昇腾0day支持智谱GLM-5,744B模型单机高效推理
2026/02/13 09:39AI云资讯16797
2026年2月12日,智谱AI发布Agentic Engineering时代最好的开源模型GLM-5,从“写代码”到“写工程”的能力进一步演进。在Coding与Agent能力上取得开源SOTA表现,在真实编程场景的使用体验逼近Claude Opus 4.5,更擅长复杂系统工程与长程Agent任务。昇腾一直同步支持智谱GLM系列模型,此次GLM-5模型一经开源发布,昇腾AI基础软硬件即实现0day适配,为该模型的推理部署和训练复现提供全流程支持。
更大基座,更强智能
● 参数规模扩展:从355B(激活32B)扩展至744B(激活40B),预训练数据从23T提升至28.5T,更大规模的预训练算力显著提升了模型的通用智能水平。
● 异步强化学习:构建全新的“Slime”框架,支持更大模型规模及更复杂的强化学习任务,提升强化学习后训练流程效率;提出异步智能体强化学习算法,使模型能够持续从长程交互中学习,充分激发预训练模型的潜力。
● 稀疏注意力机制:首次集成DeepSeek Sparse Attention,在维持长文本效果无损的同时,大幅降低模型部署成本,提升Token Efficiency。
Coding能力:对齐Claude Opus 4.5
GLM-5在SWE-bench-Verified和Terminal Bench 2.0中,分别获得77.4和55.7的开源模型最高分数,性能超过Gemini 3.0 Pro。
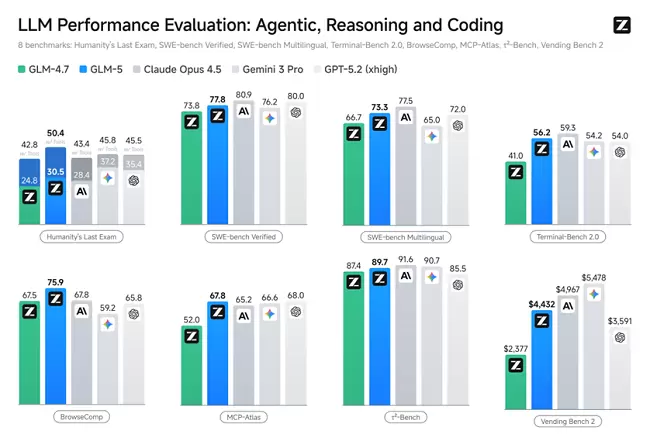
Agent能力:SOTA级长程任务执行
GLM-5在多个Agent测评基准中取得开源第一,在BrowseComp(联网检索与信息理解)、MCP-Atlas(工具调用和多步骤任务执行)和τ²-Bench(复杂多工具场景下的规划和执行)均取得最优表现。
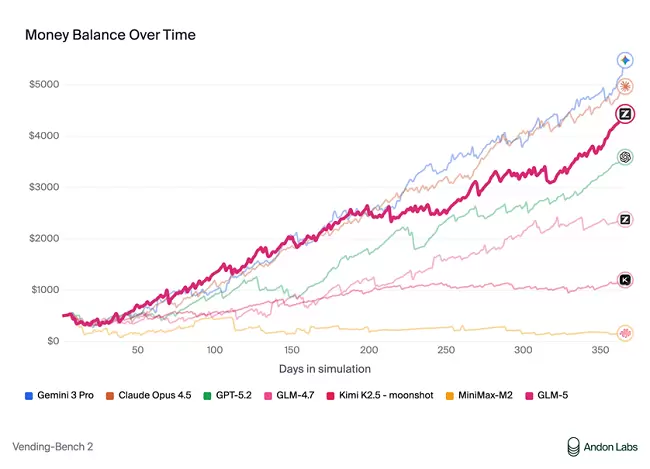
在衡量模型经营能力的Vending Bench 2中,GLM-5获得开源模型中的最佳表现。Vending Bench 2要求模型在一年期内经营一个模拟的自动售货机业务,GLM-5最终账户余额达到4432美元,经营表现接近Claude Opus 4.5,展现了出色的长期规划和资源管理能力。
这些能力是Agentic Engineering的核心:模型不仅要能写代码、完成工程,还要能在长程任务中保持目标一致性、进行资源管理、处理多步骤依赖关系,成为真正的Agentic Ready基座模型。
基于昇腾实现GLM-5的混合精度高效推理
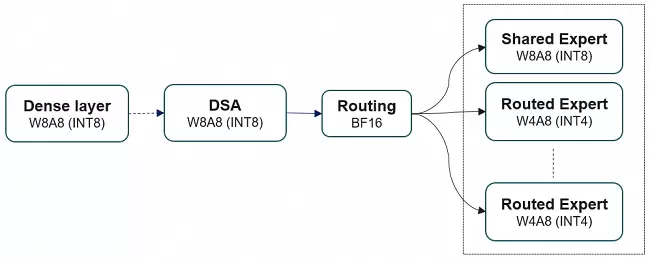
昇腾支持对GLM模型W4A8混合精度量化,744B超大参数模型基于Atlas 800 A3实现单机部署。
GLM-5为78层decoder-only大模型:前3层为Dense FFN,后75层为MoE(路由专家+共享专家),自带一层MTP(Multi-Token Prediction)用于加速解码过程。针对这一模型结构,昇腾对权重文件采用了W4A8量化,极大减少显存占用,加速Decode阶段的执行速度。同时采用了Lightning Indexer、Sparse Flash Attention等高性能融合算子,加速模型端到端的推理执行,并支持业界主流推理引擎vLLM-Ascend、SGLang和xLLM高效部署。
● 权重下载:https://ai.atomgit.com/atomgit-ascend/GLM-5-w4a8
● 推理部署:https://atomgit.com/zai-org/GLM-5-code/blob/main/example/ascend.md
昇腾W4A8量化,极大减少显存占用
采用易扩展的MsModelSlim量化工具,全程轻松量化
1、按模块区分量化比特与算法:例如Attention与MLP主体用W8A8,MoE专家用W4A8;gate等量化敏感层可按需回退,避免过大精度损失。
