腾讯微视凭BLENDer模型斩获VCR竞赛榜第一
2020-11-30 15:41:55AI云资讯875
视觉常识推理VCR (Visual Commonsense Reasoning )是人工智能领域的前沿热点问题,我国《新一代人工智能发展规划》中也将从处理类型单一的数据到跨媒体认知、学习和推理的“跨媒体智能”纳入五大智能方向。
近日,腾讯微视视频理解团队在多模态理解领域最权威排行榜之一VCR任务中荣登榜首。该团队提出的BLENDer(BimodaL ENcoDer)模型超越百度、谷歌、微软、Facebook等多家研究机构的模型效果,一举成为单、多模型的三项指标第一,值得注意的是,BLENDer仅凭单模型效果便超越了此前榜单上的多模型最好效果,赋予了机器更强大的理解和认知能力,并深度应用到短视频领域。

赶超百度、谷歌等,腾讯微视AI团队登顶VCR榜首
VisualCommonsense Reasoning (VCR)任务于2018年由华盛顿大学的研究人员首次提出,任务旨在将图像和自然语言理解二者结合,验证多模态模型高阶认知和常识推理的能力,让机器拥有“看图说话”的能力, 例如VCR能够通过图片中人物的行为,进一步推理出其动机、情绪等信息。VCR榜单是多模态理解领域最权威的排行榜之一,也是当前图像理解和多模态领域层次最深、门槛最高的任务之一,吸引了微软、谷歌、Facebook、百度、UCLA等国内外公司和研究机构纷纷参与。
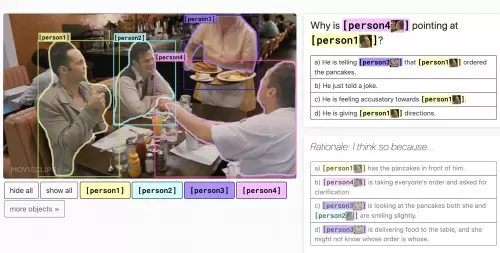
此次拔得头筹的单模型BLENDer来自于腾讯微视视频理解团队,超越上一届榜首百度团队的多模态预训练模型 ERNIE-ViL-large成为新的VCR榜单霸主。
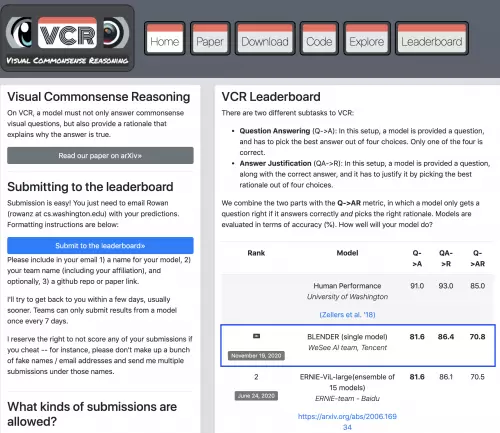
据相关负责人介绍,BLENDer模型已经应用到腾讯微视产品中,赋予了平台更强大的认知能力,使得包含文本、音频、视频等多种媒体信息在内的短视频内容,能够更好的做到分类和识别,更加精准理解和挖掘这些海量的跨媒体信息。例如当腾讯微视用户创作视频后平台可识别内容并精准推荐适合的话题,也能根据内容属性快速推荐给感兴趣的用户,增强创作内容的曝光。
腾讯微视视频理解团队提出的单模型BLENDer,是基于前沿的视觉语言Bert模型,将整个学习过程分成三个阶段,最终将任务的三项问答准确率一举提高到了81.6, 86.4, 70.8的水平,仅是BLENDer单模型上的表现已经超过此前各业界公司和研究机构的多模型融合效果。
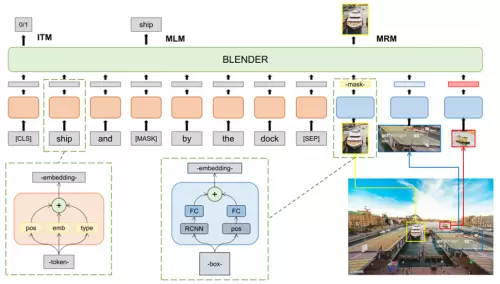
在BLENDer模型中,第一阶段以NLP中的Bert模型为起点,结合海量数据中抽取得到的数百万张图片和对应描述文本作为BLENDer的输入进行多模态训练;第二阶段,在视觉常识推理数据集上学习电影中的场景和情节,使模型在新数据上获得更好的迁移能力;第三阶段,引入最终问答任务,让BLENDer利用已有的知识和常识对现有问题进行人物-人物、人物-场景之间关系的挖掘和关联进行推理,得到最终的答案。
腾讯微视将人工智能技术赋能短视频
一直以来,腾讯微视高度关注技术研发,腾讯微视视频理解团队更是长期深耕多模态语义理解领域,持续进行技术突破和落地,将相关技术应用在海量图像、视频、文本等跨媒体信息的认知推理中。
同时,腾讯微视团队也不断从业务出发探索前沿领域,并将人工智能技术应用到短视频生态中,贯穿内容创作、内容审核以及内容分发的各个环节。
在内容创作环节,腾讯微视将3D人脸、人体、GAN等AI技术结合AR技术辅助用户进行内容创作,让创作过程更加便捷、有趣和普惠;在视频审核环节,腾讯微视借助图像检测、分类、多模态理解等AI技术精准识别视频内容,提升审核效率,使得用户生产的内容最快时间触达消费者,目前腾讯微视内容处理效率已取得业界领先水平;而在视频分发环节,腾讯微视借助AI技术从非结构化的图像、音频、文本数据中提取结构化信息输出,如标签、特征等,支撑分发精准匹配用户。
未来,人工智能将具备更加多元、深度的交流学习能力,而技术的创新和精进将进一步推动AI技术在短视频业务中智能交互场景的落地。
相关文章
- 腾讯首发效率智能体工具集,打造“AI提效新标配”
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- 腾讯云ADP4.0发布:推出Claw模式,助力企业Agent规模化落地
- 腾讯董志强:AI Agent已成为众多企业“数字员工”,安全防护需要同步跟上
- Agent进入“生产级”时代!腾讯云ADP4.0发布,打造企业级 AgentOps平台
- 腾讯文档「人机双写」行业首发,原生接入WorkBuddy打造新一代AI办公工作台
- 未来智能与腾讯云达成战略合作,共筑AI Agent硬件与办公智能体新生态
- 腾讯QQ发布“新芽守护行动”,全面升级未成年人保护体系
- 腾讯云MongoDB获亚太游戏行业“三料第一”
- iCourt第二届全国法律人AI大赛走进腾讯,探见法律AI生态新未来
- 首汽约车与腾讯地图达成品牌战略合作 北京发车仪式圆满举行
- 双展联动!携手宝安区、腾讯云,洲明文博会硬核科技清单请查收!
- 腾讯云联合TC601提出国产 Data+AI平台五步转型路径
- 北京无限迭代与腾讯云和中国电信等公司共同荣获全球AI生态基石大奖
- 金山文档Skill、专家与连接器上架腾讯云WorkBuddy
- 腾讯云TVP走进银河通用×NVIDIA×福田戴姆勒,解码AI驱动产业硬核突围之路
人工智能企业
更多>>





人工智能硬件
更多>>人工智能产业
更多>>人工智能技术
更多>>- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力


