英伟达Rubin平台采用HBM4内存实现50 PetaFLOPs算力,搭载88核Olympus架构Vera CPU,相较Blackwell性能提升5倍
2026-01-06 08:32:00AI云资讯3120

(AI云资讯消息)英伟达今日正式发布Rubin人工智能平台,该平台将成为下一代数据中心的核心架构,性能较Blackwell提升5倍。此前业界普遍预期英伟达将在GTC大会上发布相关更新。鉴于人工智能领域的蓬勃发展与CES展会期间全行业对AI技术的高度聚焦,英伟达决定将其重磅AI平台的亮相时间稍作提前。

英伟达Rubin平台将由六颗芯片构成,目前所有芯片已完成晶圆厂生产并运抵英伟达实验室进行测试。这些芯片包括:Rubin GPU(集成3360亿晶体管)、Vera CPU(集成2270亿晶体管)、用于互连的第六代NVLink交换机、用于网络连接的CX9网卡与BF4 DPU、用于硅光互联的Spectrum-X 102.4T共封装光学模块。

这些芯片组合将使Rubin平台在DGX、HGX和MGX系列系统中全面运行。每个数据中心的核心将是英伟达Vera Rubin超级芯片,其配备两颗Rubin GPU、一颗Vera CPU,并采用HBM4和LPDDR5x配置提供海量内存。英伟达Rubin技术的核心亮点包括:第六代NVLink(3.6 TB/s纵向扩展带宽)、Vera CPU(定制化Olympus核心架构)、Rubin GPU(50 PetaFLOPS NVFP4 Transformer引擎)、第三代机密计算(首个机架级可信执行环境)、第二代RAS引擎(支持零停机健康检测)。

首先来看Rubin GPU,这款芯片采用双光罩模片设计,每个模片都集成了大量计算核心与张量核心。该芯片专为AI密集型工作负载打造,可提供50 PetaFLOPS的NVFP4推理算力与35 PetaFLOPS的NVFP4训练性能,分别达到Blackwell芯片的5倍和3.5倍。芯片同时搭载HBM4内存,每芯片内存带宽最高达22 TB/s,较Blackwell提升2.8倍;CPU侧NVLink带宽为3.6 TB/s,实现2倍于Blackwell的传输速率。

针对Vera CPU,英伟达研发了新一代定制化Arm架构(代号Olympus)。该芯片集成88个核心、176线程(支持英伟达空间多线程技术),配备1.8 TB/s NVLink-C2C一致性内存互联通道,支持1.5 TB系统内存(为Grace平台的3倍),通过SOCAMM LPDDR5X实现1.2 TB/s内存带宽,并具备机架级机密计算能力。这些特性共同带来相较于Grace平台2倍的数据处理、压缩及CI/CD性能提升。
第六代NVLink交换机为Rubin平台提供网络架构,采用400G SerDes技术,每CPU支持3.6 TB/s全对全带宽,总带宽达28.8 TB/s,支持14.4 TFLOPS FP8网络内计算,并采用100%液冷设计方案。

网络连接由最新ConnectX-9与BlueField-4模块驱动。ConnectX-9超级网卡提供1.6 TB/s带宽,采用200G PAM4 SerDes技术,配备可编程RDMA与数据路径加速器,具备顶级安全性,并为超大规模AI集群进行深度优化。
BlueField-4是一款面向智能网卡与存储处理器的800G DPU。该芯片集成64核Grace CPU与ConnectX-9网络模块,相比BlueField-3实现2倍网络传输能力、6倍计算性能与3倍内存带宽提升。

所有这些技术最终汇聚于英伟达Vera Rubin NVL72机架系统,相较Blackwell平台实现显著性能跃升,具体数据如下:NVFP4推理性能提升5倍(达3.6 EFLOPS)、NVFP4训练性能提升3.5倍(达2.5 EFLOPS)、LPDDR5x内存容量提升2.5倍(达54 TB)、HBM4显存容量提升1.5倍(达20.7 TB)、HBM4显存带宽提升2.8倍(达1.6 PB/s)、纵向扩展带宽提升2倍(达260 TB/s)。
英伟达同时发布Spectrum-X以太网共封装光学解决方案,提供102.4 Tb/s横向扩展交换架构,集成200G硅光共封装技术,在大规模部署中可实现95%的有效带宽利用率。该系统能效提升5倍,可靠性增强10倍,应用程序运行效率提高5倍。

