极链科技张奕:商业化视频内容识别的算法设计与应用
2019-12-20 14:34:55AI云资讯1153
当前,商业化视频包括长视频、短视频、直播等多种类型,其中蕴含着海量的信息和巨大的潜在商业价值。如何运用GPU的强大算力,设计人工智能算法,对商业化视频中的内容语义进行分析识别,生成结构化数据,同时受到了学术界和工业界的重视。
近日,极链科技Video++AI研究院负责人张奕在英伟达GTC 2019上,带来了「商业化视频内容识别的算法设计与应用」的精彩演讲。从视联网的产业介绍、智能视频技术应用于商业化视频的挑战、数据的重要性与VideoNet视频数据集、商业化视频内容识别算法设计与视联网应用五大模块进行了分享。

5G+AI时代 互联网形态进化
在5G和AI的加持下,互联网演进出三大形态,物联网,视联网和车联网。目前视频占据了全网数据的80%,且仍在不断提高。视频将成为互联网最重要的入口,承担起信息传递介质和互联网功能载体的作用,进而形成以视频作为主要信息传递介质和功能载体的互联网形态,视联网。庞大的消费级视频是视联网的首个落地场景。
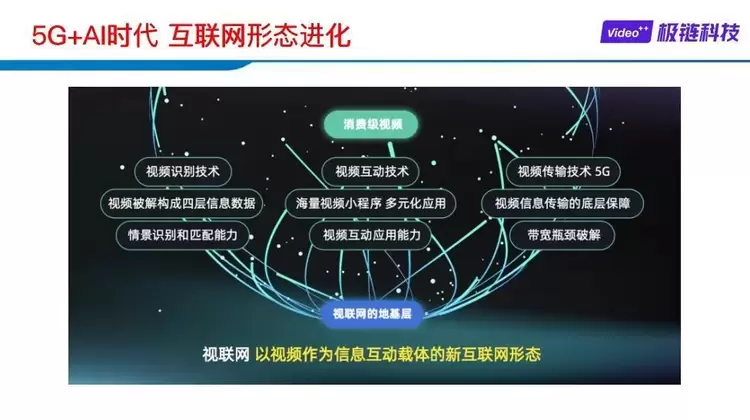
张奕介绍道,作为「AI+视频」行业独角兽企业,全球视联网-视频商业操作系统构建者,极链科技专注于消费级视频AI技术研发和商业应用,聚焦以视频作为信息和功能核心载体的新互联网形态——视联网。以AI技术赋能视频中的信息,链接互联网信息、服务、购物、社交、游戏五大模式,实现基于视频的新互联网经济体。极链科技自主研发的VideoAI是视联网整个生态的底层数据引擎,支撑视联网的多维度发展。顽石OS作为视联网操作系统,是整个视联网生态的承载,提供高效个性化的互动视频应用,扭转了视频只能单向输出的状态。为用户提供了全新的观看体验,实现了视频与用户的双向互动,让视频成为连接服务与用户的高价值流量入口。
商业化视频内容识别的挑战
视联网的基础数据即视频,尤其是消费级视频。区别于工业级视频是利用专业设备在固定条件、固定场景下拍摄的视频,如监控视频。商业化视频是指用户用手机等便携式图像采集设备生成的视频。商业化视频有三大特点。一、商业化视频数据体量巨大;二、商业化视频的类别多样,如电影、综艺、体育、短视频等;三、商业化视频场景复杂,如场景内的特效、切换、淡入淡出和字幕,都会对整体或局部产生模糊。以上特点对视频识别算法提出了更高的挑战。
视频识别算法本身有较长的历史,然而受到计算能力的限制,算法各项性能与产品商业化要求间还存在较大的差距。直到2012年,深度学习技术、大数据及GPU算力的结合极大提升了算法准确率和运算效率,拉低了与产品商业化要求的差距。
数据的重要性与VideoNet视频数据集

众所周知,深度学习的成功建立在大规模数据集的基础上。现有视频数据集从规模、维度和标注方式上都与深度学习算法的要求存在很大差距。今年,极链科技与复旦大学联合推出了全新的VideoNet视频数据集,具备规模大、多维度标注、标注细三大特点。
第一,规模大。VideoNet数据集包含逾9万段视频,总时长达4000余小时。
第二,多维度标注。视频中存在着大量的物体、场景等多维度内容信息,这些维度内容之间又存在着广泛的语义联系。近年来涌现出大量针对物体、场景、人脸等维度的识别技术,在各自的目标维度上取得了明显的进步。但各视频识别算法基本针对单一维度来设计的,无法利用各维度之间存在的丰富的语义关联建立模型,提高识别准确度。VideoNet数据集从事件、物体、场景三个维度进行了联合标注,为多维度视频识别算法研提供支持。
