百分点科技:声纹识别技术发展及未来趋势研究
2022/01/14 12:00AI云资讯11260
近年来,许多智能语音技术服务商开始布局声纹识别领域,声纹识别逐渐进入大众视野。随着技术的发展和在产业内的不断渗透,声纹识别的市场占比也逐年上升,但目前声纹识别需要解决的关键问题还有很多。本文中,百分点感知智能实验室梳理了声纹识别技术的发展历史,并分析了每一阶段的关键技术原理,以及遇到的困难与挑战,希望能够让大家对声纹识别技术有进一步了解。
声纹(Voiceprint),是用电声学仪器显示的携带言语信息的声波频谱。人类语言的产生是人体语言中枢与发音器官之间一个复杂的生理物理过程,不同的人在讲话时使用的发声器官(舌、牙齿、喉头、肺、鼻腔)在尺寸和形态方面有着很大的差异,所以任何两个人的声纹图谱都是不同的。
每个人的语音声学特征既有相对稳定性,又有变异性,不是绝对的、一成不变的。这种变异可来自生理、病理、心理、模拟、伪装,也与环境干扰有关。
尽管如此,由于每个人的发音器官都不尽相同,因此在一般情况下,人们仍能区别不同的人的声音或判断是否是同一人的声音。因此声纹也就成为一种鉴别说话人身份的识别手段。
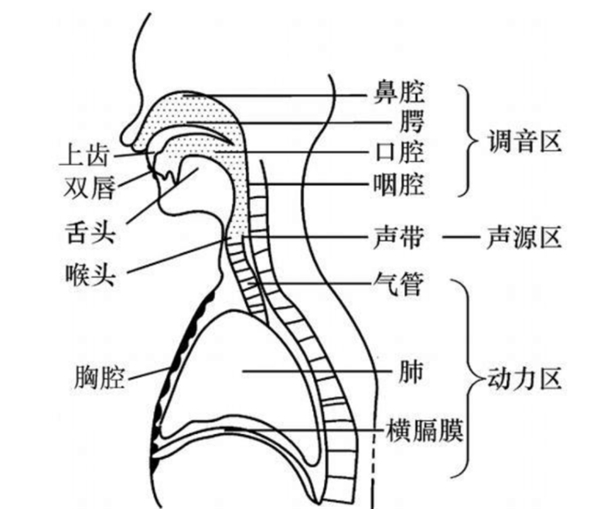
图一 发声器官示意图
所谓声纹识别,是生物识别技术的一种,也叫做说话人识别,是一项根据语音波形中反映说话人生理和行为特征的语音参数,自动识别语音说话者身份的技术。首先需要对发音人进行注册,即输入发音人的一段说话音频,系统提取特征后存入模型库中,然后输入待识别音频,系统提取特征后经过比对打分从而判断所输入音频中说话人的身份。
从功能上来讲,声纹识别技术应有两类,分别为“1:N”和“1:1”。前者是判断某段音频是若干人中的哪一个人所说;后者则是确认某段音频是否为某个人所说。因此不同的功能适用于不同的应用领域,比如公安领域中重点人员布控、侦查破案、反电信欺诈、治安防控、司法鉴定等经常用到的是“1:N”功能,即辨认音频若干人中的哪一个人所说;而“1:1”功能则更多应用于金融领域的交易确认、账户登录、身份核验等。
从技术发展角度来说,声纹识别技术经历了三个大阶段:
第一阶段,基于模板匹配的声纹识别技术;
第二阶段,基于统计机器学习的声纹识别技术;
第三阶段,基于深度学习框架的声纹识别技术。
一、模板匹配的声纹识别
下图是最早的声纹识别技术框架,是一种非参数模型。
特点:基于信号比对差别,通常要求注册和待识别的说话内容相同,属于文本相关,因此局限性很强。

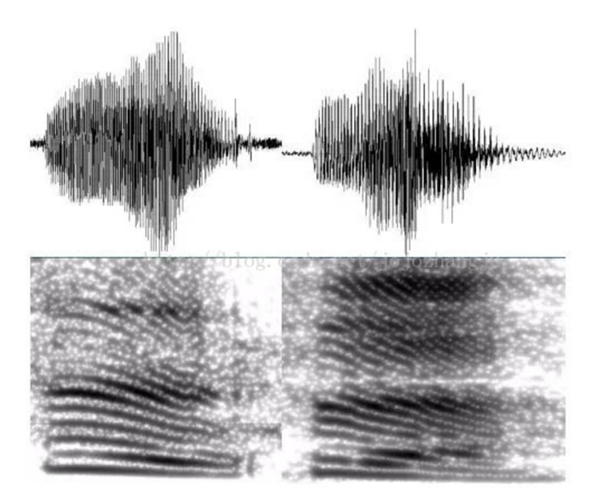
图二 两人对于同一数字发音与谱图
此方法将训练特征参数和测试的特征参数进行比较,两者之间的失真(Distortion)作为相似度。例如VQ(Vector Quantization矢量量化)模型和动态时间规整法DTW(Dynamic Time Warping)模型。
DTW 通过将输入待识别的特征矢量序列与训练时提取的特征矢量进行比较,通过最优路径匹配的方法来进行识别。而VQ 方法则是通过聚类、量化的方法生成码本,识别时对测试数据进行量化编码,以失真度的大小作为判决的标准。
二、基于统计机器学习的技术框架
