分布式训练中数据并行远远不够,“模型并行+数据并行”才是王道
2019-09-02 08:28:24AI云资讯1093
数据并行(DP)是应用最广的并行策略,对在多个设备上部署深度学习模型非常有用。但该方法存在缺陷,如随着训练设备数量不断增加,通信开销不断增长,模型统计效率出现损失等。来自加州大学洛杉矶分校和英伟达的研究人员探索了混合并行化方法,即结合数据并行化和模型并行化,解决 DP 的缺陷,实现更好的加速。
在多个计算设备上部署深度学习模型是训练大规模复杂模型的一种方式,随着对训练速度和训练频率的要求越来越高,该方法的重要性不断增长。数据并行化(Data parallelism,DP)是应用最为广泛的并行策略,但随着数据并行训练设备数量的增加,设备之间的通信开销也在增长。
此外,每一个训练步中批大小规模的增加,使得模型统计效率(statistical efficiency)出现损失,即获得期望准确率所需的训练 epoch 增加。这些因素会影响整体的训练时间,而且当设备数超出一定量后,利用 DP 获得的加速无法实现很好的扩展。除 DP 以外,训练加速还可以通过模型并行化(model parallelism,MP)实现。
来自加州大学洛杉矶分校和英伟达的研究人员探索了混合并行化方法,即每一个数据并行化 worker 包含多个设备,利用模型并行化分割模型数据流图(model dataflow graph,DFG)并分配至多个设备上。
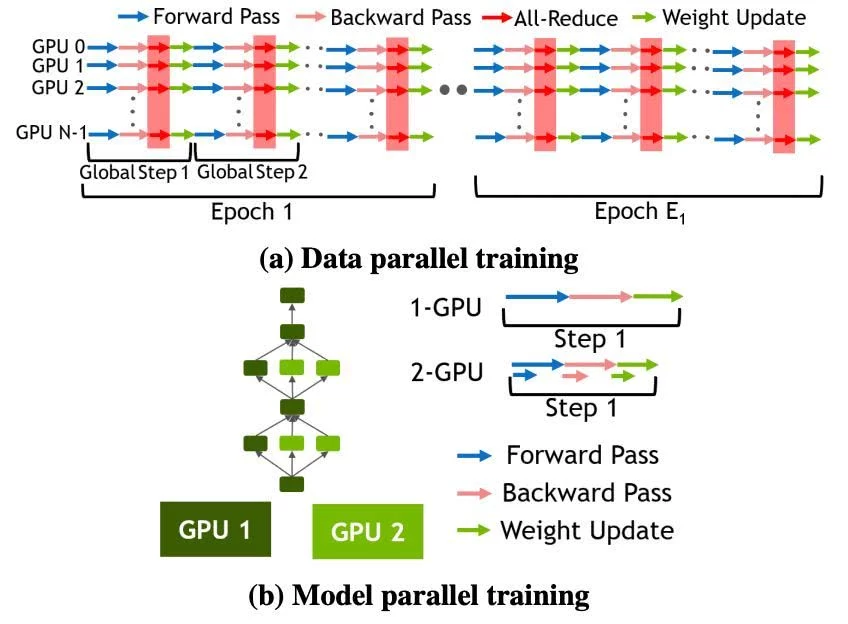
图 2:不同的训练并行化策略,2(a) 展示了数据并行化训练,2(b) 展示了模型并行化训练。
该研究发现,在规模较大的情况下,混合训练在最小化端到端训练时间方面比仅使用 DP 更加高效。研究者对 Inception-V3、GNMT 和 BigLSTM 进行了测试,发现在大规模设置下,相比仅使用 DP 策略,混合策略分别实现了至少 26.5%、8% 和 22% 的端到端训练加速。
哪种并行化策略最高效?
这项研究主要考虑的是,哪种并行化策略可以最小化深度学习模型在可用硬件上的端到端训练时间。研究者问了这么一个问题:如何改进 DP 的扩展效果,结合 MP 和 DP 能够在达到给定准确率的同时最小化端到端训练时间吗?
