算力靠“连”不靠“堆”!选对机头CPU才能引爆AI服务器潜能
2026-02-05 12:26:55AI云资讯1836

如果要用两个字来形容当下AI技术热潮,在模型或AI应用层面无疑就是一个“大”字,它背后是越来越复杂的模型架构,以及动辄百亿千亿的参数规模;硬件或算力层面则是个“多”字,直指AI算力基础设施对GPU或AI加速器“多多”益善的追求,这也是全球顶尖AI玩家们大搞GPU“军备竞赛”或“囤卡备战”的底层逻辑,即手里卡够,心里不慌。
卡堆够了,算力就能随叫随到了么?No,这只是万里长征第一步,下一步考验的是连卡,也就是在小到单个AI服务器节点,大到千卡万卡级的集群中,如何才能让堆上去的多块GPU或AI加速器实现最大化互连与通信效率,这才是它们高效协作输出充沛算力,不浪费每一分投资的关键。
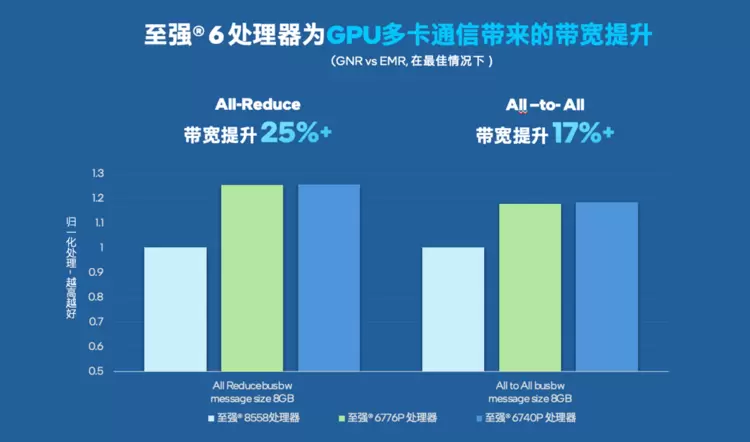
在连卡的过程中,机头或主控CPU的作用是不可忽视的,选对产品与型号带来的收益也超乎想象,以英特尔最新公布的一组数据为例,选择至强6性能核处理器作为机头CPU,在最佳场景下,其NCCL All-Reduce带宽相较第五代至强可扩展处理器可提升达25%以上,All-to-All带宽提升也有17%以上。
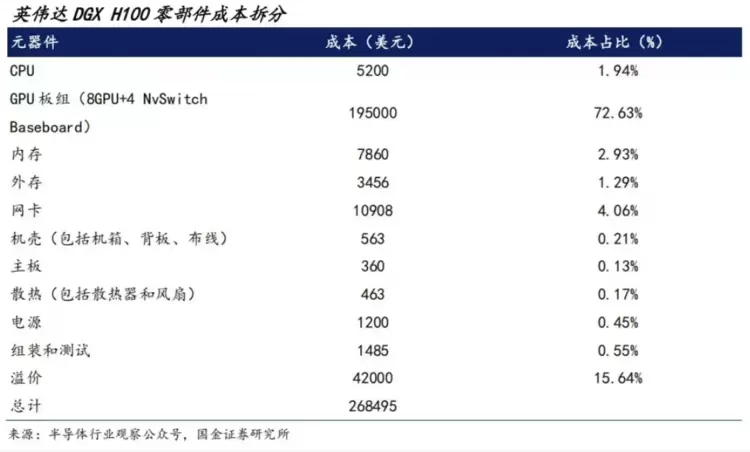
有趣的是,换来这些提升的成本,对整个AI服务器或集群的采购或总拥有成本来说,都是九牛一毛——援引国金证券研究所对英伟达DGXH100零部件成本的拆分,机头CPU成本占比只有1.94%。即便把成本拆分的目标换成定位中低端的AI服务器,GPU或AI加速器也依然是大头所在。相比之下,机头CPU虽然在投入上微不足道,却能扮演撬动整个系统或集群效率的“杠杆”,它能撬开、释放GPU和整个AI服务器的全部潜能,这才是真正意义上的花“小钱”、办“大事”。
多卡通信,何以“至强”?
收益看到了,要付出什么也很清晰,也许你想进一步深究至强6提升多卡互连与通信效率的秘籍,那下面这一张图就足以揭示它的底气所在。
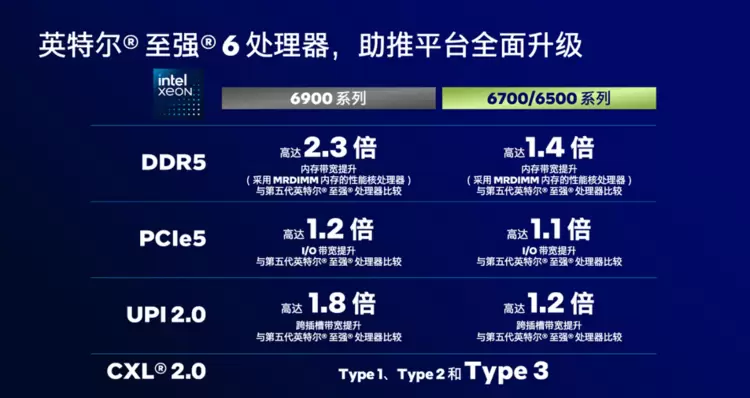
这张图上涉及的几乎所有硬件规格与性能提升,不论是直接服务于GPU/AI服务器的PCIe,还是作为整个系统数据交换池的内存子系统,又或是CPU间互连的UPI,其最终目标都可作用于多卡通信这一核心场景,即为GPU之间的数据交换铺设更宽、更快的“高速公路”,其最直观的体现就是多卡互连通信带宽及时延压缩的显著改善。
这种改善有何实际意义?以AI模型的分布式训练场景为例:各个GPU节点需要频繁地同步梯度参数(All-Reduce过程),这正是最考验通信效率的环节,而在样本分片重分配等场景中,All-to-All 过程同样对通信链路有着强需求。如果机头CPU能提供更高的聚合带宽,能让数据汇总和分发的速度更快,就可缩短训练的单步迭代时间,加速整个训练进程。
再以应用更广泛、也标志着AI真正投入实战的推理场景,如目前越来越火的多模态大模型推理为例,虽然它不需要做梯度同步,但All-Reduce性能提升仍可能作用于多节点推理的协调或一致性生成中的多GPU同步;All-to-All性能提升在推理中更加关键,其生成速度(或等待时间)、服务吞吐(单位时间能否服务更多客户)、应用规模(能否支持更多模型或更长序列)等关键指标,都可借势得到进一步优化。
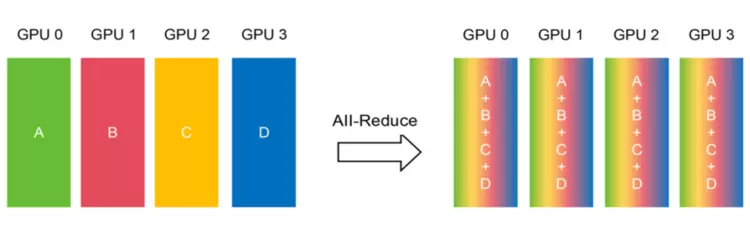
行业背书:机头CPU的“默认选项”
通过上面的例子,我们能清晰感受到:GPU就像高精尖的“算力工厂”,产能惊人。但如果连接这些工厂的道路网络(数据链路)频繁“堵车”,信息流转不畅,那么再强的生产力也无法有效协同,最终导致昂贵的GPU资源在等待中被空耗。在这个背景下,如何高效疏导数据流,保障多卡通信的畅通无阻,变得比以往任何时候都更加重要。说白了,算力再强也怕堵!
因此在日趋庞大和复杂的AI集群中,就需要一个“交通总指挥”来统一调度数据、分派任务。这个角色,正是由机头CPU来担当。多年以来,英特尔® 至强® 处理器凭借其强劲可靠的通用计算能力、出色的稳定性和广泛的生态兼容性,一直是业界公认的机头CPU默认选项。
这种行业共识并非空穴来风。来看看行业风向标——英伟达的动作吧,它早就在其官方解决方案中将至强处理器作为官方认证和推荐的机头CPU选择。2025年双“英”还进一步升级了双方的合作关系,其中关键一条就是英特尔将利用NVLink设计和制造定制化的数据中心CPU,其用途不言而喻。
需要说明的是,这种共识的背后,可不仅是行业对至强处理器在多卡互连与通信这一单项能力的认可。也许对于其他CPU产品来说,其计算、通信与存储的性能可支持GPU高效顺畅的工作,就已是接近“满分线”的表现,但对至强来说这些只是作为机头CPU的“基线”而已,在这条线之上,它还能用内置AMX技术帮GPU分担AI数据预处理,特别是向量数据库的加速;能借助CPU更大容量的内存从GPU上卸载MoE,特别是冷专家,以释放GPU显存来提升并发度和拓展上下文窗口;能用六大类52项RAS功能来保障AI服务器或集群的高可靠、高可用和高可维护,助力用户实现99.999%的可靠性;能借助TDX技术构建硬件级“可信AI”执行域,甚至CPU与GPU之间都会构建加密专线来强化AI模型与数据的保护……这些,才是它的独有的加分项,才是它能脱颖而出,成为行业默认机头CPU靠谱之选的竞争力。