但由于第一阶段只能用于文本相关的识别,即注册语音的内容需要跟识别语音内容一致,因此具有很强的局限性,同时受益于统计机器学习的快速发展,声纹识别技术也迎来了第二阶段。此阶段可细分为四个小阶段,即GMM > GMM-UBM/GMM-SVM > JFA > GMM-iVector-PLDA。
1. 高斯混合模型(GMM)
特点:采用大量数据为每个说话人训练(注册)模型。注册要求很长的有效说话人语音。
高斯混合模型(Gaussian Mixture Model, GMM)是统计学中一个极为重要的模型,其中机器学习、计算机视觉和语音识别等领域均有广泛的应用,甚至可以算是神经网络和深度学习普及之前的主流模型。
GMM之所以强大,在于其能够通过对多个简单的正态分布进行加权平均,从而用较少的参数模拟出十分复杂的概率分布。
在声纹识别领域,高斯混合模型的核心设定是:将每个说话人的音频特征用一个高斯混合模型来表示。采用高斯混合模型的动机也可以直观的理解为:每个说话人的声纹特征可以分解为一系列简单的子概率分布,例如发出的某个音节的概率、该音节的频率分布等。这些简单的概率分布可以近似的认为是正态分布(高斯分布)。但是由于GMM规模越庞大,表征力越强,其负面效应也会越明显:参数规模也会等比例膨胀,需要更多的数据来驱动GMM的参数训练才能得到一个更加通用(或泛化)的GMM模型。
假设对维度为50的声学特征进行建模,GMM包含1024个高斯分量,并简化多维高斯的协方差为对角矩阵,则一个GMM待估参数总量为1024(高斯分量的总权重数)+1024×50(高斯分量的总均值数)+1024×50(高斯分量的总方差数)=103424,超过10万个参数需要估计。
这种规模的变量就算是将目标用户的训练数据量增大到几个小时,都远远无法满足GMM的充分训练要求,而数据量的稀缺又容易让GMM陷入到一个过拟合(Over-fitting)的陷阱中,导致泛化能力急剧衰退。因此,尽管一开始GMM在小规模的文本无关数据集合上表现出了超越传统技术框架的性能,但它却远远无法满足实际场景下的需求。
2. 高斯混合背景模型(GMM-UBM)和支持向量机(GMM-SVM)
特点:使用适应模型的方法减少建模注册所需要的有效语音数据量,但对跨信道分辨能力不强。
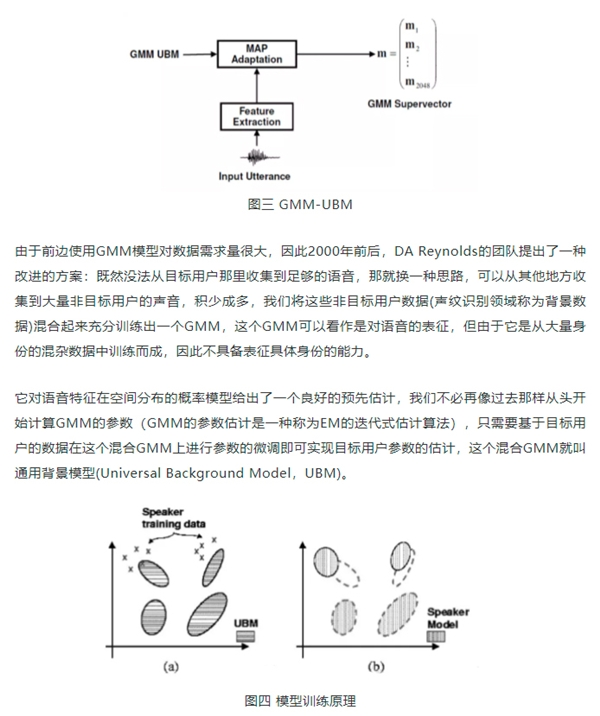
UBM的一个重要优势在于它是通过最大后验估计(Maximum A Posterior,MAP)的算法对模型参数进行估计,避免了过拟合的发生。MAP算法的另外一个优势是我们不必再去调整目标用户GMM的所有参数(权重、均值、方差),只需要对各个高斯成分的均值参数进行估计,就能实现最好的识别性能。这样待估的参数一下减少了一半多(103424 -> 51200),越少的参数也意味着更快的收敛,不需要那么多的目标用户数据即可完成对模型的良好训练。
GMM-UBM系统框架,是GMM模型的一个推广,是用于解决当前目标说话人数据量不够的问题的一种方式。通过收集其他说话人数据来进行一个预先的训练。通过MAP算法的自适应,将预先训练过的模型向目标说话人模型进行微调。这种方式可以大大减少训练所需要的样本量和训练时间(通过减少训练参数)。
