当 Cloudflare 停摆:真正击垮企业的从来不是宕机,而是误判
2026-02-09 13:36:12AI云资讯1866
在 2025 年 11 月 18 日Cloudflare全球大规模宕机后,12 月 5 日 Cloudflare 又遭遇了一次大范围服务中断,返回“500 内部服务器错误”信息,导致全球诸多网站和在线平台纷纷宕机。
误判的根源
传统安全“看得见流量,看不懂行为”
当外部链路出现大范围异常时,企业内部往往会同步出现:超时、失败率骤升,重试流量激增,各服务指标剧烈波动,以及链路长尾放大。传统安全系统只看到这些“异常表象”,却无法理解其产生的原因,于是大量误判随之而来。
误判的本质不在于算法弱,而在于系统“无法理解行为”。这主要体现在以下三个方面:
1.缺乏运行时上下文:规则、流量特征、阈值变化,只能判断“像不像攻击”,却无法判断“是否真的触发了攻击动作”。
2.可观测性与安全割裂:指标、日志、Trace 分散在不同平台,安全系统难以形成统一视角,自然无法回答:“哪条请求 → 触发了哪段代码 → 导致了什么动作?”
3.微服务链路导致误判指数级放大:一个请求跨越 5~10 个服务。缺少任一段上下文,判断都可能偏差。
全球性故障暴露的核心问题,在于企业缺乏一个能够穿透复杂依赖、直达问题本质的观测与响应体系。
构建全域可观测韧性
从感知到定位的立体防御
全球性故障暴露出的核心问题,在于企业缺乏一个能够穿透复杂依赖、直达问题本质的观测与响应体系。听云通过整合前端、网络、应用层及安全侧的可观测能力,构建了一套从即时感知、精确定位、到智能决策的完整韧性系统。
01丨快速发现
RUM是最快的“警报器”
RUM 在这次故障中的核心价值在于零延迟地感知用户影响,并迅速定性故障。
01毫秒级错误率飙升检测
RUM 表现:在 11:28 UTC 客户首次报告 5xx 错误时,一个配置良好的 RUM 产品应该已经在全球范围内观察到 HTTP 5xx 错误率的陡峭飙升。
传统监控的滞后性:传统的后端监控可能需要几分钟才能确认是全局问题(因为要排除内部网络抖动或特定服务器负载高),但 RUM 看到的是用户浏览器接收到的最终错误,它反映了用户的真实体验。
结论:RUM 是最快拉响警报的工具。它能立即将故障提升为 P0 严重度。
02纠正排查方向:不是DDoS
时间线的挑战:Cloudflare 工程师花了超过 90 分钟(11:32–13:05)误以为是 DDoS 攻击。
RUM 的贡献:RUM 可以快速提供请求量与错误率的对比数据。
如果是 DDoS,RUM 应该看到 总请求量(或带宽)暴增,然后由于系统过载导致 5xx 错误率上升。
在这次事件中,RUM 看到的是总请求量可能持平或下降(因为请求被 Cloudflare 拦截或直接失败),但 5xx 错误率却从 0 飙升到极高水平。
结论: RUM 的数据能迅速证明这不是容量问题,而是服务可用性(Availability)问题,从而帮助团队在 11:32 就纠正排查方向,节省了 90 分钟的 MTTR。
然而,RUM 存在能力盲区,它无法定位这次故障的根本原因,因为它不具备对内部基础设施的洞察能力。RUM 只能看到 Cloudflare 边缘节点返回的 HTTP 响应头和状态码(500/503),看不到 ClickHouse 数据库的权限变更记录、内部 Bot Management 系统的特征文件大小,以及 Rust 核心代码中的 unwrap() 堆栈追踪。
02丨独立观测
听云Network当 CDN 宕机客户的自救从哪里开始?