©英特尔公司,英特尔、英特尔 logo 及其它英特尔标识,是英特尔公司或其分支机构的商标。
*文中涉及的其它名称及品牌属于各自所有者资产。

相关文章
- 香港最大国产智算中心!商汤携手香港科技园打造4万P国产算力基建
- 天数智芯全栈算力底座Day0适配GLM-5.2 自主创新架构铸就国内大模型长程推理新标杆
- 青云科技AI算力云荣获智算云服务标杆
- 科士达极简革新探索,赋能AIDC零碳算力高质量转型
- 云工场科技加快多元智算布局,构建 AMD、沐曦、英伟达协同算力体系
- 年增千亿度算力用电,华润新能源拥抱AI时代绿电大机遇
- 国产最强通用计算平台发布:中国高精度算力底座迈入“百核时代”
- 云工场科技将携AIoT道路巡查与算力体系,亮相大湾区智慧交通大会
- 中科曙光发布新一代通用高性能计算平台 高精度算力底座升级
- 逐代码星河 战算力之巅!2026第十三届并行应用挑战赛正式启航
- 石油石化行业数字底座建设实践:企业云、分布式存储与算力资源融合
- 大模型驱动算力需求扩容 寒武纪产品落地多行业
- AIDC 算力基建迭代|科士达全栈电冷方案:从兆瓦级UPS 到 LiquiX 液冷
- 云工场科技硬核筑基!无锡市算力调度运营平台正式亮相
- 瞄准AI算力网络关键环节,中科融合与汉天下共建MEMS OCS C-IDM平台
- AI角逐重安全,海光自研C86筑牢机密算力
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