该研究的新颖之处在于,当设备数量(及全局批大小)增长到某个点时(此时 DP 的扩展性能急剧下降),可以将 MP 和 DP 结合起来使用,从而继续改善训练时间。通过 MP 实现的加速在该临界点是非常重要的。该研究表明,每个网络都有一个独特的规模(scale),使得 MP 获取的加速能够解决 DP 的扩展性能和统计效率下降问题。
该研究的贡献如下:
当 DP 愈加低效时,可以使用混合并行化策略(即每个数据并行化 worker 在多个设备上也是模型并行化的)进一步扩展多设备训练。
开发了一个分析框架,来系统性地找到设备数量(如用于训练模型的 GPU 和 TPU 数量)的交叉点,该交叉点表明在特定系统上优化模型训练时要使用的并行化策略。
展示了混合并行化对于不同规模的不同深度学习网络的性能优于仅使用 DP 的策略。
研究者实现了 InceptionV3、GNMT 和 BigLSTM 的双路模型并行化版本,发现相比仅使用 DP 策略,混合训练可提供至少 26.5%、8% 和 22% 的加速。
提出了基于整数线性规划的工具 DLPlacer,以发现最优的 operation-to-device 布局,从而最大化 MP 加速。
研究者使用 DLPlacer 为 Inception-V3 模型推导出最优的布局,从而展示了其有效性。
真实实验表明,在两个 GPU 的设置中获得的 1.32 倍模型并行加速在 DLPlacer 预测加速的上下 6% 的区间内。
如何最小化端到端训练时间
深度学习模型的端到端训练时间依赖三个因素:每个训练步的平均时间 (T)、每个 epoch 的时间步数 (S) 和达到预期准确率所需的 epoch 数量 (E)。因此,总训练时间即收敛时间 (C) 的公式如下所示:

其中 T 主要由计算效率决定,即给定相同的训练设置、算法和 mini-batch 大小,T 仅依赖于设备的计算能力,因此性能更好的硬件将提供更小的 T 值;
S 依赖于全局批大小和训练数据集中的样本数。
每个 epoch 需要一次性处理数据集中的所有样本,因此每个 epoch 的时间步数 (S) 等于数据集中样本数除以全局批大小。
收敛所需 epoch 数量 (E) 取决于全局批大小和其他训练超参数。
这部分量化了使用数据并行策略的训练时间、使用模型并行策略的训练时间,以及使用混合并行策略的训练时间(详情参见原论文),并得出结论:在一定条件下,混合并行策略的效果优于仅使用 DP。
