群场景 —— 通过多客户端模拟真实数据并行访问存储集群,充分覆盖从单节点到分布式集群的全场景 AI 工作负载。其最关键的衡量标准,是在保证高性能 GPU 利用率(3D-Unet 与 ResNet50 模型下为 90%,CosmoFlow 模型下为 70%)的前提下,存储系统所能实现的聚合带宽。这项指标是衡量存储系统实际能力的核心,直接体现其在 AI 训练过程中是否能够充分“喂饱”计算资源,避免造成 GPU 空闲浪费。
最新测试结果显示,在 3D-Unet、ResNet50 以及 CosmoFlow 所有模型的测试场景下,于通用硬件环境中,针对分布式存储的最小规模集群,即三节点存储集群,焱融全闪 F9000X 在全球知名分布式存储厂商中脱颖而出,集群总带宽等关键指标位列全球第一。尤其是在 3D-Unet 模型测试中,集群带宽达到 513 GB/s ,为迄今已公布结果中的最高值。
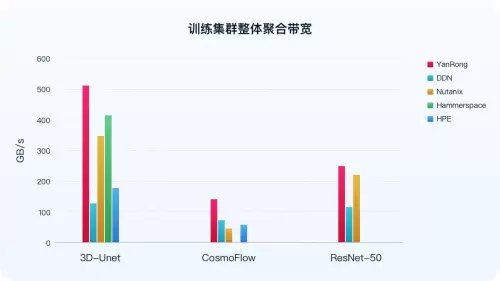
数据来源:MLCommns 官方
除分布式场景外,在单客户端测试中,焱融全闪 F9000X 同样展现出优异性能,进一步验证了其在不同部署规模下的强劲数据处理能力。

此外,在新增的 Checkpoint 工作负载测试中,针对 Llama3-70B 模型场景,通过部署 8 个客户端模拟并发请求、搭配 64 个模拟 GPU 环境,实现 221 GB/s 读取带宽与 79 GB/s 写入带宽的高性能表现。这种稳定且高效的带宽支撑能力,能够精准保障 Checkpoint 文件在模型训练全流程中实现秒级极速读写,从底层存储层面为 AI 训练任务的断点续训连续性与模型训练稳定性筑牢技术根基,助力企业从容应对大规模模型训练的严苛存储需求。
焱融存储MLPerf测试表现背后:技术积淀与生态协同是关键
据了解,焱融存储去年便参与了 MLPerf Storage v1.0 基准测试,并以出色成绩从全球知名存储厂商中强势突围。焱融存储之所以能在 MLPerf 存储基准测试中持续取得优异成绩,核心在于其长期深耕 AI 大模型训练与推理等核心场景的技术积累:一方面,通过长期深耕大模型训练与推理等核心场景,深度理解 AI 工作负载特性;另一方面,从架构设计到软硬件全技术栈,持续推进系统性创新与优化,构建起应对高性能负载的核心能力。
与此同时,焱融也与 NVIDIA、Intel、新华三(H3C)、忆恒创源(Memblaze)、大普微(DapuStor)等上下游生态伙伴展开深度协同,在网络、芯片、服务器、SSD 等关键环节紧密合作,实现软硬件的深度适配与极致优化,有效保障系统在 AI 基础设施全链路中的高效稳定运行。
公开资料显示,焱融全闪存储基于其自研的高性能分布式文件系统 YRCloudFile,通过多项关键技术实现性能突破:
采用自研 Multi-Channel 网络带宽聚合技术,可整合多张 InfiniBand/RoCE 网卡性能,在大 IO 场景下充分释放硬件潜力,支撑超高速数据传输;
系统具备负载感知能力,可根据压力智能切换中断与轮询模式,有效提升 IOPS 性能;
在 IO 模型层面,通过异步非阻塞设计减少上下文切换、增强并行处理能力,并通过处理器核心资源的高效分配,降低线程调度开销,支撑高并发数据处理的同时,充分发挥 NVMe SSD 的性能优势;
针对大规模 GPU 集群易出现的网络拥塞问题,专项优化传输机制,保障数据传输的高效与稳定。
随着大模型向千亿、万亿参数演进,存储作为底层支撑的性能要求持续提升。此次焱融科技在 MLPerf Storage v2.0 中的表现,不仅印证了中国存储厂商的技术实力,也为 AI 基础设施的性能优化提供了可参考的实践路径。业内预计,未来存储系统的高带宽、低延迟能力依然是 AI 大模型广泛落地的关键竞争力之一。
相关文章
- 英伟达首席财务官调侃竞争对手因存储芯片短缺措手不及
- 海康存储推出五盘位NAS新品MAGE50X千元级AI私有云新标杆
- 华龙奖最佳存储卡实力加身,阿根廷国家队联名出圈——雷克沙P&E展台“双喜临门”
- 高端存储迈入AI周期,中科曙光打开数据基础设施新空间
- 媒体观察:词元经济时代,存储该如何做好自己的主角?
- 软硬协同价值升维:aigo存储发布AP10,重塑“友好存储”新标杆
- AI 加持 + 专属存储模式,百奥 PD16LD 让大空间告别潮湿与损耗
- 忆联亮相2026移动云大会,以全场景AI存储方案共筑Token智能新生态
- 暴涨超40%!存储芯片领跑一季度工业增长,超级周期持续发酵
- 绿联携AI NAS参展英特尔峰会,定义智能存储新生态
- 绿联AI NAS亮相英特尔“智存无界·芯联未来“峰会,展现AI存储创新实力
- 媒体观察:让AI走向数据,IBM重写存储“第一性原理”
- 国产品牌的工业设计,到了什么阶段?从 aigo 存储三款红点产品说起
- 海康存储携多款新品亮相2026北京车展 演绎汽车存储新生态
- 从追赶者到“智造”标杆:国内存储厂家金胜电子入选龙华区创新百强
- 简化运维,Dell PowerStore革新Kubernetes容器化存储体验
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力
- 昇腾原生支持,科学多模态大模型Intern-S1-Pro正式发布并开源