针对Rubin SuperPOD系统,英伟达同时推出推理上下文内存存储平台。该平台专为千亿级参数推理场景构建,并与英伟达Dynamo、NIXL及DOCA等软件解决方案实现全面集成。

总而言之,英伟达将在其顶尖的DGX SuperPOD中部署Rubin平台,采用8组Vera Rubin NVL72机架。此外,针对主流数据中心市场,英伟达还将推出NVIDIA DGX Rubin NVL8配置方案。
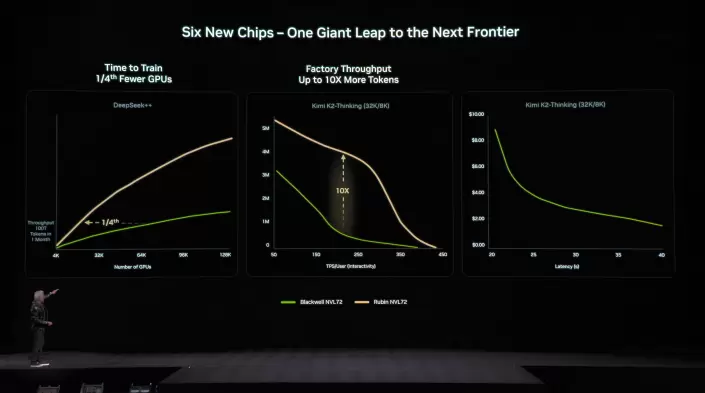
凭借这些技术进步,相比Blackwell GB200平台,英伟达Rubin平台将推理token成本降低10倍,训练MoE模型所需GPU数量减少4倍。Rubin生态系统已获得众多合作伙伴支持并实现全面量产,首批芯片将于今年晚些时候交付客户。
相关文章
- 英伟达Rubin全液冷时代,川润股份“算力液冷+绿色能源”全链条闭环服务卡位千亿赛道
- AMD EPYC Venice处理器到2027年将以675万颗的出货量超越英伟达Vera CPU
- 英伟达称其AI数据中心采用高温运行设计,可大幅减少用水量
- 英伟达抢建物理AI算力工厂,微美全息(WIMI.US)锚定芯片赛道掀起GPU热潮!
- 云工场科技加快多元智算布局,构建 AMD、沐曦、英伟达协同算力体系
- 数据中心耗电远超电网负荷,迫使英伟达与谷歌在2026年第三季度前启动800V直流电架构改造
- 苹果在新版Siri上作出妥协:依靠英伟达B200 GPU加密技术,防止谷歌窃取用户数据
- 英伟达发布RTX Spark芯片,高调杀入PC市场
- 维谛(Vertiv)将在COMPUTEX展示首个面向英伟达NVIDIA Omniverse DSX Blueprint的全融合物理基础设施数字孪生能力
- AI驱动量子计算风口已至!英伟达/微美全息抢占高地锁定量子生态席位!
- 英伟达首席财务官调侃竞争对手因存储芯片短缺措手不及
- SpaceXAI宣布将向Anthropic开放搭载22万张英伟达GPU的巨像一号超级计算机
- OpenAI宣布与AMD、英伟达、英特尔、微软及博通达成超级合作,合力加速AI发展
- Anthropic看中英国初创公司融合技术,以仅英伟达Groq十分之一的成本,实现百倍速度的AI推理
- 英伟达发布开源AI模型Neomotron 3 Nano Omni,性能提升高达9倍
- 英伟达Rubin芯片落地谷歌A5X实例,多站点集群规模扩展至近百万颗GPU
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布


