历经6年,AI在这一技能上得分首超人类
2021-08-12 13:56:02AI云资讯777
8月12日,记者注意到,国际权威机器视觉问答榜单VQALeaderboard出现关键突破:阿里巴巴达摩院以81.26%的准确率创造了新纪录,让AI在“读图会意”上首次超越人类基准。继2015年、2018年AI分别在视觉识别及文本理解领域超越人类分数后,人工智能在多模态技术领域也迎来一大进展。
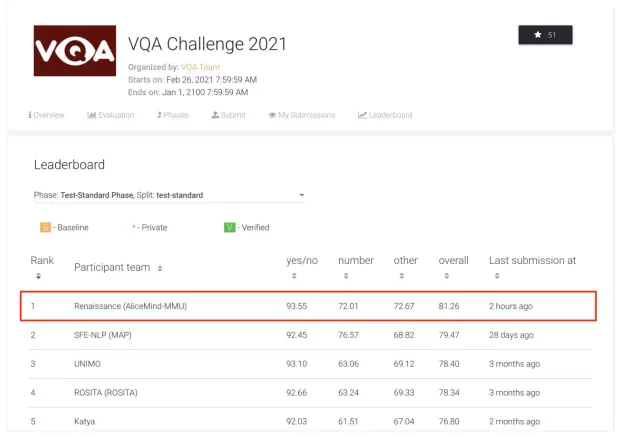
(达摩院AliceMind在VQALeaderboard上创造首次超越人类的纪录)
“诗是无形画,画是有形诗。”宋代诗人张舜民曾描绘语言与视觉的相通之处。“读图会意”,即通过视觉理解信息,是人类的一项基础能力,但对AI来说却是要求极高的认知任务。解决该挑战,对研发通用人工智能有重要意义。近10年来,AI在下棋、视觉、文本理解等单模态技能上突飞猛进,但在涉及视觉-文本跨模态理解的高阶认知任务上,AI过去始终未达到人类水平。
为攻克这一难题而设立的挑战赛VQAChallenge,自2015年起先后于全球计算机视觉顶会ICCV及CVPR举办,吸引了包括微软、Facebook、斯坦福大学、阿里巴巴、百度等众多顶尖机构踊跃参与,并形成了国际上规模最大、认可度最高的VQA(Visual Question Answering)数据集,其包含超20万张真实照片、110万道考题。
VQA是AI领域难度最高的挑战之一。在测试中,AI需根据给定图片及自然语言问题生成正确的自然语言回答。这意味着单个AI模型需融合复杂的计算机视觉及自然语言技术:首先对所有图像信息进行扫描,再结合对文本问题的理解,利用多模态技术学习图文的关联性、精准定位相关图像信息,最后根据常识及推理回答问题。
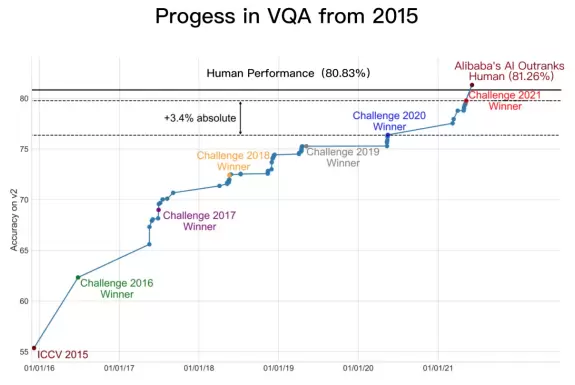
(VQA技术自2015年的进展)
今年6月,阿里达摩院在VQA 2021 Challenge的55支提交队伍中夺冠,成绩领先第二名约1个百分点、去年冠军3.4个百分点。两个月后,达摩院再次以81.26%的准确率创造VQALeaderboard全球纪录,首次超越人类基准线80.83%。
VQA的核心难点在于对多模态信息进行联合推理认知,即在统一模型里做不同模态的语义映射和对齐。据了解,达摩院NLP及视觉团队对AI视觉-文本推理体系进行了系统性的设计,融合了大量算法创新,包括多样性的视觉特征表示、多模态预训练模型、自适应的跨模态语义融合和对齐技术、知识驱动的多技能AI集成等,让AI“读图会意”水平上了一个新台阶。
VQA技术拥有广阔的应用场景,可用于图文阅读、跨模态搜索、盲人视觉问答、医疗问诊、智能驾驶等领域,或将变革人机交互方式。
报道显示,这不是阿里达摩院第一次在AI关键领域超越人类基准。2018年,达摩院曾在斯坦福SQuAD挑战赛中历史性地让机器阅读理解首次超越人类,引发海外媒体关注。今年以来,达摩院在AI底层技术领域动作频频,先后发布了中国科技公司中首个超大规模多模态预训练模型M6及首个超大规模中文语言模型PLUG,并开源了历经3年打造的深度语言模型体系 AliceMind(https://github.com/alibaba/AliceMind),其曾登顶 GLUE等六大国际权威NLP榜单。

(VQA考题列举,根据有礼服装饰的小熊玩具照片及问题“这些玩具用来做什么的?”达摩院AliceMind成功推理出一个可能的答案“婚礼”)
相关文章
- 阳台储能开创者疆海科技完成数亿元 B 轮融资,押注 AI 时代的家庭能源中心
- 开源!鲸智百应升级,浩鲸科技重新定义企业AI原生
- 万兆AI惠商 联通美好未来 ——中国联通东莞市分公司5・17 电信日暨联通客户日活动圆满举行
- 中国联通在北京地区携手华为发布3000M宽带新产品,全光臻宽带矩阵为“双万兆AI提质行动”添砖加瓦
- 超显商城整合核心GLED显示技术,开启显示设备AI定制新模式
- 博大数据荣膺“全球AI生态基石大奖”,夯实融合算力基础设施服务商领先地位
- 全国人工智能发展大会 AI HANGZHOU 2026中国(杭州)国际人工智能展览会
- 酷开发布企业AI操作系统 开启硅基管理新时代
- 酷开AIOS:定义“企业AI操作系统”的野心与挑战
- 华为超千兆新品亮相山西!三频Wi-Fi 7+AI 焕新智慧家庭新生活
- 辽宁与华为联合发布超千兆三频Wi-Fi 7+AI 新品,共筑辽沈智慧家庭新生活
- 亿达科创亮相国际人工智能展再获AI大奖
- 花旗银行报告称,台积电在AI领域的主导地位不会受到英特尔威胁
- 华为云创想者大会主题论坛议程公布:释放Agentic AI新布局
- 与AI同行 3000M助力 共创智家新生活——中国联通品牌与产品辽宁宣传推广会 全面启动联通社区惠民行系列行动
- 以创新设计重塑 AI 路由未来,MOVA LINCO X1 Pro 荣膺红点奖
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠
- Seedance 2.0面向企业公测,豆包大模型日均Token使用量突破120万亿
- 端到端OCR模型第一!百度千帆Qianfan-OCR正式发布
- 云知声Unisound U1-OCR大模型发布!首个工业级文档智能基础大模型,开启OCR 3.0时代


