模型选型专题系列 | 业界首个!元景MaaS平台上线《大模型选型说明书》
2025-09-05 18:15:11AI云资讯2805
当前业内有很多语言模型,我们如何在实际应用中去选择最合适的一款呢?虽然有模型性能的评测基准,但主要关注多语言理解(MMLU)、写作(WritingBench)、逻辑推理(AutoLogi)、数学(AIME)、代码(LiveCodeBench)等方面的通用能力,通常与实际应用场景不匹配。
在实体经济应用场景中,性能最好的模型并非总是最合适的,还需综合考虑推理成本等因素,以实现最高性价比,避免“用大炮打蚊子”。例如,开发短信反诈服务、办公助手、手机操控智能体时,分别选择什么样的模型才能兼顾性能和成本?业界还没有通用的方法论,通常会经历反复试错。
针对以上痛点,中国联通数据科学与人工智能研究院以“能力-场景”双向驱动,在自研的模型能力边界量化基础上,梳理大模型常见应用场景,构建“典型模型-能力类别-能力等级-应用场景”映射图谱,形成《大模型选型说明书》。为开发者提供权威、透明、便捷的选型指导,已助力多场景应用落地,现已在元景MaaS平台发布,将经验与业界共享。

《大模型选型说明书》界面预览
能力和场景精准匹配
首先,调研业界主流大模型评测基准中的能力分类方法,剖析现有能力评估与实际应用需求之间的鸿沟。其次,依托深厚的落地实践积淀,梳理出105个典型的大模型应用场景。结合典型应用场景,提出一种新的大模型能力分类方法,归纳为5大类、27小类;并将每类能力划分为三个等级,包含初级、中级和高级。最后,通过分析模型的能力类别、能力等级与应用场景之间的依赖关系,构建了大模型“能力类别-能力等级-应用场景”关系映射图,如下所示。
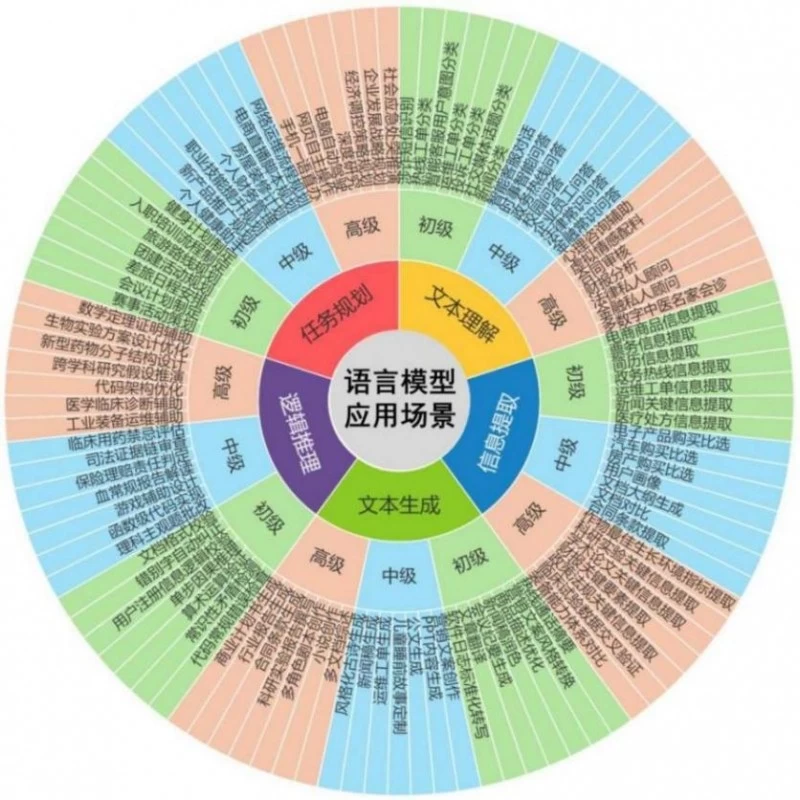
语言大模型“能力类别-能力等级-应用场景”关系映射图
典型模型能力等级评定
针对5大类、27小类模型能力,构建了丰富的评测样本集,对业界超30款主流模型进行测试、打分、统计和分析,给出模型在每个能力类别上的得分,评定模型能力等级。详细评测结果已上线元景MaaS平台,其中部分结果如下图所示。
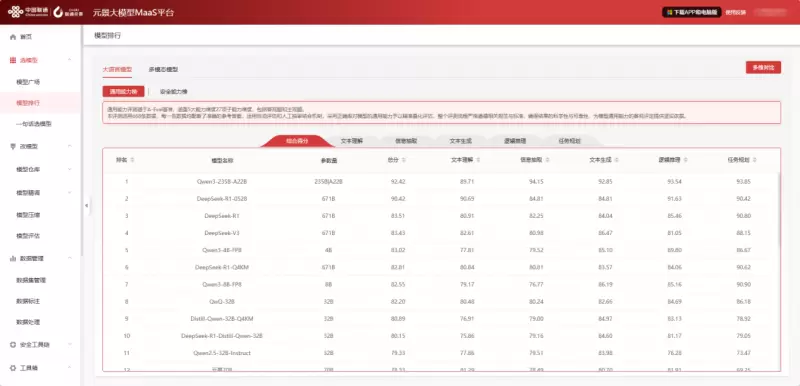
典型模型能力评测结果展示
选型使用说明书构建
基于模型能力等级评定结果,结合“能力类别-能力等级-应用场景”关系图谱,建立超30款典型模型与105个典型应用场景间的匹配关系,形成“典型模型-能力类别-能力等级-应用场景”关系图谱,作为《大模型选型说明书》,部分内容如下所示。