如公式 6 所示,如果从 MP 中得到的加速足够大,可以克服不断上涨的通信、同步开销,以及全局批大小带来的扩展性能和统计效率损失,那么使用结合 MP 和 DP 的混合策略将有效地改善网络训练时间。
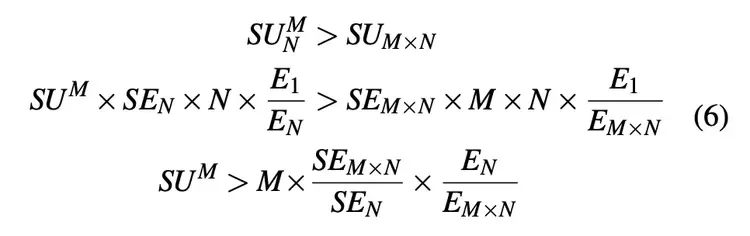
图 3 使用假设情景说明了这一概念。
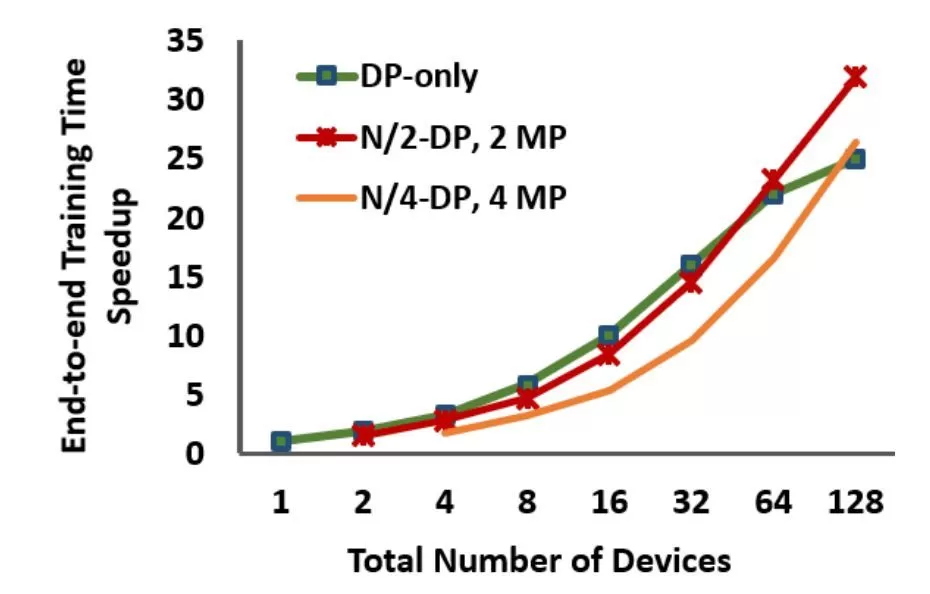
图 3:该示例图展示了仅使用 DP 获得的加速和使用混合策略获得的加速。N 指模型训练所用设备总数。
评估
研究者对 Inception-V3、GNMT 和 BigLSTM 模型进行了评估。下图 4 展示了获得预期准确率所需的 epoch 数量与数据并行训练中使用 GPU 数量的关系,epoch 数量通常会随着 GPU 数量的增加(即全局批大小增大)而增长。
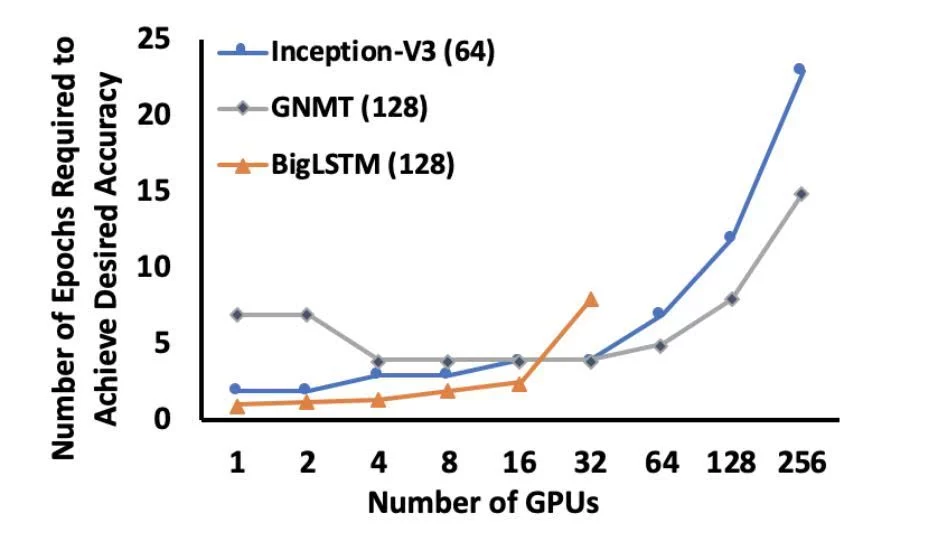
图 4:网络收敛所需 epoch 数量 vs 不断增加的全局批大小和 GPU 数量。研究者使用 4.2 部分介绍的技术模拟大量 GPU 所对应的大规模全局批大小。
使用模型并行化在两个 GPU 上分割每个网络可能带来每个时间步的加速。下表 1 展示了三种网络在测试系统上的 MP 加速。
使用训练所需 epoch 数和从 MP 得到的每个时间步加速,再加上对扩展效率的保守估计,就可以计算出在不同数量的 GPU 上使用混合并行化策略所获得的最小加速(相比于仅使用 DP 的并行化策略)。
值得注意的是,使用专家手动布局操作的 Inception-V3 实现了 21% 的 MP 加速。而使用研究者开发的 DLPlacer 工具后,该模型可实现 32% 的 MP 加速。

表 1:MP 分割策略和在 2 个 GPU 上实施分割策略时获得的加速。
下图 5 展示了 Inception-V3、GNMT 和 BigLSTM 模型在使用混合并行化策略和 DP 策略时的加速对比结果。从图中我们可以看出,当统计效率损失降低了 DP 策略的有效性时,混合并行化策略可以保持更高的性能。
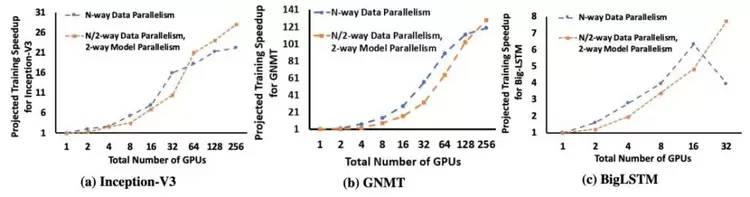
图 5:混合并行化策略 vs DP 策略的加速对比。
如何才能最大化 MP 性能?DLPlacer!
