物理世界智能的优化:从文本思考到多模态思考
2026-05-20 17:41:45AI云资讯2327
近日,旷视联合北京人形机器人创新中心研发的空间感知优化算法E-ViC,获得了第 64 届国际计算语言协会年会(ACL 2026)的录用。ACL 是自然语言处理与人工智能领域的顶级学术会议,此次录用标志着我们在物理世界智能方向的研究取得了新的技术突破。
01从文本思考,到多模态思考
人类在面对复杂空间问题时,从不只靠"想",我们会用手指着地图比划,会拿笔在纸上标注关键点,会把视线凑近细节处再下判断。这种"边看边想、边动边确认"的过程,是人类空间认知的核心。然而,目前主流的视觉语言大模型(VLM)在推理时,依赖的仍是纯文字的思维链(Chain-of-Thought,CoT),也即把视觉信息压缩成文字描述,再用语言来推理。这就好比让一个人蒙上眼睛,只凭口头描述来进行物理世界的操作。语言擅长传递语义,却天然损失了几何精度,对于物理世界中绝大部分任务的执行来说,这种"语言盲推"是一个根本性的瓶颈。
E-ViC(Embodied Visual Chain)正是为打破这一瓶颈而生。
E-ViC 的核心思路是:让推理回归视觉本身。它将缩放(zoom in)、标点(draw point)、画框(draw box)、轨迹绘制(draw trajectory)等视觉操作定义为可执行的"决策原语",使模型在推理过程中可以直接与图像像素交互,圈出目标区域、标注关键坐标、绘制运动路径,而不是把这些信息转译成文字再进行纯文本推理。
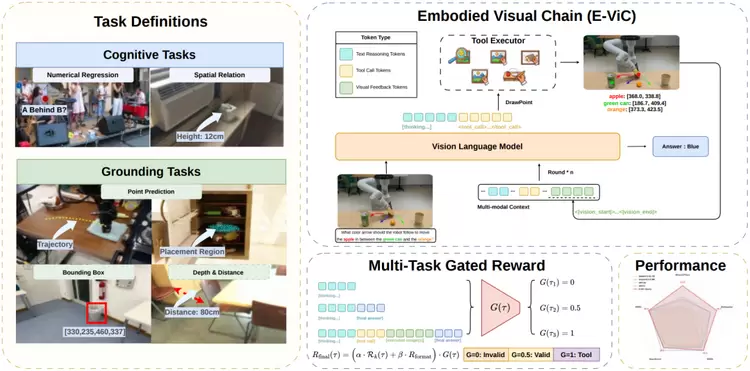
具身视觉链(E-ViC)概览
这种"看一步、想一步、确认一步"的闭环推理,正是人类处理空间问题的自然方式。E-ViC 让机器以类似的方式思考。
更值得关注的是训练方式的创新。E-ViC不依赖人工标注的推理轨迹,而是通过强化学习让模型自主涌现出"主动调用视觉工具验证假设"的策略。模型并非被教导"何时该看哪里",而是在反复试错中,自己学会了什么时候值得放大图像、在哪里标注落点。这种策略的自主涌现,与人类习得空间技能的过程高度相似。在五项空间理解基准测试中,E-ViC相比基座模型平均提升10.1%,并在需要精细定位的任务(如目标放置、空间指代)上取得最大幅度的突破,甚至超越了参数量为其四倍的大模型,以及 GPT-5 等商业旗舰模型。
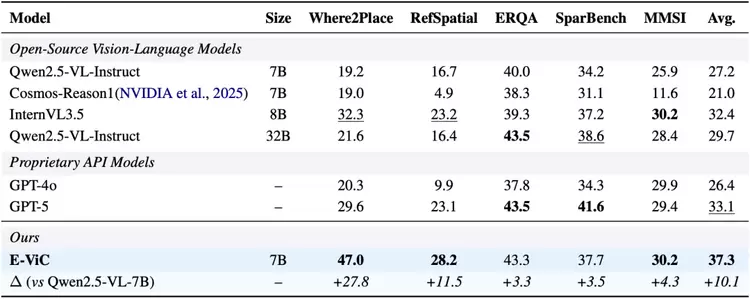
空间理解基准上的性能对比
02物理世界智能这项工作背后,指向一个更宏观的目标:让智能体真正具备在物理世界中自主行动的能力。
物理世界的智能,区别于纯数字世界的智能,在于它必须面对真实空间的复杂性,这要求智能体在四个维度上真正实现自主:
自主感知:主动融合多传感器信号(视觉、听觉等),自主调用感知工具调整观察内容(如翻转视角、局部放大),并在多模态信号之间实现协同理解;
自主记忆:在多轮交互中保持对场景状态的持续理解,构建从感官记忆、短期记忆到长期语义记忆的分层体系,并支持参数化与非参数化记忆的动态切换;
自主决策:根据任务目标,借助慢思考进行推理与自我校正,对复杂目标进行长程拆解与动态重规划,以及借助对物理世界的理解来预测行为后果;
自主执行:将空间推理的结果转化为各类可操作的指令,甚至于从用工具、学工具,演化为造工具。
E-ViC 正是在"自主感知"层面迈出的关键一步:它赋予模型主动与环境交互的能力,而不再是被动地"接受一张图、输出一个答案"。这是通向真正意义上物理空间智能的必经之路。
从感知到决策,从数字空间到物理现实,旷视相信真正的智能必须扎根于对物理世界的深刻理解,而E-ViC 是这个方向上的一次重要探索,我们将继续深耕这条路,让AI走向更广阔的物理现实。
相关文章
- 一句话完成合同审批全流程,合合信息联合亚马逊云科技打造多模态文档智能体
- 物理世界智能的优化:从文本思考到多模态思考
- 深耕AI+音视频二十载,佰锐科技多模态行为风险识别跻身行业第一梯队
- 数据的第三种形态:艺恩如何为大模型提供多模态的数据弹药?
- 算力与模型同频共振:天数智芯Day 0 深度适配 SenseNova U1,共筑多模态AI新底座
- 专攻AI供应链治理痛点!多模态SCA智能情报驱动,以AI治理AI实现全域风险可控!
- VPU:多模态AI时代下的视频算力变革
- 海康威视徐习明:聚焦感知多模态大模型,为中国制造业发展服务
- 天数智芯完成Qwen3.5 多模态模型全量适配 全栈技术筑牢生态适配硬实力
- 直击AI多模态媒资痛点!当虹科技荣获浙江省科学技术进步奖
- 小度全系产品将集结亮相AWE 2026,“超能小度”多模态能力成最大看点
- 全球首秀!讯飞AI眼镜亮相MWC,多模态同传大模型与极致轻量化设计 引领智能穿戴新风向
- 合合信息发布多模态大模型文本智能白皮书,破解复杂文档处理困局
- 合合信息发布多模态大模型文本智能白皮书,五大核心能力标准引领复杂文档处理变革
- 昇腾原生支持,科学多模态大模型Intern-S1-Pro正式发布并开源
- 三维天地推出多模态数据湖产品SW-DBLake,重新定义AI时代的数据基石
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