当你使用全球 CDN、DNS 或云代理服务时,你的业务健康度已经部分掌握在别人手里。当第三方网络层出问题时,客户最典型的三大困境是:监控断层(内部系统正常,用户访问超时)、责任不清(厂商说“网络可达”,用户却打不开)、响应滞后(等官方公告才确认)。
01
客户真正的痛点不是“挂了”
而是“不知道为什么挂了”
当第三方网络层出问题时,客户最典型的三大困境是:

这些问题的根源在于:企业缺乏一个“独立于厂商”的、外部用户视角的可观测体系。
02
拨测的核心价值:
帮你看清“你与厂商之间”的那段路
拨测不是替厂商“抓错”,而是替客户“还原事实”,当 CDN 或云服务宕机时,听云 Network 的拨测体系可以帮企业在几分钟内回答这四个关键问题:

03
解决方案:
从“发现”到“行动”的四步闭环
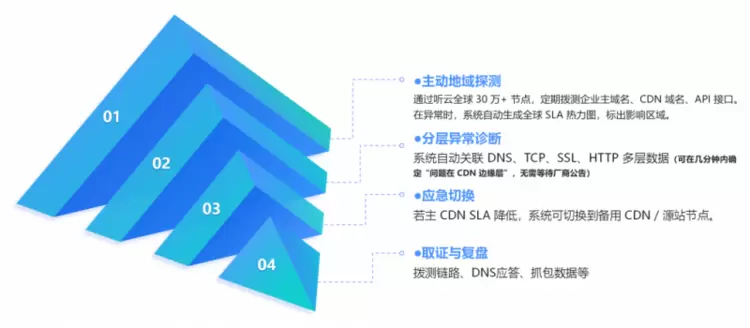
听云 Network 通过主动地域探测、分层异常诊断、应急切换和取证与复盘,构建了从“发现”到“行动”的四步闭环,帮助客户建立独立的观测韧性。
03丨精准定位
听云 APM
如何快速定位 Rust 程序的致命崩溃
在这类 Cloudflare 级别的重大故障中,除了误判风险之外,另一项关键挑战是:如何在 5xx 错误爆发时,第一时间定位内部的崩溃根源,而不是误以为遭遇攻击。
听云 APM(应用性能监控)通过“指标 → 链路追踪 → 运行时异常”三段式能力,构建了从现象到根因的完整闭环。
01
指标(Metrics):
从 5xx 激增到即时警报
Cloudflare 的事故最早暴露的信号,是核心代理系统(FL/FL2)的 5xx 错误数量突然急剧上升。
听云 APM 的实时指标能力可以:
持续监控核心服务的成功率/错误率,在 5xx 数量突破基线时立即触发警报,明确告诉团队:“已经不是正常波动,而是系统级故障”。这让团队能够在错误首次显现的第一分钟,就看到无可争议的故障信号,避免在早期因 “区域性、偶发性” 而忽略问题。
02
分布式追踪(Tracing):
精准锁定 Rust 程序崩溃点
当 5xx 警报响起后,关键在于快速回答两个问题:
是否来自外部攻击?内部链路的哪一段崩溃了?
