谷歌使用AI追踪2D视频中的物体 或可用于自动驾驶汽车物体识别
2020-04-02 11:50:06AI云资讯1085
(图片来源:ai.googleblog.com)
追踪3D物体是一项复杂的工作,特别是当计算资源有限时。当仅有的可用图像为2D时,由于缺乏数据以及物体外观和形状多种多样,这会变得更加困难。
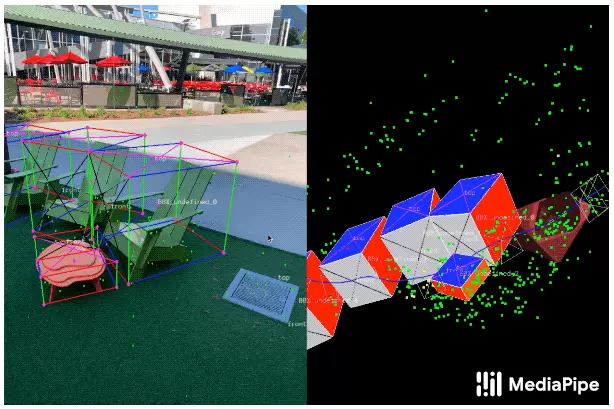
为此,Objectron研发团队开发了一种工具,可以使注释器通过分屏视角显示2D视频帧,来标记物体的3D边界框(即矩形边框)。这些3D边界框将叠加在点云数据、摄像头位置和识别到的平面上。注释器在3D视图中绘制3D边界框后,再通过查看2D视频帧中的投影来验证其位置。而对于静态物体,注释器只需在单个帧中标记目标物体象即可。该工具还使用AR会话数据中的实际摄像头姿态信息,将物体的位置传输到所有帧。

(图片来源:ai.googleblog.com)
为了补充真实世界的数据,以提高AI模型预测的准确性,该团队开发了一个引擎,将虚拟物体放入包含AR会话数据的场景中。这允许使用相机姿态信息、检测到的平面,以及估算的照明,生成物理上可能的、并具有与场景匹配的照明的位置,从而产生高质量的合成数据,其中的渲染物体符合场景的几何形状,并无缝融入真实背景。在验证试验中,合成数据的运用使AI模型预测准确性提高了约10%。
此外,该团队表示,当前版本的Objectron模型足够轻巧,可以在旗舰移动设备上实时运行。借助LG V60 ThinQ,三星Galaxy S20 +和Sony Xperia 1 II等手机中的Adreno 650移动图形芯片,该模型能够每秒处理约26帧。
Objectron在MediaPipe中可用,MediaPipe是一个框架,用于构建跨平台的AI管道,该管道包括快速推理和媒体处理(如视频解码)。提供训练有素的识别鞋子和椅子的模型,以及端到端演示应用程序。
该团队表示,未来计划与研发社区共享其他解决方案,以刺激新的用例、应用和研究工作。此外,该团队打算将Objectron模型进行扩展,以识别更多类别的物体,并进一步提高其在设备中的性能。
相关文章
- 谷歌投资A24,共同开发人工智能电影制作工具
- 数据中心耗电远超电网负荷,迫使英伟达与谷歌在2026年第三季度前启动800V直流电架构改造
- 苹果和谷歌新增对Thread 1.4的支持
- 宜选科技出席2026谷歌合作伙伴峰会
- 苹果在新版Siri上作出妥协:依靠英伟达B200 GPU加密技术,防止谷歌窃取用户数据
- 谷歌Beam抢滩多人会议全息赛道,微美全息以AI+5G解锁虚实融合视觉新想象
- Google I/O 2026亮点回顾:晶晨股份携手谷歌共拓端侧AI新生态
- 谷歌搜索的人工智能进化包含更多广告
- 谷歌的未来是一个无所不能的搜索框
- Google I/O 2026:Gemini 将成为谷歌年度开发者大会的主角
- 2026智能眼镜“百镜争鸣”,谷歌/阿里/微美全息引领AR/XR产业全面升级
- 谷歌发布 Chromebook 后继产品——Googlebook
- 谷歌称其首次发现并阻止了一个利用AI开发的零日漏洞
- 谷歌首款AI眼镜即将呼之欲出,微美全息(WIMI.US)扎实推进AI+AR生态落地
- 谷歌母公司发布2026年一季度财报,搜索查询量创下历史新高
- 英伟达Rubin芯片落地谷歌A5X实例,多站点集群规模扩展至近百万颗GPU
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