第三,标注细。视频标注工作量非常巨大,当前大部分视频仅针对整段视频打标签。而VideoNet数据集对视频进行了事件分类标注,并针对每个镜头的关键帧进行了场景和物体两个维度的共同标注,充分体现了多维度内容之间的语义联系。
那么,VideoNet数据集是如何进行标注的?首先,对视频数据进行预处理,即镜头分割,并根据清晰度对镜头单元进行关键帧提取。之后从三个维度进行视频标注,事件维度上对整个视频标注类别标签,物体维度上对镜头关键帧标注类别和位置框,场景维度上对镜头关键帧标注类别标签。目前,VideoNet数据集包含353类事件,超过200类场景和200类物体,总视频数达到9万。其中60%作为训练集,20%作为验证集,20%作为测试集。
自6月18日「VideoNet视频内容识别挑战赛」公布训练和验证数据集以来,截止到8月12日,注册报名的队伍已超过360支,其中参赛队伍当中有来自中科院、北京大学、中国科学技术大学等顶尖高校队伍以及来自阿里巴巴、京东、华为、腾讯、大华等众多知名企业队伍。预计明年,极链科技将会继续增加VideoNet数据集的规模和标注维度。
商业化视频内容识别的算法设计
商业化视频的数据特点,对算法系统的处理速度、效率和准确率提出了较高的要求。商业化视频算法的总体框架分为五层:1、视频输入层进行视频源的管理;2、视频处理层进行镜头分割、采样、增强和去噪等工作;3、内容提取层主要分析视频中内容、语义等信息,进行目标检测、跟踪和识别等来检测目标在视频中的时间、空间、位置等维度;4、语义融合层进行目标轨迹融合、识别结果融合、特征表示融合、高层语义融合等;5、在数据输出层,进行结构化数据管理,方便后续数据检索与应用。
视频内容识别维度多样,包括场景、物体、人脸、地标、Logo、情绪、动作、声音等。不同维度的算法结构有所区别。人脸识别算法结构为:输入视频后进行镜头分割,在进行人脸检测、跟踪、人脸对齐,根据质量评估过滤,进行特征提取和特征比对识别,最后进行识别结果融合,输入最终识别结果。

在场景识别算法结构中,首先对输入视频进行镜头分割采样,有所不同的是只需进行时间间隔分割的采样,再对视频进行场景类别的初分类,预处理之后进入卷积神经网合阶段,卷积神经网络通过对不同的数据集进行预训练,得到不同的特征和描述,将这些特征进行融合、降维处理得到特征表示后,对不同场景如高频场景、次级场景和新增场景,进行分类处理,最终对识别结果进行融合。
在物体、Logo识别算法结构中,有所不同的是需要多尺度提取特征,跟踪识别物体轨迹,并关注物体类别,对结果进行优化。
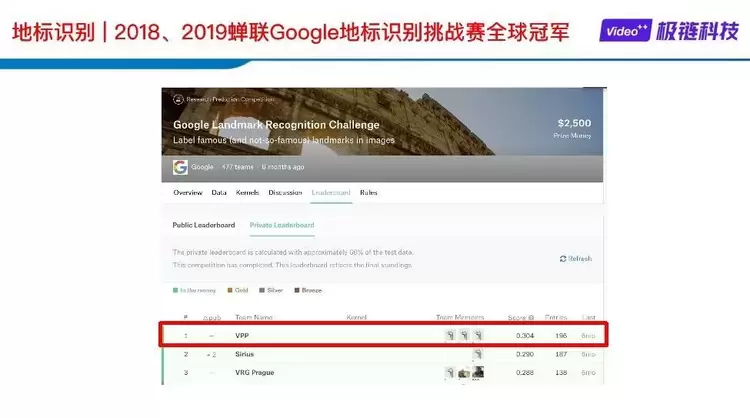
在地标识别算法结构中,分为三步,第一,通过基础网络(VGG,ResNet等)获得特征图(一般为最后一层卷积或池化层);第二,从特征图中提取特征(例如R-Mac,SPoC,CroW,GeM等)并用ROI Pooling,PCA 白化,L2-归一化等方式处理,一般最终维度为256,512,1024,或2048;用kNN,MR,DBA,QE,Diffusion等方式将得到的特征对数据库内的特征进行后处理获得最终特征;训练模型一般损失函数采用contrastive loss或triplet loss,最终比对一般采用余弦或欧式距离。