对给定模型最大化 MP 加速可以提升混合并行化策略的可扩展性。对于一些网络,通过检查网络的数据流图(DFG)即可轻松实现最优布局。而对于另外一些网络来说,找出能够带来最大每时间步加速的最优 operation-to-device 布局并不容易。
为此,该研究开发了一种基于整数线性规划 (ILP) 的设备布局工具——DLPlacer。该工具可以通过提取模型中不同操作之间的并行化来实现资源最大化利用,同时最小化计算节点间移动数据的通信开销。
下图 6 展示了 DLPlacer 工具的工作流程:
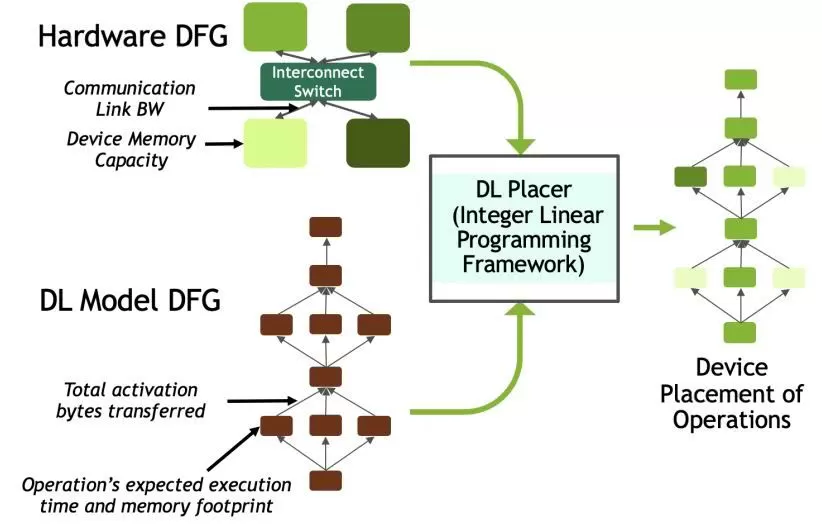
图 6:DLPLacer 工作流程图。
案例研究:Inception-V3
下图 8 中蓝条表示 DLPlacer 估计的每时间步 MP 加速(经过正则化处理),橙条表示按照 DLPlacer 找到的最优布局在真实芯片上进行 Tensorflow 实现后获得的加速。DLPlacer 估计的加速在实际加速的上下 6% 区间范围内。
值得注意的是,在 2 个 GPU 的设置下,真实实验获得的加速(1.32 倍)与在三或四个 GPU 上获得的加速几乎一样。其原因在于该网络可进行的并行化有限,DLPlacer 在 2 个 GPU 的情况下几乎完全穷尽了并行化。
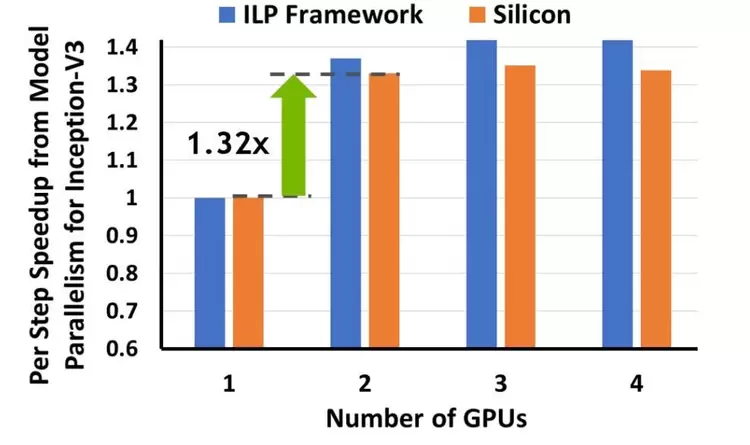
图 8:DLPlacer 估计的每时间步 MP 加速(经过归一化处理)vs 真实实验中得到的每时间步 MP 加速。
相关文章
- 中兴通讯全面助力《北京数据标准化白皮书》发布,筑牢首都数字经济“标准底座”
- 六大行业领先,电科金仓入选2026中国数据库产业图谱
- 四维图新数据合规闭环服务获A+ Awards新质生产力领航奖
- 秦淮数据CEO吴华鹏: 从IDC到“Token工厂”,AI时代的算力底层逻辑正在重塑
- 刘东:数据空间成为AI时代关键基础设施
- 融合7万小时具身数据,蚂蚁灵波开源具身视频基础模型LingBot-Video
- 2026中国信息通信业发展高层论坛 网络安全与数据安全实践分论坛成功举办
- 博士生的数据噩梦:实验数据管理贯穿科研全生命周期
- 勤哲Excel服务器:助力企业实现数据协同与流程一体化管理
- 数据“浓缩铀”是怎样炼成的 ——专利数据里的高质量数据集建设密码
- “凭感觉”和“看报表”都不够,钛动科技用“创意×数据”打通出海增长双引擎
- 2026全球数字经济大会数据要素发展论坛举办,北京数据集团发布“京算Token工厂”
- 科华数据AI算力基建再落关键一子丨山河湾谷智算中心正式揭牌!
- AI+大数据重塑外贸营销,宜选科技构建全球智能获客新优势
- 勤哲Excel服务器:以数据协同提升运营效率,赋能外贸制造企业数字化转型
- 氧橙携手光粒发布全球首款团队游泳数据监测AR泳镜,开启水上训练数字化新时代
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