2、一键即可量化:支持GLM-5量化过程“预处理+子图融合+分层线性量化”的完整流水线,安装后一条命令行即可轻松完成量化:msmodelslim quant --model_path ${model_path} --save_path ${save_path} --model_type GLM-5 --quant_type w4a8 --trust_remote_code True
MsModelSlim提供丰富量化策略,实现快速精度对齐
● 旋转Quarot算法:对权重做Hadamard旋转与LayerNorm融合,降低激活异常值、改善后续量化的数值分布。
● 多种离群值抑制算法:采用Flex_AWQ_SSZ算法和Flex_Smooth_Quant算法混合策略,权重采用SSZ(Smooth Scale Zero)标定,支持缩放因子等超参。
● 线性层量化策略:对单层Linear做W8A8或W4A8,对激活值做per-token粒度量化、对权重做per-channel粒度量化。
高性能融合算子,加速推理执行
1、Lightning Indexer融合Kernel
长序列场景下TopK操作会成为瓶颈,通过引入Lightning Indexer融合算子,包含Score Batchmatmul、ReLU、ReduceSum、TopK等操作,可用TopK计算耗时流水掩盖掉其他操作的耗时,从而提升计算流水收益。
2、Sparse Flash Attention融合Kernel
引入SFA,包含了从完整KVCache里选取TopK相关Token,及计算稀疏Flash Attention操作,可用离散聚合访存耗时掩盖其他操作耗时。
3、MLAPO 融合Kernel
GLM-5在Sparse Flash Attention预处理阶段将query和KV进行降维操作,并且把query降维后的激活值传递给Indexer模块进行稀疏选择处理。近期将会引入MLAPO通过VV融合(多个Vector算子融合)技术,将前处理过程中的13个小算子直接融合成1个超级大算子。除此之外,在MLAPO算子内部,通过Vector和Cube计算单元的并行处理及流水优化,进一步提升算子整体性能。
基于昇腾实现GLM-5的训练复现
GLM-5采用了DeepSeek Sparse Attention(DSA)架构,针对DSA训练场景,昇腾团队设计并实现了昇腾亲和融合算子,从两方面进行优化:一是优化Lightning Indexer Loss计算阶段的内存占用,二是利用昇腾Cube和Vector单元的流水并行来进一步提升计算效率。
训练部署指导:https://modelers.cn/models/MindSpeed/GLM-5
相关文章
- 算力极致 AI极简 2026商业市场鲲鹏昇腾轻量化场景方案发布会圆满举办
- 鲲鹏昇腾开发者大会2026:携手开发者共筑Agentic AI时代算力底座
- 一起昇腾 共绽光芒:昇腾AI开发者峰会2026在京成功举办
- 软硬一体,全栈赋能,慧博云通与宝德计算精彩亮相鲲鹏昇腾开发者大会2026
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 心怀挚爱,共绽光芒——鲲鹏昇腾开发者大会2026即将启幕
- 金融智能新跨越:中国银联依托昇腾算力率先完成DeepSeek-V4私有化部署
- 显示龙头卡莱特完成DeepSeek V4在昇腾平台验证,国产大模型工程化落地提速
- 技术创新赋能千行万业 昇腾人工智能伙伴峰会2026圆满举办
- 昇腾携手20家伙伴发布AI应用场景解决方案 加速千行万业智能化升级
- 昇腾0day支持智谱GLM-5,744B模型单机高效推理
- 昇腾原生支持,科学多模态大模型Intern-S1-Pro正式发布并开源
- 睿思智联获昇腾 Atlas 800T/800I A3 认证:从 “能用” 到 “好用” 定义国产智算精细化管理新标准
- 昇腾云客户2663家,华为云稳居最大国产AI云服务提供商
- 昇腾赋能 TransMLA:无需重训突破架构壁垒,助力主流大模型高效适配 MLA
- 巅峰对决松山湖!鲲鹏昇腾创新大赛全国总决赛2025圆满落幕
AI企业
更多>>




AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