但是GMM-UBM缺乏对应于信道多变性的补偿能力,因此后来WM Campbell将支持向量机(Support Vector Machine,SVM)引入了GMM-UBM的建模中,通过将GMM每个高斯分量的均值单独拎出来,构建一个高斯超向量(Gaussian SuperVector,GSV)作为SVM的样本,利用SVM核函数的强大非线性分类能力,在原始GMM-UBM的基础上大幅提升了识别的性能,同时基于GSV的一些规整算法,例如扰动属性投影(Nuisance Attribute Projection, NAP),类内方差规整(Within Class Covariance Normalization,WCCN)等,都在一定程度上补偿了由于信道易变形对声纹建模带来的影响。
3. 联合因子分析法(JFA)
特点:分别建模说话人空间、信道空间以及残差噪声,但每一步都会引入误差。
在传统的基于GMM-UBM的识别系统中,由于训练环境和测试环境的失配问题,导致系统性能不稳定。于是Patrick Kenny在05年左右提出了一个设想:既然声纹信息可以用一个低秩的超向量子空间来表示,那噪声和其他信道效应是不是也能用一个不相关的超向量子空间进行表达呢?
基于这个假设,Kenny提出了联合因子分析(Joint Factor Analysis,JFA)的理论分析框架,将说话人所处的空间和信道所处的空间做了独立不相关的假设,在JFA的假设下,与声纹相关的信息全部可以由特征音空间(Eigenvoice)进行表达,并且同一个说话人的多段语音在这个特征音空间上都能得到相同的参数映射,之所以实际的GMM模型参数有差异,这个差异信息是由说话人差异和信道差异这两个不可观测的部分组成的公式如下:
M=s+c
其中,s为说话人相关的超矢量,表示说话人之间的差异;c为信道相关的超矢量,表示同一个说话人不同语音段的差异;M为GMM均值超矢量,表述为说话人相关部分s和信道相关部分c的叠加。
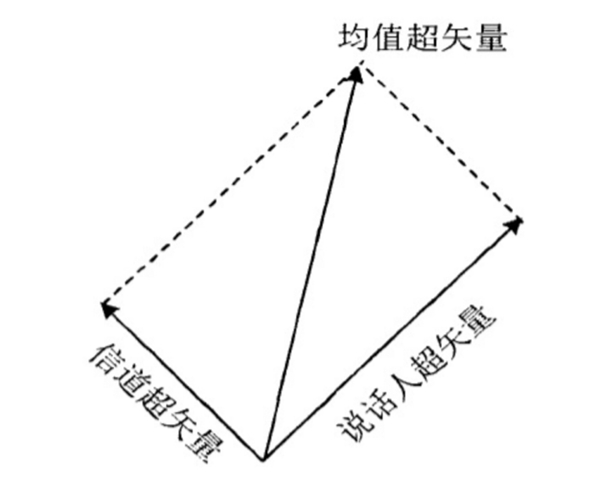
图五 均值超矢量
如上图所示,联合因子分析实际上是用GMM超矢量空间的子空间对说话人差异及信道差异进行建模,从而可以去除信道的干扰,得到对说话人身份更精确的描述。
JFA定义公式如下:
s = m + Vy + dZ
c = Ux
其中,s为说话人相关的超矢量,表示说话人之间的差异;m为与说话人以及信道无关的均值超矢量;V为低秩的本征音矩阵;y为说话人相关因子;D为对角的残差矩阵;z为残差因子;c为信道相关的超矢量,表示同一个说话人不同语音段的差异;U为本征信道矩阵;x为与特定说话人的某一段语音相关的因子。这里的超参数集合{V,D,U}即为需要评估的模型参数。有了上面的定义公式,我们可以将均值超矢量重新改写为如下形式:
M = m + Vy + Ux + Dz
为了得到JFA模型的超参数,我们可以使用EM算法训练出UBM模型,使用UBM模型提取Baum-Welch统计量。
尽管JFA对于特征音空间与特征信道空间的独立假设看似合理,但绝对的独立同分布的假设是一个过于强的假设,这种独立同分布的假设往往为数学的推导提供了便利,却限制了模型的泛化能力。
4. 基于GMM的i-vector方法及PLDA
特点:统一建模所有空间,进一步减少注册和识别所需语音时长,使用PLDA分辨说话人特征,但噪声对GMM仍然有很大影响。