极链科技自主研发的算法主要做了以下优化:1. 对基础网络进行多层的特征提取(而不局限于全连接的前一层)并融合,降维等。2. 采用CroW算法的核心思想对特征图的不同空间点以及channel增加权重,不同于CroW算法,我们的权重是通过端到端方式学习所获得。在2018、2019年Google地标识别挑战赛中,极链科技AI研究院蝉联了两届全球冠军。
随后,张奕介绍了视频检索,也就是以图搜视频的流程。以图搜视频可以分为两部分,一部分是通过视频深度图像检索构建视频数据库,另一部分是用户检索时,输入图像到第一部分的视频库中进行检索。
具体来看,首先通过视频下载、视频数据库检索、特征提取、特征排序等生成一个特征表述数据库,当用户需求输入后进行特征提取、比对、排序和结构展示。这是标准的检索流程。在算法结构方面,用户输入后会经过卷积神经网络和索引得出粗检索结果,再通过细检索进行排序、查询,最后输出镜头信息,另外也可以通过剧目信息进行子部检索减少搜索任务的压力,同时提高算法的准确率。
以图搜视频的核心在于我们自研的深度图像检索模型VDIR,由视频任务调度系统派发的视频分片,经过镜头检测分割成片段,片段信息经过VDIR会生成视频信息库、视频特征库以及哈希索引库。用户输入一张或者多张图像,同时可以指定剧目信息,比如古装剧、玄幻剧等,输入的图像经过VDIR算法提取到哈希编码和特征,首先会去历史检索库中查找是否有相似的检索,如果有直接使用特征即进行细匹配,没有就会先通过哈希编码到哈希索引库中检索,然后进行细匹配,根据匹配相似度进行排序后,从视频信息库中查询到视频片段信息,配合截图输出到界面。
深度图像检索模型VDIR会输出两部分内容,分别是用于快速检索的哈希编码以及用来细匹配的特征,一个片段的几个帧特征或者相邻片段的帧特征并不是都需要,因为我们设计关键帧筛选逻辑,只保留关键帧特征。
为了将以上算法实际落地,张奕认为还需要进行工程化的工作。在工程化工作中,需要解决以下几个问题:1、算法进行并行化加速其运营;2、面对高并发状态解决分布式系统和多任务调度的问题;3、对资源调度进行算法分割与CPU+GPU配比;4、对高优先级任务规划处理策略。
视频内容识别的视联网应用
演讲最后,张奕向大家介绍了三个算法实际产业化应用的案例。
VideoAI视频智能识别和大数据运营系统,实现视频输入、识别、结构化数据管理和多维度检索全流程技术。极链科技独创独创全序列采样识别,对视频内的场景、物体、人脸、品牌、表情、动作、地标、事件8大维度进行数据结构化,32轨迹流同时追踪,通过复合推荐算法将内容元素信息升级为情景信息,直接赋能各种视联网商业化场景。

灵悦AI广告平台,通过VideoAI将全网海量视频进行结构化分析,对消费场景标签化,结合品牌投放需求,提供智能化投放策略和批量化投放,让用户在观看视频时有效获取相关品牌信息及购买,实现广告主精准投放的营销目的和效果。目前通过VideoAI技术的赋能,灵悦AI广告平台已完成2012年至今全网热门视频,实现扫描累计时长达15,600,000+分钟剧目复合双向匹配。开发了965类成熟商业化可投放情景,服务300+百家一线品牌,并与全网头部流量视频平台签订深度投放合作,实现广告创新营销的新动能。