● 指标 (Metrics) 警报 + 消除干扰: 基于 OpenTelemetry Metrics 标准,实时监控 5xx 错误 HTTP 状态代码数量 的剧增。同时,APM 应具备关联性分析,如果核心指标异常,且日志未显示大量外部流量特征,应迅速排除 DDoS 误判。
●追踪 (Tracing) + 异常堆栈锁定: 利用 OpenTelemetry 分布式追踪,在 5xx 错误链路中快速捕获 Rust 核心代理 的底层崩溃信息(thread fl2_worker_thread panicked: called Result::unwrap() on an Err value)。此信息是内部逻辑错误的铁证,可立即将调查重点从外部攻击/过载转向代码执行和配置数据。
听云的分布式追踪会自动记录每一个请求经过的链路:当请求到达 Cloudflare 的核心代理 FL2、代理从 ClickHouse 读取“特征文件”(Feature File)、文件异常变大 → 触发读取失败、Rust 模块在执行 unwrap() 后直接 panic。
在链路中,这个异常点会被精准标记。
●链路起点:追踪 Span 的创建与初始化
当用户的请求在 HTTP/TLS 层终止,并进入核心代理系统(如 FL/FL2)时,基于 OpenTelemetry 标准或 APM 系统的探针必须立即介入,完成以下步骤:
➢ 启动追踪: 为该请求创建一个 主 Span (Root Span)。该 Span 标记了整个请求链路的起始点和持续时间,是后续所有操作的计时和上下文载体。
➢ 上下文初始化: 确保链路上下文(TraceID/SpanID)已初始化,并准备好沿着请求流向下游传播。
●Span 上下文信息的深度注入与富化
当代理系统执行关键的外部依赖调用(例如,从 ClickHouse 数据库集群获取特征文件)时,必须将以下关键的上下文信息注入到当前活动的 Span 中:
➢ 依赖信息: 数据源标识(如 ClickHouse 查询的标识或连接串),用于精确匹配和追溯异常的 Clickhouse。
➢ 系统配置: 当前设定的资源限制(例如,连接池配置),用于区分是代码错误还是配置超限导致的故障。
●OTel × Rust 深度集成:Span 捕捉崩溃
在 Rust 模块中(如机器人管理模块),通过 OpenTelemetry Tracing API 植入关键 Span,当程序执行到异常分支时,崩溃堆栈、错误路径、线程 panic 信息,都会原样记录到链路中。
03
直击异常堆栈:捕获 Rust panic 根因
OpenTelemetry Logging 会把 crash 信息直接写入对应的 Trace 中,形成“证据链”。
例如 Cloudflare 事故中的关键信息:
thread fl2_worker_thread panicked: called Result::unwrap() on an Err value
这条信息的意义非常明确:
程序并未遭遇外部攻击、崩溃的根因是 Rust 代码对异常数据使用了 unwrap() 强制解包、核心代理线程因此 panic,触发 5xx 洪峰、整个问题是内部配置数据异常导致而非 DDoS。这种基于链路与堆栈的“可证据化判断”,能让团队在数分钟内锁定故障点,避免方向性错误。
04
优化策略:
APM 的“诊断悖论”与动态采样
根据复盘信息,在受影响期间,CDN 的响应延迟显著增加。这是因为 Cloudflare 调试和可观测系统消耗了大量 CPU 资源,这些系统会自动为未处理的错误添加额外的调试信息。
这种现象揭示了 APM 在大规模故障时的“诊断悖论”:为了获取故障的详细信息,诊断工具本身的资源消耗反而可能加剧服务的性能问题(延迟增加)。
APM 必须采取以下策略,以实现可观测性与资源消耗之间的平衡:
●实施错误报告节流与资源预算限制
目标: 防止核心转储或其他错误报告占用过多系统资源。
当系统遭遇大规模、高频率的错误(例如 5xx 错误数量激增)时,APM 系统必须具备自我保护机制,以确保诊断工具本身不会成为瓶颈。
➢ 资源预算限制: APM 代理应设置严格的 CPU 和 I/O 预算限制。一旦核心代理(如 FL2)的错误率达到临界阈值,APM 系统应立即启动节流机制。