N.Dehak提出了一个更加宽松的假设:既然声纹信息与信道信息不能做到完全独立,那就用一个超向量子空间对两种信息同时建模。即用一个子空间同时描述说话人信息和信道信息。这时候,同一个说话人,不管怎么采集语音,采集了多少段语音,在这个子空间上的映射坐标都会有差异,这也更符合实际的情况。这个既模拟说话人差异性又模拟信道差异性的空间称为全因子空间(Total Factor Matrix),每段语音在这个空间上的映射坐标称作身份向量(IdentityVector, i-vector),i-vector向量通常维度也不会太高,一般在400-600左右。
i-vector方法采用一个空间来代替这两个空间,这个新的空间可以成为全局差异空间,它既包含了说话人之间的差异又包含了信道间的差异。所以i-vector的建模过程在GMM均值超矢量中不严格区分说话人的影响和信道的影响。这一建模方法动机来源于Dehak的又一研究:JFA建模后的信道因子不仅包含了信道效应也夹杂着说话人的信息。
i-vector中Total Variability的做法(M = m + Tw),将JFA复杂的训练过程以及对语料的复杂要求,瞬间降到了极致,尤其是将Length-Variable Speech映射到了一个fixed- andlow-dimension的vector(IdentityVector,即i-vector)上。于是,所有机器学习的算法都可以用来解决声纹识别的问题了。
现在,主要用的特征是i-vector。这是通过高斯超向量基于因子分析而得到的。是基于单一空间的跨信道算法,该空间既包含了说话人空间的信息也包含了信道空间信息,相当于用因子分析方法将语音从高位空间投影到低维。
可以把i-vector看作是一种特征,也可以看作是简单的模型。最后,在测试阶段,我们只要计算测试语音i-vector和模型的i-vector之间的consine距离,就可以作为最后的得分。这种方法也通常被作为基于i-vector说话人识别系统的基线系统。
i-vector简洁的背后是它舍弃了太多的东西,其中就包括了文本差异性,在文本无关识别中,由于注册和训练的语音在内容上的差异性比较大,因此我们需要抑制这种差异性。但在文本相关识别中,我们又需要放大训练和识别语音在内容上的相似性,这时候牵一发而动全身的i-vector就显得不是那么合适了。虽然i-vector在文本无关声纹识别上表现非常好,但在看似更简单的文本相关声纹识别任务上,i-vector表现得却并不比传统的GMM-UBM框架更好。
i-vector的出现使得说话人识别的研究一下子简化抽象为了一个数值分析与数据分析的问题:任意的一段音频,不管长度怎样,内容如何,最后都会被映射为一段低维度的定长i-vector。只需要找到一些优化手段与测量方法,在海量数据中能够将同一个说话人的几段i-vector尽可能分类得近一些,将不同说话人的i-vector尽可能分得远一些。并且Dehak在实验中还发现i-vector具有良好的空间方向区分性,即便上SVM做区分,也只需要选择一个简单的余弦核就能实现非常好的区分性。
i-vector在大多数情况下仍然是文本无关声纹识别中表现性能最好的建模框架,学者们后续的改进都是基于对i-vector进行优化,包括线性区分分析(Linear DiscriminantAnalysis,LDA),基于概率的线性预测区分分析(Probabilisticlinear Discriminant Analysis,PLDA)甚至是度量学习(Metric Learning)等。