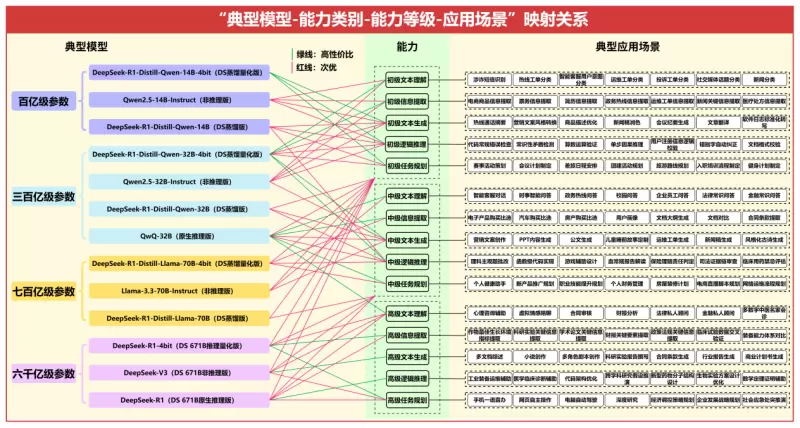
“典型模型-能力类别-能力等级-应用场景”关系图谱
应用赋能和迭代更新
《大模型选型说明书》作为业界首个语言大模型选型经验指南,一方面可以帮助开发者根据应用场景找到兼顾性能和成本的高性价比模型,另一方面提供了每个模型能胜任的典型应用场景,为模型选型决策提供经验参考,极大降低大模型开发应用技术门槛。
目前,已赋能电信反诈、智能工单、客服助手、手机自动驾驶、深度研究等超20个应用场景落地。未来,中国联通数据科学与人工智能研究院将持续扩充评测模型库和典型应用场景,动态更新《大模型选型说明书》,确保其始终反映技术前沿与市场变化。
联通元景大模型将继续秉承“多模共生、普惠速成、场景深耕、数智融合、安全自主”五大特性,构建多模共生的模型家族,打造普惠速成的MaaS平台,开发场景深耕的智能体应用,助力千行百业实现智能化升级,加速人工智能+的推广应用,让人工智能更简单。
相关文章
- 国内首家!浩鲸科技鲸智大模型Token运营平台获信通院双认证
- 天数智芯全栈算力底座Day0适配GLM-5.2 自主创新架构铸就国内大模型长程推理新标杆
- 越疆将发布下一代陪伴交互AI人形机器人,以自研大模型重新定义家庭具身智能
- 联想ThinkPad P14s/P16s AI 2026移动AI工作站发售,轻松驾驭大模型和专业创作
- 网易有道27B开源小模型直接登顶!技术大V:语音克隆功能超强,翻译后毫无外语口语
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 科技照进现实 鸿蒙原生首个3D大模型AI应用V2Fun正式发布
- 极佳视界再获10亿B2轮融资持续领跑世界模型驱动的物理AGI
- 大模型驱动算力需求扩容 寒武纪产品落地多行业
- Anthropic发布首款Mythos系列模型Claude Fable 5
- 斑马智能董事长张建锋:全模态端侧大模型将实现座舱主动智能
- 云知声发布 U2:为执行而生的原生智能体大模型,可自主拆解并完成 100+ 步复杂真实工作流
- 全球首个!大晓机器人推出全屋三维可交互世界模型 Kairos-HomeWorld
- 华为云联合TOP模型厂商发布“百模千态,云聚共赢”生态合作计划
- 中科闻歌重磅发布通用决策大模型Decitron决策机,内测邀请开启
- 华为云发布新一代ModelArts Next模型训推平台,使能模型深入企业场景
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