➢ 信息详细程度降级: 避免生成资源密集型的完整核心转储。相反,APM 应降级为只收集关键的、轻量级的信息,例如:只记录导致线程崩溃的 异常堆栈信息(如 panic),并对重复发生的高频错误进行聚合和采样,以降低整体数据处理负荷。
●采用动态自适应采样 (Adaptive Sampling)
目标: 将有限的诊断资源集中于最有价值的故障数据,避免为正常流量或低价值的重复错误浪费 CPU。
➢ 状态驱动的优先级: 当 APM 检测到 5xx 错误 HTTP 状态代码的数量急剧增加 时,系统应从常规的随机采样切换为基于错误的优先级采样。
➢ 实施细节:
在可观测性与APM系统中,数据采集的深度与资源消耗直接相关。为在确保故障可诊断性的同时避免自身成为性能瓶颈,可采用以下采样或熔断策略:
● 探针熔断:系统可根据实时资源使用情况,自动调整采样策略与资源分配,实现观测力度与系统开销之间的平衡,确保业务性能不受观测活动影响。
● 对故障请求全量追踪:针对所有导致5xx错误的请求,执行100%全量采集,完整记录分布式链路与异常堆栈,确保在关键故障场景下不丢失诊断所需的核心信息。
● 对正常请求降低采样:在系统异常期间,对仍能成功返回的请求(如200 OK)大幅降低采样率。此举可显著节省CPU、内存与带宽资源,减轻系统整体负载,避免因观测开销加剧业务延迟。
相反,对于在故障时段仍成功运行且快速响应的请求(如 200 OK),则应大幅降低其采样率,从而释放出 CPU 资源,减轻系统整体负载,避免调试和可观测系统本身消耗大量 CPU 资源,进而加剧 CDN 响应延迟。
通过这些策略,APM 能够确保在服务中断的最关键时刻,将 CPU 资源集中用于捕获 定位根源(例如,panic 和特征文件体积异常) 所必需的精确数据,同时避免因过度调试导致系统二次崩溃或延迟增加。这种优化是“防止核心转储或其他错误报告占用过多系统资源”这一后续步骤的直接落地。
从告警到攻击链
构建更清晰、更安静的安全体系
Cloudflare 级别的故障表明,在复杂、多依赖的现代系统中,真正的挑战在于对异常本质的理解能力。通过整合用户侧感知(RUM)、网络层洞察(Network)、应用层诊断(APM)与安全侧智能研判(安云),企业能够构建一个基于全域可观测性的韧性系统。这套体系的核心价值在于:不仅能在大规模故障中快速定位并恢复,更能从根本上减少误判、保持“安静的准确性”,实现从被动响应到主动韧性的转变。
在未来更复杂的数字环境中,安全和运维不可分割,只有将安全能力融入到全域可观测的运维体系中,才能真正实现系统的韧性与稳定。理解本质,远比捕捉表象更重要。
相关文章
- 年糕妈妈获评“优质网络主播培育工程”首批优质直播间
- 跨越三大洲的“芯”路连接:南凌科技SD-WAN赋能全球芯片巨头构建研发协同网络
- 中国移动研究院段晓东:从“AI Native”到“Token Native”,算力网络迈向发展新阶段
- 中国信通院副院长敖立:深化“千兆普及”,推进“万兆启航”,加快我国宽带网络提质升级
- 中国电信集团市场部副总经理章峻青:全力推进宽带提质升级,为亿万家庭筑牢网络底座
- 勤哲Excel服务器:助力网络数据运营企业,实现高效数字化转型
- 锐捷一机一网3.0全新发布:打造一张可成长的网络
- 游族网络发布2025年报及2026一季报:海外表现亮眼,AI推动经营效率稳步提升
- 白山云与 Sparkle 达成战略合作,强化欧洲及全球网络性能
- 速率超1G的中国移动5G-A超级上行网络来了
- 中国联通护航文旅新地标 智慧网络点亮灵玲开园
- 山东瑾瑜网络科技:AI无人直播,零门槛开启AI创业新机遇
- 爱奇艺龚宇出席中国网络视听大会:AI振兴影视行业每一帧
- 慧博云通亮相第十三届中国网络视听大会,AI驱动产业新升级
- Aginode安捷诺:OpenClaw开启的智能体浪潮,如何重塑下一代智算网络?
- Aginode安捷诺:当AI重塑算力格局,智算网络技术如何应对多维挑战?
人工智能企业
更多>>



人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力
- 昇腾原生支持,科学多模态大模型Intern-S1-Pro正式发布并开源
- 百度千帆深度研究Agent登顶权威评测榜单DeepResearch Bench