概率线性判别分析(PLDA)是一种信道补偿算法,被用于对i-vector进行建模、分类,实验证明其效果最好。因为i-vector中,既包含说话人的信息,也包含信道信息,而我们只关心说话人信息,所以才需要做信道补偿。我们假设训练数据语音由 i 个说话人的语音组成,其中每个说话人有 j 段自己不同的语音。那么,我们定义第 i 个人的第 j 条语音为 Xij 。根据因子分析,我们定义 Xij 的生成模型为:

如上公式中,n1和n2分别是两个语音的i-vector矢量,这两条语音来自同一空间的假设为Hs,来自不同的空间的假设为Hd。
其中p(n1, n2 | hs)为两条语音来自同一空间的似然函数;p(n1 | hd),p(n2 | hd)分别为n1和n2来自不同空间的似然函数。通过计算对数似然比,就能衡量两条语音的相似程度。
比值越高,得分越高,两条语音属于同一说话人的可能性越大;比值越低,得分越低,则两条语音属于同一说话人的可能性越小。
三、基于深度神经网络的技术框架
随着深度神经网络技术的迅速发展,声纹识别技术也逐渐采用了基于深度神经网络的技术框架,目前有DNN-iVector-PLDA和最新的End-2-End。
1. 基于深度神经网络(DNN)的方法(D-Vector)
特点:DNN可以从大量样本中学习到高度抽象的音素特征,同时它具有很强的抗噪能力,可以排除噪声对声纹识别的干扰。
在论文《Deep Neural Networks for SmallFootprint Text-Dependent Speaker Verification》中,作者对DNN在声纹识别中的应用做了研究。
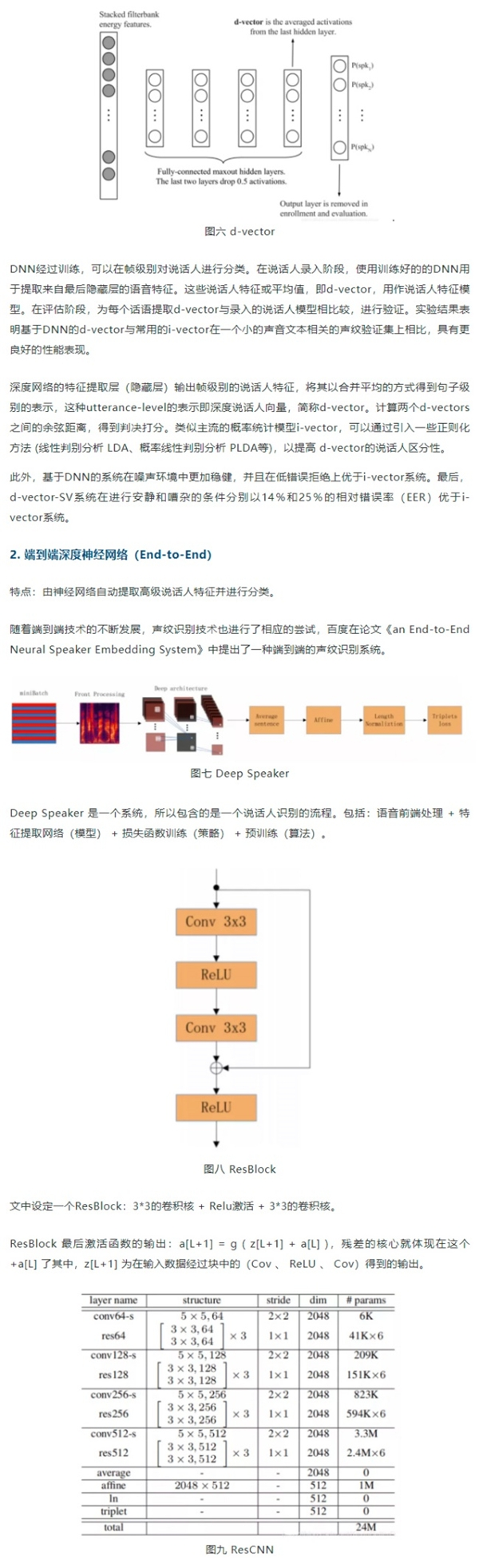
conv64-s:单纯的卷积层。
卷积核尺寸为5*5(卷积核实际上是5*5*c,其中c为输入数据的通道数);个数为64,也就代表着输出数据的第三维了;步长为2*2,会改变数据维度的前2维,也就是高和宽。
res64:是一个ResBlock(残差块),并不是一层网络,实际层数是这个ResBlock中包含的层数,这里残差块中包含2个卷积层:卷积核尺寸3*3;个数64;步长为1*1(也就是上文的 Cov+ReLU+Cov,也就是2层,中间激活不算)。后面的乘3是指有三个ResBlock。所以说这个res64部分是指经过3个ResBlock,而且每一个ResBlock中包含2个卷积层,其实是6层网络。
Average层,本来数据是三维的,分别代表(时间帧数 * 每帧特征维度 * 通道数),通道数也就是经过不同方式提取的每帧的特征(Fbank或MFCC这种)。将时间平均,这样一段语音就对应一段特征了,而不是每一帧都对应一段特征。
Affine层:仿射层,就是将维度2048的特征变为512维。
ln层(length normalization layer):标准化层,特征标准化之后,得到的向量来表示说话者语音。