神眼系统,广电级内容安全多模AI审核系统,可实现本地部署的高可用技术解决方案,提供长视频、直播、短视频的敏感、政治、色情、暴恐审核服务。产品核心功能包括:智能鉴黄(识别视频和图片中的色情、裸露、性感等画面);智能鉴暴(识别视频和图片中的血腥、暴力、枪支等画面);政治敏感人物识别(基于政治人物库,识别视频和图片中的国家领导人物或者落马官员等);涉毒/涉政明星识别(基于明星库,结合黑名单,识别视频和图片中的涉毒、涉政等明星)。
最后,张奕强调了数据对于人工智能发展的重要性。他认为目前半监督、无监督算法还处于研究阶段,性能差距较大,所用AI算法大多基于监督学习,因此数据的体量和质量非常重要。学会思考更多问题,例如采集数据与实际应用间的相关度,常规数据操作有哪些,如何获取“高效”的数据,如何应用数据管理工具,才能让我们更好的管理、应用数据等。
相关文章
- 微算法科技(NASDAQ :MLGO)面向区块链的系统的高效反量子晶格盲签名技术
- 把尾货卖到50亿,好特卖靠AI算法,拿捏情绪经济
- MLGO微算法科技分布式量子算法模拟技术:以动态量子电路推动可扩展量子计算
- 展会数字营销的数据算法黑盒:拆解从裂变系数到ROI归因的实战方法论
- 微算法科技(NASDAQ:MLGO)量子PBFT改进技术:重构联盟链共识的效率与安全
- 算法之外:钛动科技如何用“真实场景”叩开社交软件出海的心门
- 好特卖超级仓加速落地,算法驱动供应链升级支撑大店模式
- 智造“医”线:从精密自动化到AI算法定义,电子制造技术如何为智慧医疗筑基?
- MLGO微算法科技推出全球首个量子比特高效线性微分方程求解算法
- 微云全息(NASDAQ:HOLO) HPDC 算法:重塑 AI 算力生态的分布式革新
- 微算法科技(NASDAQ: MLGO)使用量子傅里叶变换(QFT),增强图像压缩和滤波效率
- 微算法科技(NASDAQ: MLGO)基于量子技术的区块链架构:量子原生验证模型与分布式账本革新
- 以数据与算法双轮驱动的垂直AI 2025年赢得12000家客户信赖
- 极智嘉发布全新RMS调度系统:智能算法自学习,安全易用双突破
- 马斯克表示X平台即将开源新的算法
- 终端数据+算法 玄瞳AI赋能地方区域产业升级的路径与价值
人工智能企业
更多>>




人工智能硬件
更多>>- BOE(京东方)OLED技术赋能联想YOGA Air 14 Ultra 定义超轻薄AI PC新标杆
- iQOO 15T正式发布:天玑9500 Monster版加持 全能体验无短板
- 从“+AI”到“AI+”:天禧AI 4.0加持,联想AI主机领衔L3级终端震撼登场
- 拾年匠音,声来不凡,致敬1000X系列十周年 索尼发布1000X十周年典藏版头戴降噪耳机
- 出游露营正当时 三星Galaxy手机全方位守护你的户外体验
- 拯救者Y900系列生产力大屏AI平板正式发布,学娱场景随心换,打造新一代旗舰终端
- 智慧陪伴 定格浪漫 三星Galaxy A57 5G让你的520心意满分
- 短途出行机器人QUORRA X5出海订单覆盖欧美,头部资本加持正奇未来布局全球
人工智能产业
更多>>人工智能技术
更多>>- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代
- 基石智算上线 MiniMax M2.5,超强编程与智能体工具调用能力
- 昇腾原生支持,科学多模态大模型Intern-S1-Pro正式发布并开源


