Soul App联合高校开源SoulX-Duplug,推动全双工语音对话能力落地
2026-05-08 11:46:59AI云资讯1877
随着语音交互在社交与数字娱乐场景中的应用不断深化,传统模型逐渐暴露出局限性。近期,Soul App AI团队联合上海交通大学X-LANCE Lab与西北工业大学ASLP@NPU团队,共同开源全双工语音对话控制模块SoulX-Duplug。该模块围绕语音对话系统的实时交互能力展开,针对当前行业中普遍存在的响应延迟与系统结构复杂等问题提出解决方案,成为语音交互领域的一项重要进展。

在传统语音对话系统中,半双工模式仍占据主流。系统在用户说话时负责接收输入,而在系统回复阶段则无法接收新的语音信号。尽管部分端到端的全双工语音模型能够在生成回复的同时持续接收用户输入,但其通常将语言生成与交互控制高度耦合,导致模型训练复杂度提升,对数据规模与系统调优提出更高要求。在实际工业应用中,更常见的路径仍是通过语音活动检测(VAD)、语音识别(ASR)与对话轮次判断等模块构建级联系统。然而,这类方案在响应速度与语义理解方面仍存在明显短板,例如传统VAD缺乏语义信息、非流式ASR带来额外延迟、多模块串联增加系统负担等。
针对上述情况,SoulX-Duplug应运而生,该模块通过统一建模语音活动检测、流式语音识别以及对话状态预测,实现对语音交互过程的整体优化。在持续音频输入的条件下,系统可以实时理解语音内容,并动态判断当前对话状态,从而实现更自然的交互体验。在技术实现上,SoulX-Duplug基于GLM-4-Voice speech tokenizer,以12.5Hz的频率提取离散语音token,并采用160ms的流式处理窗口进行交替生成。这一机制使模型能够在语音识别与对话状态判断之间建立紧密联系,从而在保证响应速度的同时提升语义理解能力。通过Soul App 团队的这一设计,系统不仅能够识别用户说话内容,还可以判断对话是否应继续、暂停或切换。
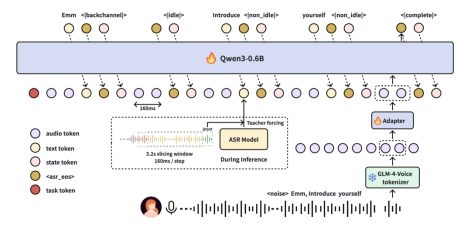
文本引导的流式状态预测是Soul App AI团队的重要创新之一。传统语音活动检测主要依赖声学信号,难以对语义层面进行判断,而该模块通过在训练过程中引入语音识别目标,使模型在进行状态预测时同步学习语义表示。在推理阶段,模型以音频token、识别文本与状态token交替生成的方式运行,从而实现具备语义感知能力的VAD机制。这一方法有效弥补了传统方案在语义理解上的不足。
在训练与部署策略上,SoulX-Duplug采用三阶段训练流程。首先通过非流式语音识别训练模型的基础理解能力,其次在流式环境下进行适配训练,最后通过对话状态预测任务进行联合优化,使模型具备完整的全双工交互控制能力。在推理阶段,系统可结合外部高效语音识别模型,如Paraformer或SenseVoice,从而在实际应用中兼顾稳定性与效率。
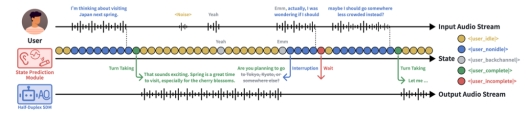
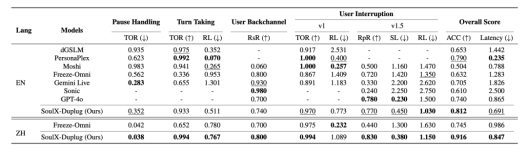
为验证模块性能,Soul App 团队基于SoulX-Duplug构建了完整的全双工语音对话系统,并在中英双语的Full-Duplex-Bench评测基准上进行了测试。实验结果显示,系统在多项指标上表现稳定,在对话轮次管理能力方面优于现有模型,同时在响应延迟方面也取得较为理想的结果。
在实际部署环境中,SoulX-Duplug作为独立模块的平均延迟约为250ms,接近其理论延迟240ms。与传统基于VAD的方案相比(约500ms),以及近期提出的FlexDuo模块(约343ms),其响应速度表现更为均衡。这一结果表明,通过模块化设计与统一建模策略,可以在不增加系统复杂度的前提下优化实时交互性能。此外,Soul App 团队同步开源了SoulX-Duplug-Eval评测基准,为全双工语音对话系统提供统一的双语评估框架。
围绕实时语音对话的关键问题,Soul App此次发布的SoulX-Duplug在系统结构与交互机制上提供了新的实现路径,也为行业提供了可参考的工程化方案。
相关文章
- 聚焦情绪连接,Soul App 创始人团队探索社交新路径
- Soul 创始人张璐团队完善AI治理机制,多维度守护社交生态
- Soul 创始人张璐团队推动AI社交治理升级,筑牢社交安全屏障
- Soul App 创始人团队披露生态治理成果,AI治理拦截违规内容477万条
- Soul App 创始人团队公布Q1生态安全成果:AI赋能清朗社交环境建设
- 东方财经专访Soul创始人张璐团队:近十年深耕,AI让社交回归真实连接
- Soul App发布SoulX-LiveAct开源模型,优化实时数字人生成技术
- Soul App发布开源模型SoulX-LiveAct,解决数字人长视频生成难题
- Soul App开源SoulX-Duplug模块,探索更自然的全双工语音交互路径
- Soul App联合高校开源SoulX-Duplug,推动全双工语音对话能力落地
- Soul App发布年轻人五一出行图鉴,洞察Z世代假期出行偏好
- 五一出行新风向|Soul App读懂Z世代出行选择逻辑
- 从线上到线下,Soul App以“情绪酒馆”丰富社交体验
- Soul App开源SoulX-FlashHead,让实时数字人技术从机房走向个人工作站
- Soul App开源SoulX-FlashHead,轻量化模型推动实时数字人技术迈向消费级终端
- Soul App联名DASH LAND活动开启,探索社交真实感与边界感
人工智能企业
更多>>




人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