关于dim 维度这一列,开始时输入语音数据是三维:(时间帧数 * 每帧特征维度 * 通道数)。本文中,时间帧数根据语音长度可变,每帧特征维度为64,通道数为3(代表Fbank、一阶、二阶)。所以输入维度:时间帧数 * 64 * 3。经过第一层conv64-s后:因为卷积层步长2*2,所以时间帧数 和每帧特征维度都减半了,特征维度变为了32,通道数变为了卷积核个数64。32*64=2048,也就是dim的值。所以,这里的dim维度指的是除去时间维的频率特征维度。
训练的时候,使用Triplet loss作为损失函数。通过随机梯度下降,使得来自同一个人的向量相似度尽可能大,不是同一个说话者的向量相似度尽可能小。

总结
从声纹识别技术发展综述中,我们不难看出,声纹识别的研究趋势正在快速朝着深度学习和端到端方向发展,其中最典型的就是基于句子层面的做法。在网络结构设计、数据增强、损失函数设计等方面还有很多的工作去做,还有很大的提升空间,此外,声纹识别系统在保持高性能的情况下对语音长度的需求在不断减小。
声纹识别是百分点科技一直关注和研究的技术领域之一。目前,百分点科技的声纹识别系统使用大规模数据训练,准确度可达95%以上,1:N支持万级以上声纹库建设,在国内数字政府、公共安全等多个领域已有实际项目落地。未来,我们将继续朝着声纹识别技术的深度学习方向进行重点研究。
相关文章
- 百分点科技+DeepSeek:重塑数据治理新范式 AI赋能数据价值释放
- 中非合作论坛期间百分点科技与刚果(金)签署谅解备忘录
- 百分点科技在共建“一带一路”中的实践
- 百分点科技&IDC联合发布数据科学基础平台白皮书
- 聚焦数智化转型 百分点科技2023数据科学峰会即将举办
- 百分点科技联合召开《中国应急管理发展报告(2022)》新书发布会
- 百分点科技荣获“上合国家软件产业国际合作优秀案例奖”
- 百分点科技数据科学产教融合计划继续扩大招募
- IDC发布中国智慧应急报告 大数据与人工智能市场百分点科技第二
- 2022年消费维权重点曝光行业有哪些 百分点科技联合数据猿发布预测报告
- 百分点科技:基于计算机视觉的语义分割技术如何在水域监控上发挥作用
- 百分点科技:声纹识别技术发展及未来趋势研究
- 百分点科技:基于NL2SQL的问答技术与实践
- 百分点科技:公众环境满意度与环境质量的关联分析研究
- 百分点科技:基于HugeGraph的知识图谱技术在白酒行业的落地实践
- 百分点科技发布“新一代数据智能决策系统DeepMatrix 3.0”
AI企业
更多>>





AI硬件
更多>>AI产业
更多>>AI技术
更多>>- 全球最强开源模型 Kimi K3 发布,参数规模 3 万亿,真的是强!
- 范式变革!东软发布AI原生软件工程白皮书,重构软件产业底层逻辑
- KAT-Coder-Pro V2.5正式发布:从“写代码”迈向“做工程”,Agentic能力全面升级
- 自变量机器人王昊:训练世界模型需付出“时间税”,解决模态对齐是当务之急
- 腾讯发布CodeBuddy Security,用AI Agent实现更高效的代码审计
- Twinkle x昇腾,率先实现Deepseek-V4系列模型高效训练
- 高德发布鸿蒙首个生成式 UI 开源框架 AGenUI,告别传统 UI 开发模式
- 发布即适配| 天数智芯全力支持腾讯混元Hy3 preview 开源落地,共推国内大模型产业普惠


